







数据库是一个项目运行的基石,数据库设计以及应用的不合理可能影响到我们项目的运行。
数据库优化的目的
避免出现页面访问错误:1.由于数据库连接timeout产生页面5XX错误;2.由于慢查询导致页面无法加载;3.由于并发等原因造成的阻塞导致数据无法提交。
增加数据库的稳定性:大部分是由于低效的查询引起的
优化用户体验:为了提高页面的访问速度和良好的网站功能体验
数据库优化的途径:
(1)sql优化和索引优化:这是数据库最有效的数据库优化方式
(2)数据库表结构:一个好的数据表结构是sql优化的前提,尽量满足范式,减少冗余
(3)系统配置:myql数据库是基于文件的,数据库操作实际上也是对文件的操作,所以它受文件打开数以及io的限制,因此系统配置也是至关重要的
(4)硬件:更适合数据库的cpu、更大的内存以及更快的io速度
由于mysql内部的锁机制(保证数据库完整性的机制),所以上述优化中,硬件的优化成本最高,但是效果最差。
一、sql优化及索引
1.慢查询日志:对有效率问题的sql语句进行监视
show varitiables like 'slow_query_log' //显示慢查询日志的相关状态
set global slow_query_log_file='path' //设置慢查询日志的存储位置
set global slow_queries_not_using_indexes=on //设置记录没有使用的索引的查询
set global slow_query_time=1 //设置记录慢查询的超时时间
日志存储格式:
执行sql的主机信息:#User@Host:root[root] @localhost[]
sql的执行信息:Query_time(查询时间)、Lock_time(慢查询设置的超时时间)、Rows_send(返回的行数)、Rows_examined(扫描行数)
sql执行时间:以时间戳格式记录
sql的内容:执行的sql语句
2.mysql慢查询分析工具:mysqldumpslow和pt_query_digest,这两种工具的使用在网上有很多教程,可以自己去找找。
3.使用explain+sql分析sql语句的执行计划

返回的结果列含义:
table:显示这一行的数据是那张表的
type:这是重要的列,显示连接使用了那种类型。好到差的连接类型依次为:const(一般对唯一索引和主键的查找)、eq_reg(范围查找)、ref(连接查询,一张表是基于一个索引的查找)、range(基于索引的范围查找)、index(索引的扫描查找)、all(表扫描)
possible_keys:显示可能应用在这张表中的索引
key:实际使用的索引
key_len:使用索引的长度
ref:显示索引的那一列被使用了,如何可能的话是一个常数
rows:mysql认为必须检查的用来返回请求结果的行数
extra:如果返回结果中出现 Using filesort和Using temporary的话,说明查询需要优化了
4.优化max()和count()
优化max():对max()方法的作用列建立索引
优化count():count(*)和count('某一列')的区别,当使用count('某一列')时,当记录行中出现null时,结果将不会包含这条记录。在count()使用过程中多使用as关键字
5.子查询的优化:通常情况下将子查询优化为join查询
例:将select * from tl1 where id in (select id from tl2) 优化为:select * from tl1 join tl2 on tl1.id=tl2.id
当tl1与tl2中出现一对多情况时,为了避免重复,应该使用disdinct去重
6.limit优化:limit通常结合order by一起使用,在优化过程中,(1)建议使用有索引的列或主键进行order by 操作;(2)记录上次返回的主键,在下次查询时使用主键过滤
比如在分页查询中,在进行第二次查询时,我们可以在查询之前加一个where进行主键列记录筛选,这样做可以避免数据量大时扫描过多记录
二、索引优化
选择合适的列建立索引:
1.在where从句,group by从句,on从句中出现的列
2.索引字段越小越好(数据库中数据是以页为存放单位的,字段越小,每页存储数据量就大,效率就高)
3.离散度大的列放在联合索引的前面(利用count()统计列的唯一值,唯一值越多,离散度就越大)
索引的维护及优化---冗余重复索引
重复索引:相同的列以同样的顺序建立的索引
冗余索引:多个索引的前缀列相同,或是在联合索引下包含了主键的索引
可以使用pt-duplicate-key-checker工具检查重复或冗余索引
三、数据库结构优化
选择合适的数据类型:
1.使用可以存储你数据的最小的数据类型
2.使用简单的数据类型。int要比varchar在mysql处理上更简单
3.尽可能是同not null 定义字段(非not null字段需要额外的字段开存储,增加了io和存储的开销)
4.尽量少使用text等大的数据类型,如果一定使用的话,可以附加一张表存储
例1:使用int类型来存储日期时间:INSERT INTO test(time) VALUES(UNIX_TIMESTAMP()); SELECT FROM_UNIXTIME(time) FROM test;
UNIX_TIMESTAMP()函数:将日期格式转为int类型的时间戳格式
FROM_UNIXTIME()函数:将时间戳格式转为日期格式
例2:使用bigint来存储ip地址:INSERT INTO test(ipaddress) VALUES(INET_ATON('192.168.0.1')); SELECT INET_NTOA(ipaddress) FROM test;
INET_ATON()函数:从ip地址到整型的转换
INET_NTOA()函数:从整型到ip地址的转换
范式优化:
数据库结构的范式化一般是遵循第三范式即可,即要求数据表中不存在非关键字对任意候选关键字段的传递函数依赖。

在这个数据表中,商品名称->分类->商品描述,而商品名称是关键字,分类描述是非关键字,因此存在“非关键字”对“关键字”的依赖关系,它不满足第三范式
这种设计造成数据的冗余,将会造成插入异常、删除异常以及更新异常,正确的操作我们应该拆分这个数据表
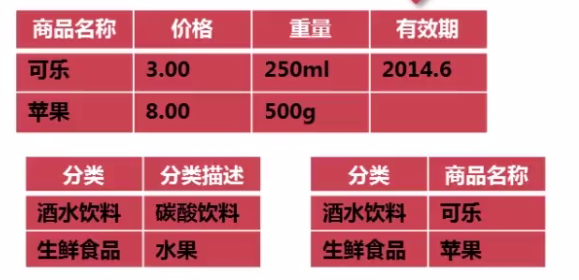
反范式化:在一些实际项目中,为了提高查询效率,我们需要在符合第三范式的表上面适当的增加冗余,这是一种以空间来换取时间的操作
表的垂直拆分:1.把不常用的一些字段单独存放在一个表中
2.把大字段独立放在一个表中
3.把经常一起使用的字段放在一起
表的水平拆分:解决单表的数据量过大的问题。方法:对表中id进行hash计算,如果要拆分成5个表使用,mod(id,5)取出0.1.2.3.4,正对不同的hashID把数据存到不同的表中















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









