







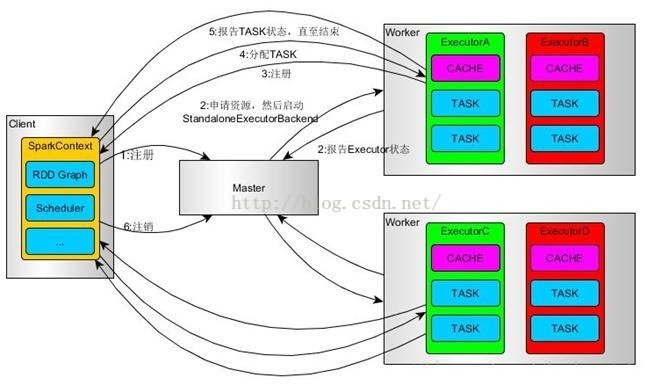
一、Standalone模式
1、使用SparkSubmit提交任务的时候(包括Eclipse或者其它开发工具使用new SparkConf()来运行任务的时候),Driver运行在Client;使用SparkShell提交的任务的时候,Driver是运行在Master上
2、使用SparkSubmit提交任务的时候,使用本地的Client类的main函数来创建sparkcontext并初始化它;
3、SparkContext连接到Master,注册并申请资源(内核和内存)。
4、Master根据SC提出的申请,根据worker的心跳报告,来决定到底在那个worker上启动StandaloneExecutorBackend(executor)
5、executor向SC注册
6、SC将应用分配给executor,
7、SC解析应用,创建DAG图,提交给DAGScheduler进行分解成stage(当出发action操作的时候,就会产生job,每个job中包含一个或者多个stage,stage一般在获取外部数据或者shuffle之前产生)。然后stage(又称为Task Set)被发送到TaskScheduler。TaskScheduler负责将stage中的task分配到相应的worker上,并由executor来执行
8、executor创建Executor线程池,开始执行task,并向SC汇报
9、所有的task执行完成之后,SC向Master注销
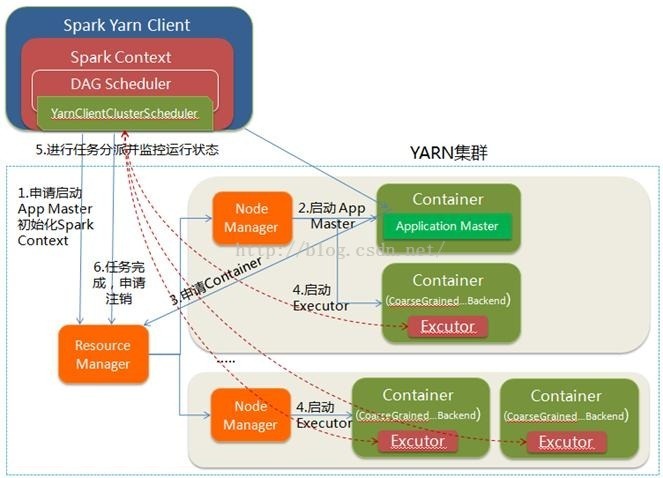
二、yarn client
1、spark-submit脚本提交,Driver在客户端本地运行;
2、Client向RM申请启动AM,同时在SC(client上)中创建DAGScheduler和TaskScheduler。
3、RM收到请求之后,查询NM并选择其中一个,分配container,并在container中开启AM
4、client中的SC初始化完成之后,与AM进行通信,向RM注册,根据任务信息向RM申请资源
5、AM申请到资源之后,与AM进行通信,要求在它申请的container中开启CoarseGrainedExecutorBackend(executor)。Executor在启动之后会向SC注册并申请task
6、SC分配task给executor,executor执行任务并向Driver(运行在client之上的)汇报,以便客户端可以随时监控任务的运行状态
7、任务运行完成之后,client的SC向RM注销自己并关闭自己
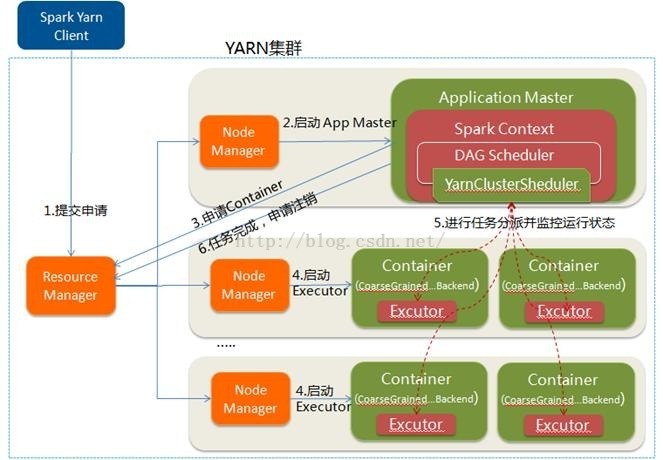
三、yarn cluster
1、spark-submit脚本提交,向yarn(RM)中提交ApplicationMaster程序、AM启动的命令和需要在Executor中运行的程序等
2、RM收到请求之后,选择一个NM,在其上开启一个container,在container中开启AM,并在AM中完成SC的初始化
3、SC向RM注册并请求资源,这样用户可以在RM中查看任务的运行情况。RM根据请求采用轮询的方式和RPC协议向各个NM申请资源并监控任务的运行状况直到结束
4、AM申请到资源之后,与对应的NM进行通信,要求在其上获取到的Container中开启CoarseGrainedExecutorBackend(executor),executor 开启之后,向AM中的SC注册并申请task
5、AM中的SC分配task给executor,executor运行task兵向AM中的SC汇报自己的状态和进度
6、应用程序完成之后(各个task都完成之后),AM向RM申请注销自己兵关闭自己














 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









