







Structured Streaming整合kafka
Spark2.0以后开始推出Structured Streaming,详情参考上文Spark2.0 Structured Streaming。本文介绍一种常用的方式: Structured Streaming读取kafka数据,并使用spark sql过滤,最终输出到终端。
本示例能够读取多个topic数据,并分别映射为Spark内存表,执行多个sql。
1.环境
(1)版本
Spark版本:spark-2.2.0
Scala版本:scala-2.11.4
Kafka版本:kafka 0.10 or higher
(2)数据
Kafka topic:dyl_test01
数据内容:{"a":"1","b":"2","c":"2018-01-08","d":[23.9,45]}
2.基本介绍
2.1 Linking
使用maven/SBT的项目,需要引用如下的库文件:
groupId = org.apache.spark artifactId = spark-sql-kafka-0-10_2.11 version = 2.2.1 |
其他jar
| <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> <scope>${scope}</scope> </dependency> <dependency> <dependency> </dependency> <dependency> </dependency> |
2.2 Reading Data from Kafka
(1)直接从Kafka读取数据,并且进行查询:
// Subscribe to 1 topic val df= spark .readStream .format("kafka") .option("kafka.bootstrap.servers","host1:port1,host2:port2") .option("subscribe","topic1") .load() df.selectExpr("CAST(key AS STRING)","CAST(value AS STRING)") .as[(String,String)] // Subscribe to multiple topics val df= spark .readStream .format("kafka") .option("kafka.bootstrap.servers","host1:port1,host2:port2") .option("subscribe","topic1,topic2") .load() df.selectExpr("CAST(key AS STRING)","CAST(value AS STRING)") .as[(String,String)] // Subscribe to a pattern val df= spark .readStream .format("kafka") .option("kafka.bootstrap.servers","host1:port1,host2:port2") .option("subscribePattern","topic.*") .load() df.selectExpr("CAST(key AS STRING)","CAST(value AS STRING)") .as[(String,String)] |
这个没什么说的,简单的设置kafka集群参数以及topic,然后进行查询,df.selectExpr中能够使用sql里的语法,df.select里只能设置选择的字段。设置多个kafka topic时,可以逗号分割,或者正则匹配,这时候,所有topic的数据都会写入到一张表中,很多时候,不同topic更想映射到不同的表中,稍后说明。先来看看直接读取Kafka数据并输出时,结果如何,如下图2.1所示:
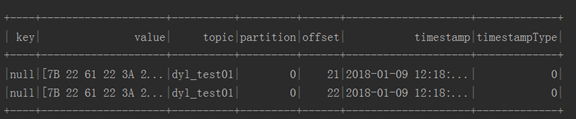
图2.1 直接读取kafka数据输出
如上图2.1,是没有执行selectExpr("CAST(value AS STRING)"的结果,value是字节数组,所以,执行CAST的作用是将value转换为字符串,结果如下2.2所示:
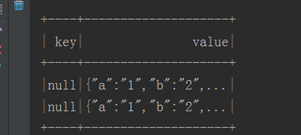
图2.2 value转为字符串
此时,selectExpr中只选择了key和value,所以结果中也只有key和value字段。读取kafka时,默认并不会解析kafka的数据内容,而是直接将kafka数据放到value列中显示出来,关于其他几个字段如下表2.1所示:
表2.1 默认内存表schema
Column | Type |
key | binary |
value | binary |
topic | string |
partition | int |
offset | long |
timestamp | long |
timestampType | int |
关于Kafka source的详细配置,可以参考官网:Kafka Integration Guide (Kafka broker version 0.10.0 or higher)。这里不多介绍,kafka的数据被写入value,其实对用户而言,并没有什么用,除非使用正则去匹配value的内容,我们更想解析value的内容,将value的内容映射为一张表,如上,value内容是JSON格式数据,解析方式也很简单,使用from_json函数即可,这里有个例子可以参考:kafka-spark-structured-streaming-example,主要内容如下所示:
|
首先,将value字段转换为字符串,重名了为"json",然后使用from_json函数,应用预定义的schema,解析json数据,将结果重命名为"data",接下来就可以直接使用json中的字段了。
这里有一个比较纠结的地方,必须预定义json的格式,而不是像spark Streaming一样,提供了自动推测json格式的功能,让我一度觉得Structured Streaming太局限,不实用,经过查证以及思考,觉悟这原来是一个优化,json格式自动推测的前提是遍历所有数据,收集信息才能正确推测json的字段和字段类型,这无疑是很慢的,也很消耗资源,实际上,json格式字段事先基本上都是能够知道的,发生更改的情况很少,但是,还是有可能发生的,目前,我没找到如何动态更改json schema的方式,提供了Schema之后,spark生成的任务计划中已经写死了json数据解析的字段名和字段类型,当查询任务start之后,则使用该任务计划解析数据,并没有提供修改scheme的接口,但是通过查看源码,发现有个RuntimeReplaceable Expression,例子是spark的nvl函数,好像可以运行时更改选择列的表达式,没细看,知道的朋友交流一下,也因此,实际中并没有使用Structured Steamming,因为项目中需要修改json的解析方式。
经过from_json解析之后,结果如下图2.3所示:
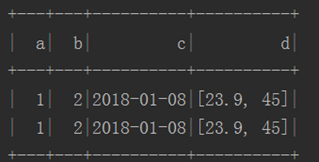
图2.3 from_json解析数据
完整代码如下:
|














 256
256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









