




原文链接:https://doupoa.site/archives/877
0.前言
这个问题主要是针对某个tx系产品做Playwright自动化时,网页样式和JS指向的CDN地址死活加载不出来。同样的该系列的其他网站也是因为CDN无法加载导致网站无法进入。多次测试后发现就是tx那边的CDN把我们的IP给封了。
那怎么办?IP被封业务还是要继续下去的。于是自己想了两个方案,一个是用云端服务器做代理,专门代理和缓存无法加载的CDN文件。但是这样就要经常去云端调整缓存方案,还要写一个服务端。实属有点麻烦,而且服务器那小水管…一个文件上传就把业务接口堵了
后来又想了个办法,既然不能从云端获取,那能不能做一个中间件判断加载慢的文件,在开发期间将所有加载慢的文件存到本地并稍微处理下?后面一试,嘿还真好用,平时转半天圈的网页直接秒开。
1.前期准备
我们需要整理一个需要代理的资源名单,因为目前连网站都进不去何谈访问。虽然后面已经实现了全自动的计时、缓存以及读取的流程,您也可以看看是我如何逐渐解决问题的。
以我的网站为例子,打开开发者工具,在网络选项卡中选中禁用缓存和慢速4G开关,以模拟在Playwright首次访问网站和网站加载过慢的情况。
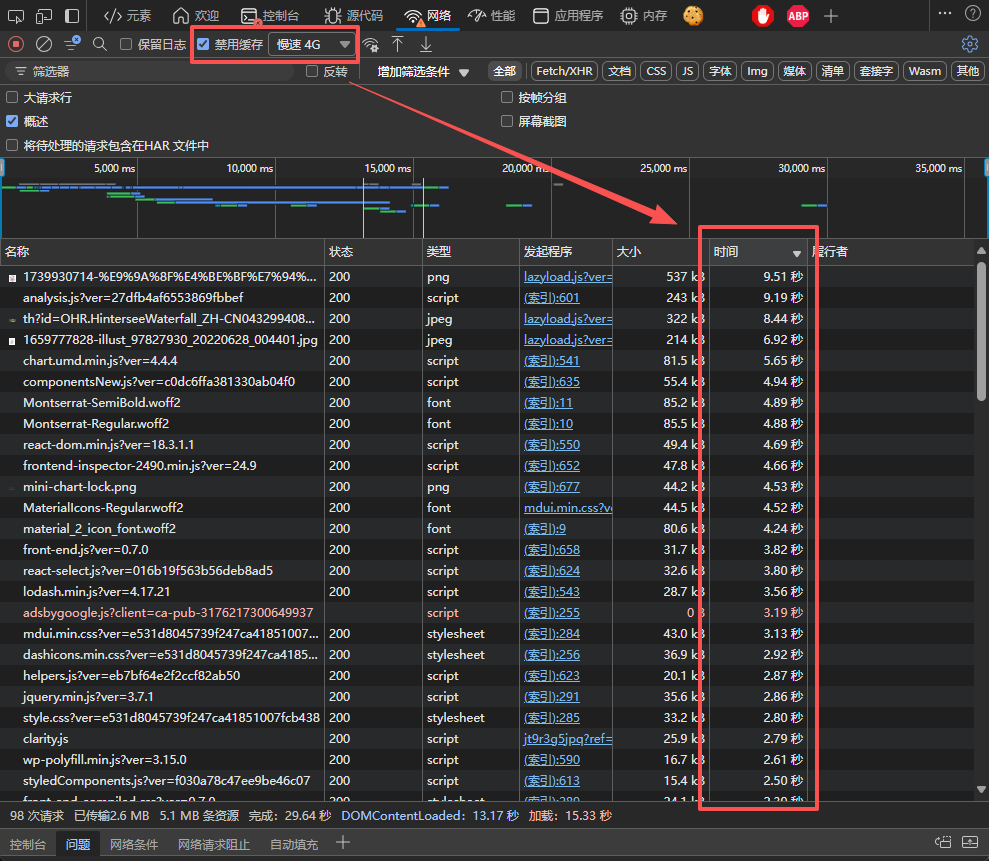
可以发现有很多资源加载超过1秒,网络日志记录器也为我们记录了所有资源的请求时长。那我们怎么保存这些数据?
在顶部有一个下载的按钮,我们可以将这些请求日志以HAR的形式保存下来
打开文件后可以看到这实际就是一个JSON文件,分为三个结构,log存储日志版本、创建者的相关信息,pages存储所访问网页的域名以及整体网站的加载时间。剩下的entries就是实际请求资源的基本信息。
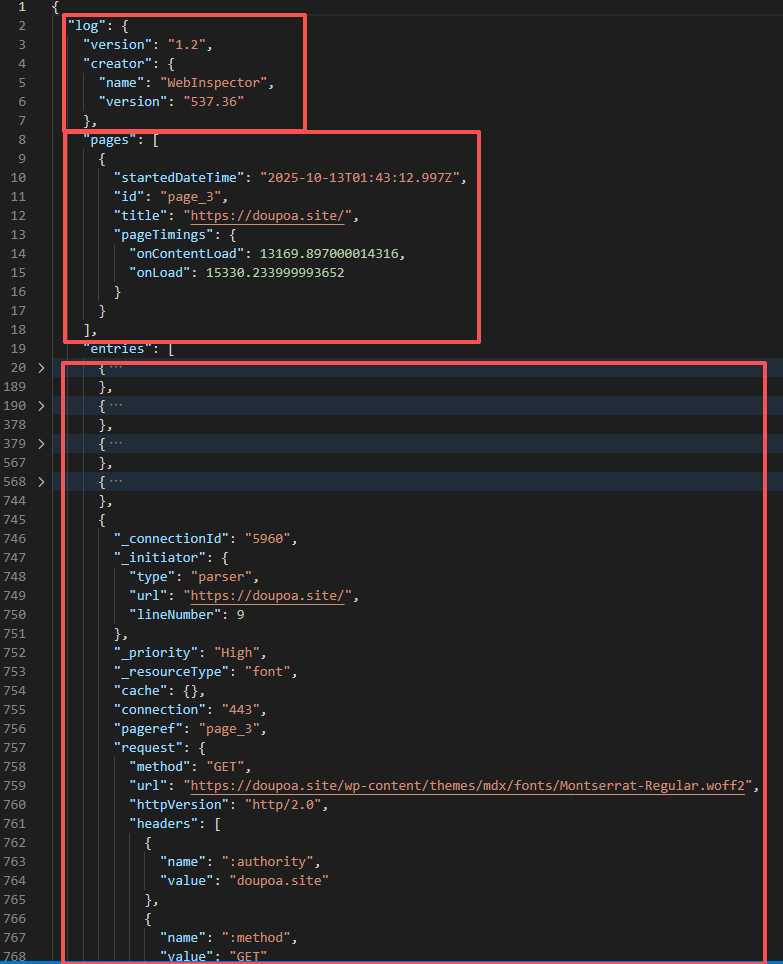
这样我们可以通过解析这个文件来提取加载时间大于1000毫秒的资源地址和文件名称,可通过以下脚本实现:
import json
# 手动执行工具类,用于处理从开发者工具捕获的日志文件
data = json.load(open("doupoa.site.har","r",encoding="utf-8"))
reports_list = []
reports_map = {}
for entries in data["log"]["entries"]:
filename = entries["request"]["url"].split("?")[0].split("/")[-1]
if entries["time"] < 1000 or filename.split(".")[-1] not in ["css","js","ot 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









