







http://blog.csdn.net/dahaifeiyu/article/details/6655652
最近也觉得应该仔细的看一下Hadoop的源代码了,以前只是懂得基本的架构了使用,最近在做一个系统,觉得很多东西可以借鉴MapReduce的可扩展性。但是当我们的系统的0.1版本出现的时候才发现我们的配置上很混乱。于是我自己的看了一下Hadoop的Configuration类,真的觉得Hadoop的配置是值得借鉴的,学到了很多!下面是Configuration类的属性清单:

Log是记录日志的对象。quietmode对应的是配置信息加载过程中是否属于静默的模式,如果处于静默的模式下,则在配置信息加载的过程中的一些信息不会被记录在日志中,默认情况是设置为true的。resources是一个对象数组,用于存放有关包含配置信息的对象。finalParameter是所有配置值被声明为final的变量的一个集合。loadDefault从表面字段上可以理解为是否要加载默认的配置。REGISTRY是一个WeakHashMap,用于多有个对象的相关配置的注册对它们进行管理,弱哈希可以自动清除不在正常使用的键对应的条目。defaultResources是一个CopyOnWrite的字符串数组,用于存储默认的配置资源名或者路径。{…}是一个静态初始化块,用于加载默认的配置资源。properties存储的是Configuration对象中的全部配置信息,它的类型是Properties的,这个类型是Java提供的对KV配置的一个属性集,提高了对KV配置参数的存储和操作方法。overlay则是进行覆盖的属性。classLoader主要是用于配置冲根据配置的参数构造相应的对象实例时提供上下文环境的类加载器。varPat是一个对含有环境变量的值的进行转换的正则表达式对象,比如我们设定的一个路径变量的值为$HOME/data,那么这个变量就会以一定的规则把该变量的值分为字串$HOME和/data,之后会把$HOME解析成系统上的家目录了。MAX_SUBST是设定对带有环境变量的值所能够深入解析的层次数,超出这个最大的层数的值将不能够解析。
下面具体的说一下各个方法的情况。Configuration类的方法按照访问控制来分有两类,就是private和public,其中private主要是public方法的一些工具。其中:
构造方法三个:

第二个是可以指定是否加载默认设置,默认为true,第三个是用一个configuration对象构造一个新的configuration对象。
下面是几个添加配置资源的方法:

分别是添加默认的或者指定的各种来源的配置资源,而reloadConfiguration()则是一个清除所有原有配置信息,以便于重新加载配置信息的方法,这可以在值的覆盖中或者用新的配置资源覆盖之前的配置资源的时候用到。
下面主要是获取一些配置信息的set或者get方法和其他方法:
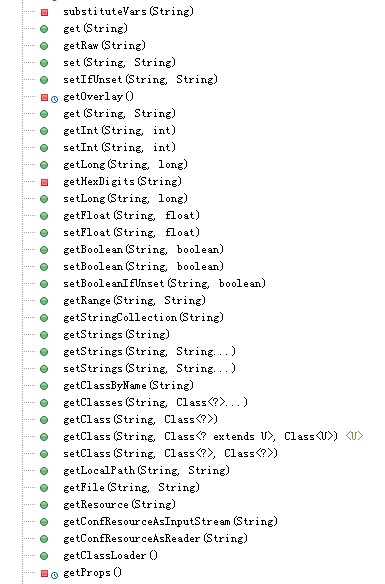

substituteVars(String)方法就是配合上面的正则表达式对象对含有环境变量的参数值进行解析的方法。后面的set和get方法主要是获取各种参数值的方法,它的主要机制是通过getPros()调用loadResources(Properties,ArrayList,boolean)方法再调用loadResource(Properties,Object,boolean)加载配置资源中的配置信息,而set(String,String)和get(String)的方法中会调用getPros()方法获取当前Configuration对象的properties对象,如果该对象为空,则调用loadResources(Properties,ArrayList,boolean)方法加载配置信息,之后的其他get和set方法都是通过调用get(String)和set (String,String)方法来实现对配置信息的操作的。最后几个方法分别是size()方法是获取配置信息大小的,clear()方法是用于清除配置信息的,IntegerRanges是一个关于整型数范围的内部类,iterator()是配置对象的一个迭代器,最后的readFields(DataInput)方法和write(DataOutput)方法则是因为Configuration类实现了Writable接口的实现方法,这样Configuration类就可以在集群中进行分发,使得同一个作业的所有节点上的配置信息都完全相同。
这就是Hadoop的配置信息的核心类,从这里可以看出一个大型的分布式系统中该如何去提供一个有价值的配置,来实现系统的可用和满足业务的灵活性。我总结有一下几点:
1. 需要提供各种的set和get方法,方便获取各种的配置参数值,比如上面的大量的set和get方法以及它们的实现逻辑。
2. 适当的集合垃圾回收机制和线程同步问题采用合理的存储数据结构,比如这里用到的弱哈希和CopyOnWriteArrayList,还有在对Configuration.class进行的加锁
3. 分布式系统中的配置一定要实现序列化,这样才能在集群中保持配置信息的一致性,使得配置信息可以从流中来到留中去。
4. 一个分布式系统的配置方法应该是至少分为3层的,第一层就是默认的,也是全局的静态配置,第二层是可以针对每个作业可以定制的参数,这个是用Configuration中的set方法即可做到,第三层就是通过命令行的方式为一次的作业进程组定制配置参数。这三层的作用域不同,他们的作用域依次是全局系统、一个作业程序、一次作业运行的进程组,每一次都可以覆盖前一层的参数值。
在这里我觉得对于Hadoop的配置参数过多,通过set方法设置需要知道相应的参数名字,这是很不方便的,但是也满足了灵活性,用户可以自己定制配置参数。也可以提供一个枚举类对相应的参数给予描述,用起来会更方便一些。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









