1.简介
该索引是利用Lucene的任何组件的核心。就像书籍的索引一样,它组织所有数据,以便可以快速访问。索引由包含一个或多个字段的文档组成。文档和字段可以代表我们选择的任何内容,但一个常见的隐喻是:文档表示数据库表中的条目,而字段类似于表中的字段。
2.了解索引操作
让我们看一下Lucene搜索索引的图形表示。
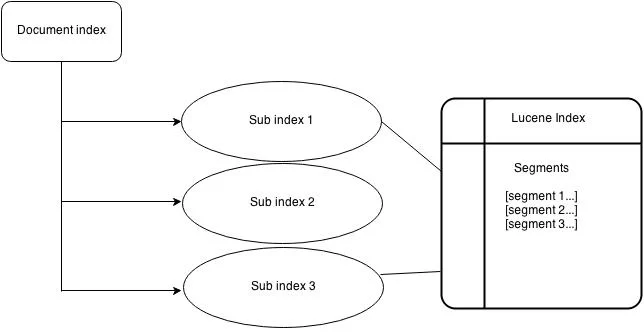
图1
简而言之,当Lucene对文档进行索引时,它会将其分解为许多术语。然后,它将术语存储在索引文件中,其中每个术语与包含该术语的文档相关联。我们可以把它当作一个哈希表。术语是使用分析器生成的,该分析器将每个单词的词根都提取出来。发出查询时,将通过用于构建索引的同一分析器对该查询进行处理,然后使用该分析器在索引中查找匹配项。这提供了与查询匹配的文档列表。
现在,让我们看一下整个Lucene搜索过程。
基本概念是索引,文档,字段和术语。
- 索引包含文档的集合。
- 文档是字段的集合。
- 字段是术语的集合。
- 术语是成对的字符串<field,term-string>。
2.1倒排索引
索引存储有关术语的统计信息,以使基于术语的搜索更加高效。Lucene的索引属于称为反向索引的索引族。这是因为它可以长期列出包含它的文档。这与文档中列出术语的自然关系相反。
2.2字段类型
在Lucene中,可以存储字段,在这种情况下,它们的文本按原样存储在索引中,并且是不可逆的。反转的字段称为索引。字段可以被存储和被索引。
可以将字段的文本标记为要索引的术语,或者可以将字段的文本从字面上用作要索引的术语。大多数字段都是标记化的,但有时对于某些标识符字段按字面意义进行索引很有用。
2.3细分
Lucene索引可以由多个子索引或段组成。每个段都是完全独立的索引,可以分别进行搜索。索引按以下方式演变:
- 为新添加的文档创建新的细分。
- 合并现有的细分。
- 搜索可能涉及多个段和/或多个索引,每个索引可能由一组段组成。
2.4文件编号
在内部,Lucene通过整数文档号引用文档。添加到索引的第一个文档编号为零,并且随后添加的每个文档的编号都比前一个大。
请注意,文档编号可能会更改,因此在将这些编号存储在Lucene之外时应格外小心。特别是,在以下情况下数字可能会更改:
存储在每个段中的数字仅在该段内是唯一的,并且必须进行转换才能在更大的上下文中使用它们。标准技术是根据该段中使用的数字范围为每个段分配一个值范围。要将文档编号从段转换为外部值,需要添加段的基本文档编号。要将外部值转换回特定于细分的值,可以通过外部值所在的范围来标识细分,然后减去细分的基值。例如,可以合并两个五个文档的段,以便第一个段的基值为零,第二个为五个。第二段的文档三的外部值为8。
删除文档后,在编号中会留出空白。随着索引通过合并的发展,这些最终被删除。合并段时删除已删除的文档。因此,新合并的段在编号上没有间隙。
2.5搜索索引
搜索索引由javascript函数定义。它以类似于视图的地图功能的方式运行在所有文档上,并定义了搜索可查询的字段。搜索索引是数据库的一种变体。它与RDBMS相似,因为它需要快速查找密钥,但是大部分数据驻留在辅助存储上。
3.创建索引
到目前为止,我们已经看到了Lucene索引的所有组成部分。在本节中,我们将使用Lucene索引创建文档索引。
考虑一个项目,学生在其中提交年度杂志文章。输入控制台包含学生姓名,文章标题,文章类别和文章正文的选项。我们假设该项目正在网络上运行并且可以通过它进行访问。要为这篇文章建立索引,我们需要文章本身,作者姓名,撰写日期,文章主题,文章标题以及文件所在的URL。利用这些信息,我们可以构建一个程序,该程序可以正确索引文章以使其易于查找。
让我们看一下我们类的基本框架,包括我们将需要的所有导入。
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
|
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.queryParser.QueryParser;
import org.apache.lucene.search.Hits;
import java.util.Date;
public class ArticleIndexer {
}
|
我们需要添加的第一件事是将文章转换为Document对象的方法。
为此,我们将使用一种方法createDocument(),
|
01
02
03
04
05
06
07
08
09
10
11
12
13
|
private Document createDocument(String article, String author,
String title, String topic,
String url, Date dateWritten) {
Document document = new Document();
document.add(Field.Text("author", author));
document.add(Field.Text("title", title));
document.add(Field.Text("topic", topic));
document.add(Field.UnIndexed("url", url));
document.add(Field.Keyword("date", dateWritten));
document.add(Field.UnStored("article", article));
return document;
}
|
首先,我们创建一个新Document对象。我们需要做的下一步是将文章的不同部分添加到中Document。我们为每个部分指定的名称完全是任意的,并且像。中的键一样工作HashMap。使用的名称必须是String。Document的add方法将使用一个Field对象,该对象使用Field类中提供的静态方法之一构建。提供了四种将Field对象添加到文档的方法。
Field.Keyword–数据已存储并建立索引,但未标记。这对于应保留不变的数据(例如日期)最有用。实际上,Field.Keyword可以将Date对象作为输入。
Field.Text–数据被存储,索引和标记化。Field.Text字段不应用于诸如文章本身之类的大量数据,因为索引将变得非常大,因为它将包含文章的完整副本以及标记化的版本。
Field.UnStored–数据不存储,但被索引和标记。大量数据(例如文章的文本)应放置在未存储的索引中。
Field.UnIndexed–数据已存储,但未编制索引或标记。它与要与搜索结果一起返回的数据一起使用,但实际上不会在该数据上进行搜索。在我们的示例中,由于我们不允许搜索URL,因此没有理由对其进行索引,但是我们希望在找到搜索结果后将其返回给我们。
现在我们有了一个Document对象,我们需要将其IndexWriter写入Document索引。
|
1个
2
3
4
5
6
7
8
9
|
String indexDirectory = "lucene-index";
private void indexDocument(Document document) throws Exception {
Analyzer analyzer = new StandardAnalyzer();
IndexWriter writer = new IndexWriter(indexDirectory, analyzer, false);
writer.addDocument(document);
writer.optimize();
writer.close();
}
|
我们首先创建一个StandardAnalyzer,然后IndexWriter使用分析器创建一个。在构造函数中,我们必须指定索引将驻留的目录。构造函数末尾的布尔值告诉IndexWriter它是应该创建新索引还是将其添加到现有索引。在将新文档添加到现有索引时,我们将指定false。然后,将添加Document到索引。最后,我们优化然后关闭索引。如果要添加多个Document对象,则应始终进行优化,然后在将所有Document对象都添加到索引之后关闭索引。
现在,我们只需要添加一种将各个部分组合在一起的方法即可。
为了驱动索引操作,我们将编写一个带有indexArticle()一些参数的方法。
|
1个
2
3
4
5
6
7
8
9
|
public void indexArticle(String article, String author,
String title, String topic,
String url, Date dateWritten)
throws Exception {
Document document = createDocument(article, author,
title, topic,
url, dateWritten);
indexDocument(document);
}
|
对文章运行该文章会将其添加到索引中。将IndexWriter构造函数中的布尔值更改为true会创建一个索引,因此我们应该在第一次创建索引以及每次要从头开始重建索引时使用它。现在我们已经构建了索引,我们需要在索引中搜索文章。
索引存储为单个目录中的一组文件。
索引由任意数量的独立段组成,这些段存储有关已索引文档子集的信息。每个段都有自己的术语词典,术语词典索引和文档存储(存储的字段值)。所有段数据都存储在_xxxxx.cfs文件中,其中xxxxx是段名称。
创建索引段文件后,将无法对其进行更新。新文档将添加到新段中。删除的文档仅在可选的.del文件中标记为已删除。
4.基本索引操作
索引数据
Lucene让我们可以索引文本格式的任何可用数据。Lucene几乎可以用于任何数据源,只要可以从中提取文本信息即可。我们可以使用Lucene对存储在HTML文档,Microsoft Word文档,PDF文件等中的数据进行索引和搜索。索引数据的第一步是使其以简单文本格式可用。可以使用自定义解析器和数据转换器。
索引过程
索引编制是将文本数据转换为便于快速搜索的格式的过程。一个简单的类比是您在书末找到的索引:该索引将您指向书中出现的主题的位置。
Lucene将输入数据存储在称为反向索引的数据结构中,该数据结构作为一组索引文件存储在文件系统或内存中。大多数Web搜索引擎使用反向索引。它使用户可以执行快速的关键字查找,并找到与给定查询匹配的文档。在将文本数据添加到索引之前,分析器会对其进行处理(使用分析过程)。
分析
分析将文本数据转换为基本搜索单位,称为术语。在分析过程中,文本数据会经历多种操作:提取单词,删除常用单词,忽略标点符号,将单词简化为词根形式,将单词更改为小写字母等。分析仅在建立索引和查询解析之前进行。分析将文本数据转换为标记,并将这些标记作为术语添加到Lucene索引中。
Lucene的带有各种内置的分析,比如SimpleAnalyzer,StandardAnalyzer,StopAnalyzer,SnowballAnalyzer,等等。它们在标记文本和应用过滤器的方式上有所不同。由于分析会在索引编制之前删除单词,因此会减小索引大小,但会对查询处理的精度产生负面影响。通过使用Lucene提供的基本构建块创建自定义分析器,可以对分析过程进行更多控制。表1显示了一些内置分析仪及其处理数据的方式。
4.1核心索引类
目录
代表索引文件存储位置的抽象类。通常主要使用两个子类:
FSDirectory—将目录存储在实际文件系统中的Directory的实现。这对于大索引很有用。
RAMDirectory—一种将所有索引存储在内存中的实现。这适用于较小的索引,这些索引可以完全加载到内存中,并在应用程序终止时销毁。由于索引保存在内存中,因此速度相对较快。
分析仪
如所讨论的,分析器负责预处理文本数据并将其转换为存储在索引中的令牌。IndexWriter接受用于索引数据之前对数据进行标记的分析器。为了正确地为文本建立索引,您应该使用适合需要被索引的文本语言的分析器。
默认分析器适用于英语。Lucene沙箱中还有其他一些分析器,包括中文,日文和韩文的分析器。
IndexDeletionPolicy
用于实现自定义从索引目录中删除过时提交的策略的接口。默认的删除策略是KeepOnlyLastCommitDeletionPolicy,它仅保留最近的提交,并在完成新提交后立即删除所有先前的提交。
IndexWriter
创建或维护索引的类。它的构造函数接受一个布尔值,该布尔值确定是创建新索引还是打开现有索引。它提供了添加,删除或更新索引中文档的方法。
对索引所做的更改最初会在内存中进行缓冲,并定期刷新到索引目录。IndexWriter公开了几个字段,这些字段控制如何在内存中缓冲索引并将其写入磁盘的方式。IndexReader除非IndexWriter调用的commit或close方法,否则看不到对索引所做的更改。IndexWriter为目录创建一个锁定文件,以防止索引同时更新导致索引损坏。IndexWriter允许用户指定可选的索引删除策略。
4.2将数据添加到索引
将文本数据添加到索引涉及两个类。
字段表示在搜索中查询或检索的一条数据。Field类封装一个字段名称及其值。Lucene提供了一些选项来指定是否需要对字段进行索引或分析以及是否需要存储其值。在创建字段实例时可以传递这些选项。下表显示了字段元数据选项的详细信息。
| 选项 | 描述 |
Field.Store.Yes | 用于存储字段的值。适用于显示搜索结果的字段,例如文件路径和URL。 |
Field.Store.No | 字段值未存储-例如,电子邮件正文。 |
Field.Index.No | 适用于未搜索的字段-通常与存储的字段(例如文件路径)一起使用。 |
Field.Index.ANALYZED | 用于索引但未分析的字段。它完整地保留了字段的原始值,例如日期和个人名称。 |
Field.Index.NOT_ANALYZED | 用于索引但未分析的字段。它完整地保留了字段的原始值,例如日期和个人名称。 |
字段元数据选项的详细信息
而文档是字段的集合。Lucene还支持增强文档和字段,如果要重视某些索引数据,这是一个有用的功能。为文本文件建立索引包括将文本数据包装在字段中,创建文档,在字段中填充文档,以及使用将文档添加到索引中IndexWriter。
5.文件和领域
如您先前所见,文档是索引和搜索过程的单元。
5.1文件
文档是一组字段。每个字段都有一个名称和一个文本值。字段可以与文档一起存储,在这种情况下,它会随文档的搜索命中一起返回。因此,每个文档通常应包含一个或多个唯一标识它的存储字段。
您将文档添加到索引,并且在执行搜索之后,您将获得结果列表,它们是文档。文档只是字段的非结构化集合。
5.2领域
字段是Lucene.net的实际内容所有者:它们基本上是一个哈希表,具有名称和值。如果我们拥有无限的磁盘空间和无限的处理能力,那就是我们所需要知道的。但是不幸的是,磁盘空间和处理能力受到限制,因此您不能仅分析所有内容并将其存储到索引中。但是Lucene.net提供了将字段添加到索引的不同方法。
Lucene的提供四种不同的类型从一个开发者可以选择字段:Keyword,UnIndexed,UnStored,和Text。您应该使用哪种字段类型取决于您要如何使用该字段及其值。
关键字字段未标记,但被逐字索引并存储在索引中。此字段适用于原始值应完整保留的字段,例如URL,日期,个人姓名,社会保险号,电话号码等。
未索引字段既没有标记也没有索引,但它们的值存储在逐字索引中。该字段适用于需要与搜索结果一起显示但绝不会直接搜索其值的字段。由于未对这种类型的字段建立索引,因此对其进行搜索很慢。由于此类型的字段的原始值存储在索引中,因此如果存在索引大小的问题,则此类型不适合存储具有非常大值的字段。
未存储字段与未索引字段相反。此类型的字段已标记并建立索引,但未存储在索引中。此字段适用于索引大量不需要以其原始形式检索的文本,例如网页正文或任何其他类型的文本文档。
文本字段被标记,索引并存储在索引中。这意味着可以搜索此类型的字段,但请注意存储为“文本”字段的字段的大小。
如果您回顾一下LuceneIndexExample该类,将会看到我使用了一个Text字段:
|
1个
|
document.add(Field.Text("fieldname", text));
|
如果要更改字段的类型,fieldname我们将调用Field类的其他方法之一:
|
1个
|
document.add(Field.Keyword("fieldname", text));
|
要么
|
1个
|
document.add(Field.UnIndexed("fieldname", text));
|
要么
|
1个
|
document.add(Field.UnStored("fieldname", text));
|
虽然Field.Text,Field.Keyword,Field.UnIndexed,和Field.UnStored电话可以先看看来电来样构造,他们真的只是为了不同的Field类方法的调用。表1总结了不同的字段类型。
| 现场方法/类型 | 代币化 | 索引 | 已储存 |
Field.Keyword(String, String) | 没有 | 是 | 是 |
Field.UnIndexed(String, String) | 没有 | 没有 | 是 |
Field.UnStored(String, String) | 是 | 是 | 没有 |
Field.Text(String, String) | 是 | 是 | 是 |
Field.Text(String, Reader) | 是 | 是 | 没有 |
表1:不同字段类型的概述。
5.3在Lucene中增强文档
在“信息检索”中,文档与搜索的相关性通过与查询的相似程度来衡量。Lucene中实现了几种相似性模型,您可以通过扩展相似性类并使用Lucene保存的索引统计信息来实现自己的相似性模型。还可以为文档分配静态分数,以表示它们在整个语料库中的重要性,而与正在执行的查询无关,例如其受欢迎程度,评分或PageRank。
在Lucene 4.0之前,您可以通过调用为文档分配静态分数document.setBoost。在内部,通过将字段的提升因子乘以文档的提升因子,将提升应用于文档的每个字段。但是,这永远无法正常工作,并且取决于所执行查询的类型,可能根本不会影响文档的排名。
通过在lucene中添加DocValues,增强文档就像在中添加a NumericDocValuesField并在中使用它一样容易CustomScoreQuery,它将计算出的分数乘以“ boost”字段的值。下面的代码示例说明了如何实现此目的:
|
01
02
03
04
05
06
07
08
09
10
11
12
13
14
15
16
|
// add two documents to the index
Document doc = new Document();
doc.add(new TextField("f", "test document", Store.NO));
doc.add(new NumericDocValuesField("boost", 1L));
writer.addDocument(doc);
doc = new Document();
doc.add(new TextField("f", "test document", Store.NO));
doc.add(new NumericDocValuesField("boost", 2L));
writer.addDocument(doc);
// search for 'test' while boosting by field 'boost'
Query baseQuery = new TermQuery(new Term("f", "test"));
Query boostQuery = new FunctionQuery(new LongFieldSource("boost"));
Query q = new CustomScoreQuery(baseQuery, boostQuery);
searcher.search(q, 10);
|
通过编写一个简单的公式,新的Expressions模块也可以用于增强文档,如下所示。尽管比使用verbose更冗长CustomScoreQuery,但它通过计算更复杂的公式(例如sqrt(_score)+ ln(boost))变得微不足道。
|
1个
2
3
4
5
6
|
Expression expr = JavascriptCompiler.compile("_score * boost");
SimpleBindings bindings = new SimpleBindings();
bindings.add(new SortField("_score", SortField.Type.SCORE));
bindings.add(new SortField("boost", SortField.Type.LONG));
Sort sort = new Sort(expr.getSortField(bindings, true));
searcher.search(baseQuery, null, 10, sort);
|
既然Lucene允许NumericDocValuesField在不重新索引文档的情况下更新,您就可以将频繁变化的字段(受欢迎程度,评分,价格,最后修改时间…)纳入提升因素,而无需每次对文档进行任何索引时都重新为其编制索引。























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



 124
124
















