




 本文详细介绍了如何利用selenium技术爬取甘肃建筑业信息。由于目标网站的动态加载特性,作者首先分析了网页结构,发现接口数据加密且接口URL不变,不适合直接通过接口抓取。因此,选择了模拟浏览器的selenium方法。在爬取过程中,遇到了弹窗问题,通过特殊手段解决,随后找到了隐藏在表单中的数据。最后,提供了完整的爬虫代码示例,数据以csv格式存储。
本文详细介绍了如何利用selenium技术爬取甘肃建筑业信息。由于目标网站的动态加载特性,作者首先分析了网页结构,发现接口数据加密且接口URL不变,不适合直接通过接口抓取。因此,选择了模拟浏览器的selenium方法。在爬取过程中,遇到了弹窗问题,通过特殊手段解决,随后找到了隐藏在表单中的数据。最后,提供了完整的爬虫代码示例,数据以csv格式存储。
目标网址:
http://42.123.101.210:8088/gzzhxt/
采用技术:selenium技术进行爬取
网站分析
1. 网页分析
分析网页,发现我们要爬取的公司信息是动态加载的,可以从两方面入手,法一:接口,需要构建请求头,但是分析发现请求头中的data数据是加密过的
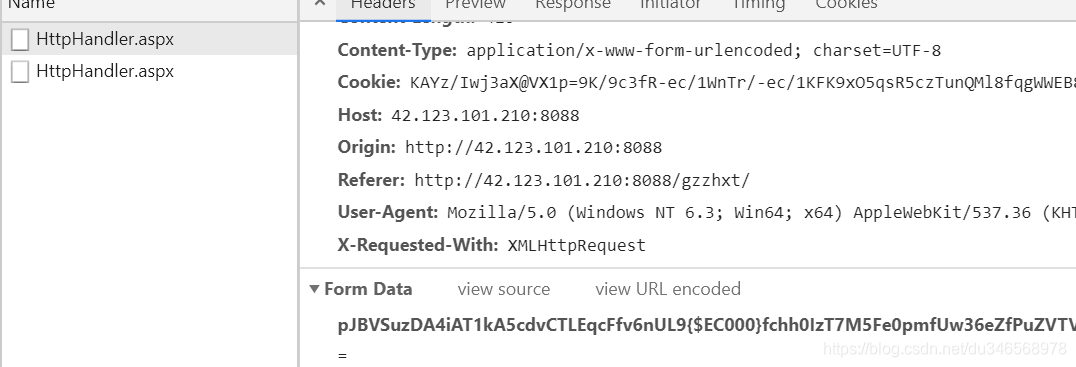 这给我们带来了很大的困难,翻页以后对比各页的url,发现接口的url并没有改变,但是在preview中发现pageIndex确实是改变的,这对我们多页爬取又设置了一个大的坑,采用接口的形式爬取很不明智。法二:采用selenium技术模拟浏览器进行爬取,这种方法在本章节着重介绍。
这给我们带来了很大的困难,翻页以后对比各页的url,发现接口的url并没有改变,但是在preview中发现pageIndex确实是改变的,这对我们多页爬取又设置了一个大的坑,采用接口的形式爬取很不明智。法二:采用selenium技术模拟浏览器进行爬取,这种方法在本章节着重介绍。
知识补充:aspx是用C#或VB.net编写的动态网页文件。aspx文件是微软的在服务器端自运行的动态网页文件,属于ASP.NET技术。
2. selenium技术分析网页
刚开始打开页面的时候,会有这样的提示
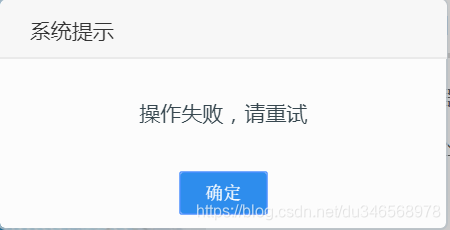 这是selenium技术爬取时,我遇见的第一个坑,系统提示,他并上不我们以前登陆时,点击登陆,触发事件,弹出登陆的框口,可以在网页中查找到触发事件的元素。他是一个window的提示窗口,本来想着是alter提示框,直接执行以下命令:
这是selenium技术爬取时,我遇见的第一个坑,系统提示,他并上不我们以前登陆时,点击登陆,触发事件,弹出登陆的框口,可以在网页中查找到触发事件的元素。他是一个window的提示窗口,本来想着是alter提示框,直接执行以下命令:
# 切换至消息框,适用于alert/confirm/prompt
alert_box = browser.switch_to.alert
# 点击消息框的确认按钮,返回值为true。适用于alert/confirm/prompt
alert_box.accept()
可惜问题并没有解决,知识匮乏,只能不断的百度查找资料,然后看见了一个取巧的方法,编入程序:
# 切换至激活状态控件
element = browser.switch_to.active_element
# 调用click()方法点击该按钮
element.click()
问题确实解决了,不过这个办法并不是每次都很有效,(奈何所学有限,这个问题没有深入解决,希望看此篇文章的大兄弟如果有高见的话,可以给我留言,在此先谢过)
之后查找企业数据的标签元素,然后模拟进行点击,之后公司的数据信息就出现了。注意,又一个新的坑,数据并不是网页中呈现的,而是以表单的形式动态加载的,起初没有注意到,采用selenium技术的xpath直接查询,匹配的数据为空,语法没有错误,但是没有爬取到数据,纠结了半天,之后发现数据是放在表单中的,这类数据是不能直接拿到的,需要先获取表单,之后再接着查询(嵌入的框架也是类似),这是之前没有碰见过的,涨知识了。
获取表单信息的代码如下:
# 切换至激活状态控件
element = browser.switch_to.active_element
# 调用click()方法点击该按钮
element.click()
获取表单以后,之后便可以重新采用xpath等方法来解析自己所需的数据了。我们获得表单是一个列表的形式,可以遍历表单,逐个解析我们所需的数据,实现的代码如下:
rawCount = len(table_tr_list)
print(rawCount)
for tr in range(1,rawCount):
com_id=table_tr_list[tr].find_element_by_xpath('.//td[2]/div').text
com_name = table_tr_list[tr].find_element_by_xpath('.//td[3]/div').text
com_rep = table_tr_list[tr].find_element_by_xpath('.//td[4]/div').text
com_date = table_tr_list[tr].find_element_by_xpath('.//td[5]/div').text
com_province = table_tr_list[tr].find_element_by_xpath('.//td[6]/div').text
com_city = table_tr_list[tr].find_element_by_xpath('.//td[7]/div').text
company_data = {
'com_id':com_id,
'com_name':com_name,
'com_rep':com_rep,
'com_date':com_date,
'com_province':com_province,
'com_city':com_city,
}
print(company_data)
# self.writer.writerow(company_data)
self.company_datas.append(company_data)
我们先定义一个全局变量,将数据存成字典的形式,便于之后数据存储。此处采用csv的形式进行存储,这个存储这一步可以直接定义一个新的方法,然后进行存储,实现代码如下:
def save_to_csv(self):
with open('companyData4.csv', 'w', encoding='utf_8_sig',newline='') as f:
filename = ['com_id', 'com_name', 'com_rep', 'com_date', 'com_province', 'com_city']
self.writer = csv.DictWriter(f, fieldnames=filename)
self.writer.writeheader()
self.writer.writerows(self.company_datas)
整个流程就是这样,其中的坑,如果之前没有做过类似的爬虫的话,确实不好看出来,得花费一点时间,慢慢积累吧,最终自己的技术成熟了,也就没有什么所谓的困难了。
3. 整体代码
如需借鉴,整体的代码实现如下,共同进步:
import time
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import csv
class GuizhouSpider(object):
chrome_driver = r"F:\python\python_environment\chromedriver.exe"
# #文件存储
# f = open('companyData3.csv', 'w', encoding='utf_8_sig',newline='')
# filename = ['com_id', 'com_name', 'com_rep', 'com_date', 'com_province', 'com_city']
# writer = csv.DictWriter(f, fieldnames=filename)
# writer.writeheader()
def __init__(self):
self.driver = webdriver.Chrome(executable_path=self.chrome_driver)
self.url = 'http://42.123.101.210:8088/gzzhxt/'
self.company_datas = []
def run(self):
# self.driver.implicitly_wait(10)
self.driver.get(self.url)
#处理弹出的提示框
alert = self.driver.switch_to.active_element
alert.click()
time.sleep(2)
#查找企业数据的元素
WebDriverWait(driver=self.driver, timeout=10).until(
EC.presence_of_element_located((By.XPATH, '//li[@id="enterprise_tab"]/a'))
)
qi_btn = self.driver.find_element_by_xpath('//li[@id="enterprise_tab"]/a')
qi_btn.click()
time.sleep(5)
page = 1
while page<=2:
#定位到table
table_loc =(By.XPATH,'//*[@id="divLstGrid__weblistenterpriseLib_Box__"]/table/tbody')
#获取table
table_tr_list = self.driver.find_element(*table_loc).find_elements(By.TAG_NAME,"tr")
rawCount = len(table_tr_list)
print(rawCount)
for tr in range(1,rawCount):
com_id=table_tr_list[tr].find_element_by_xpath('.//td[2]/div').text
com_name = table_tr_list[tr].find_element_by_xpath('.//td[3]/div').text
com_rep = table_tr_list[tr].find_element_by_xpath('.//td[4]/div').text
com_date = table_tr_list[tr].find_element_by_xpath('.//td[5]/div').text
com_province = table_tr_list[tr].find_element_by_xpath('.//td[6]/div').text
com_city = table_tr_list[tr].find_element_by_xpath('.//td[7]/div').text
company_data = {
'com_id':com_id,
'com_name':com_name,
'com_rep':com_rep,
'com_date':com_date,
'com_province':com_province,
'com_city':com_city,
}
print(company_data)
# self.writer.writerow(company_data)
self.company_datas.append(company_data)
#翻页
next_btn = self.driver.find_element_by_xpath('//*[@id="weblistenterpriseLib_Box_btnNextPage"]')
next_btn.click()
page+=1
time.sleep(4)
# self.writer.writerows(self.company_datas)
self.save_to_csv()
def save_to_csv(self):
with open('companyData4.csv', 'w', encoding='utf_8_sig',newline='') as f:
filename = ['com_id', 'com_name', 'com_rep', 'com_date', 'com_province', 'com_city']
self.writer = csv.DictWriter(f, fieldnames=filename)
self.writer.writeheader()
self.writer.writerows(self.company_datas)
if __name__ == '__main__':
guizhou = GuizhouSpider()
guizhou.run()

















 1142
1142

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









