







概述
在介绍hadoop集群的重要节点之前,先举一个简单的例子说明一下:
场景就是,我们有一个网站,网站中有很多用户,每个用户都有自己的信息和动态等,那么对于这些信息,我们网站的后台都是需要记录的。
怎么记录呢,直接就根据用户的标号,放在一个文件夹里吧,然后存在磁盘中(或者放在数据库里,都可以)
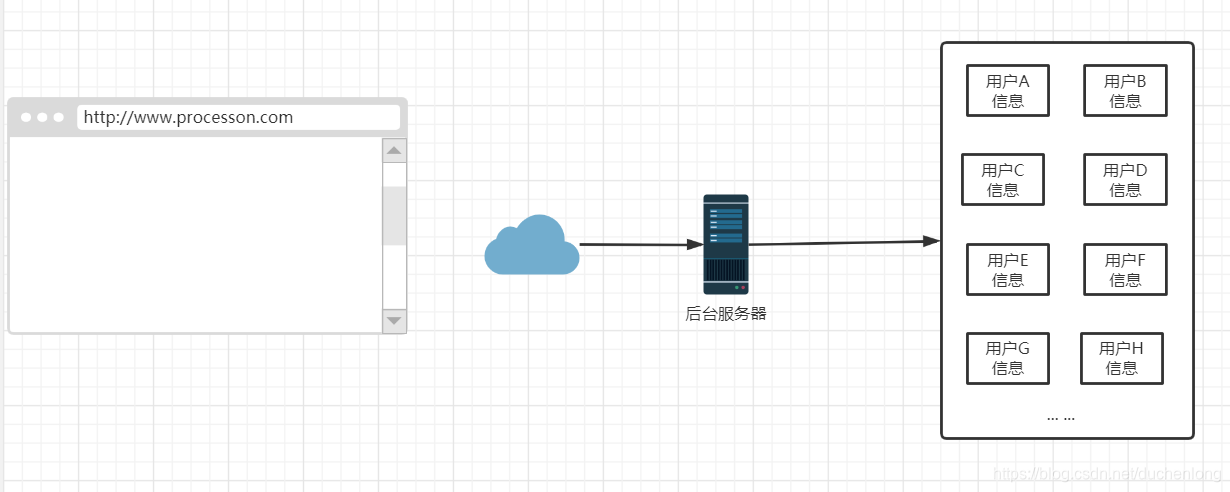
然后呢,随着时间的发展,用户的数量越来越多,我们后台的一个服务器里可能存不下这么多的数据,这个时候两种方式:
- 给磁盘扩容
- 加机器
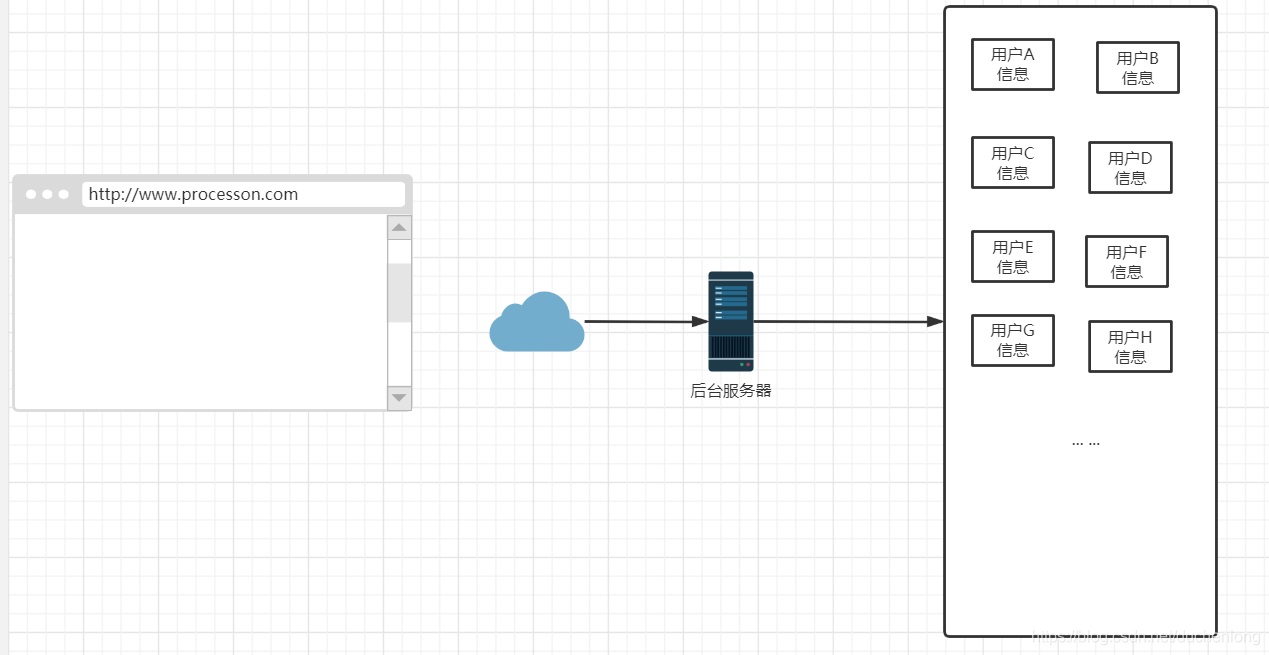
如果我们给磁盘扩容的方式去处理,但是是不是需要考虑到我们一个服务器的处理能力,这样虽然可以在同一台机器中存储下来,这样就意味着服务器在找一个资源的时候,需要花费的时间变长了,因为分母变大了,他的效率就会有点小
采用加机器的方式,利用Nginx这些技术,将不同用户的信息存储在多个服务器中,至于来了一个用户,怎么确定他的信息在哪里,就需要看后端的算法怎么写的了 ,可以使用哈希,也可以使用自己定义的规则,但是一定要让第二次请求用户信息时,可以找到第一个存储的位置
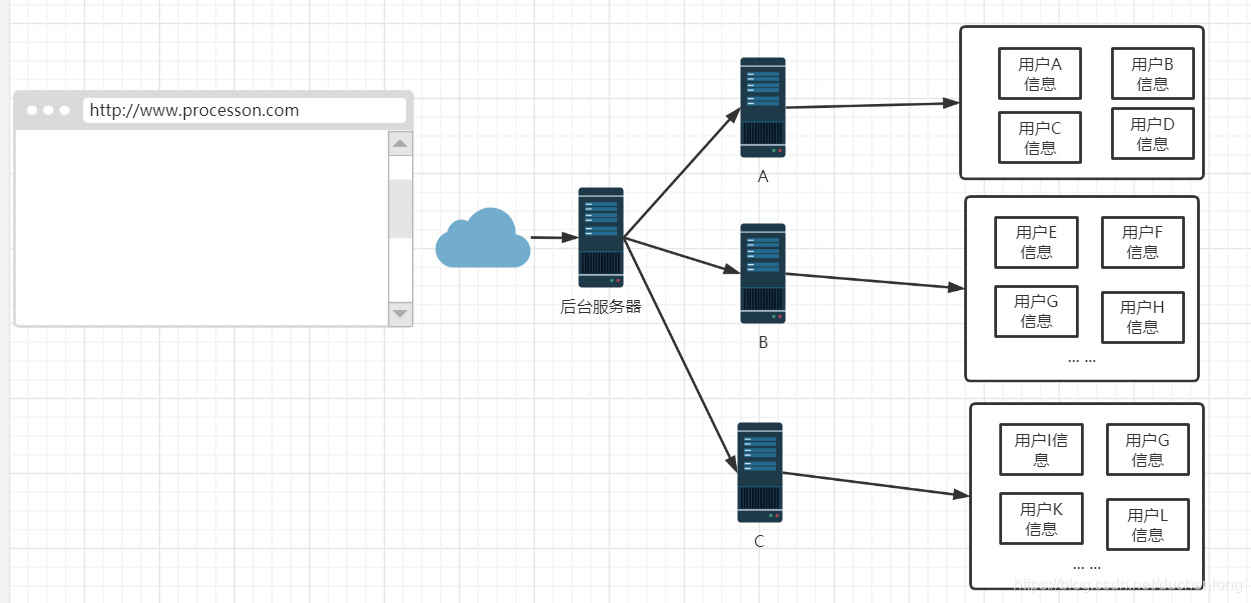
但是这样还是有着一些问题,就比如我中间的一些用户信息存储在服务器A,但是某一段时间服务器A突然宕机了,那么就意味着服务器A暂时无法提供数据。
这样该怎么解决呢,hadoop分布式存储中的一系列机制,就确保了数据的稳定
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









