




 本文介绍了如何在Hadoop Hive中创建一个用户定义函数(UDF)用于字符串大小写转换。通过编写Java代码并打包成JAR,然后在Hive中注册该函数,实现数据处理的自定义功能。详细步骤包括POM配置、UDF代码实现、Hive函数创建及删除,以及JAR文件的上传和使用。
本文介绍了如何在Hadoop Hive中创建一个用户定义函数(UDF)用于字符串大小写转换。通过编写Java代码并打包成JAR,然后在Hive中注册该函数,实现数据处理的自定义功能。详细步骤包括POM配置、UDF代码实现、Hive函数创建及删除,以及JAR文件的上传和使用。
我们在工作中最常用的应该就是UDF一进一出函数了,因此我给大家准备了一个大小写转换的例子希望可以帮到大家
pom如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.wy</groupId>
<artifactId>func</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec -->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>1.2.1</version>
</dependency>
</dependencies>
</project>
代码如下:
package com.wy.fun;
import org.apache.hadoop.hive.ql.exec.UDF;
public class ToUpper extends UDF {
/**
* 此方法的格式除了返回值类型、形参之外都不要变
* 不然会出现一些默认其妙的问题
*/
public static String evaluate(final String s){
return s.toUpperCase();
}
}
不要轻易使用Hadoop自己的数据类型如Text那些,因为当不同架构混合使用的时候会发生无法正常分装数据的问题
最后连接Hadoop将编译好的jar上传的hdfs上,之后使用如下语句操作函数的创建
//add语句使用的前提是jar在hive的jar路径下
add jar myudf.jar;
//add之后直接就可以运行create语句,加上temporary 创建的是临时函数,断开hive之后该函数失效,不加建立的是永久函数
create temporary function myudf as 'com.wy.ToUpper' using jar 'hdfs://wy:9000/myudf.jar';
//上面是jar放在了hive的lib下,如果我们的jar就在hdfs上那么我们直接使用下面这个语句就可以,同样的加上temporary 创建的是临时函数,断开hive之后该函数失效,不加建立的是永久函数
create function myudf as 'com.wy.ToUpper' using jar 'hdfs://wy:9000/myudf.jar';
//临时函数可以直接删除,但永久函数不可直接删除,只能从元数据库的FONC表中入手删除,还不一定可以删成功
drop temporary function myudf;
我们使用的时候直接和其他的内建函数一样就可以了
最后要说一个很常见的细节点,无论是你用开源云也好,还是阿里的MaxComputer也罢,一定会有调试日志输出的需求,这里以开源云或者说是云原生为例,在Hive中你有两种让自定义函数中的日志,出现在yarn上的方法
第一种是直接在代码中调用System.out.println() 或者 System.err.println() 这中方式最终会被yarn收集在His服务的task级别日志中,对应了标准输出和标准错误输出。第二种是调用日志框架,在你导入的自定义函数接口Jar中Hive自动依赖了apache 的common包,不需要你额外的去引入log4j包,这里面有能够直接使用封装好的日志工厂类
package udf;
//不要导错包
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* 一个字符串转大写的UDF
*/
public class ToUP extends UDF {
//也不要用错工厂类,不然很容易导致标准错误输出中一堆初始化异常
static final Log LOG = LogFactory.getLog(ToUP.class.getName());
public static String evaluate(final String s){
LOG.info("日志框架的信息 evaluate 检测到函数的输出" + s);
System.out.println("Java输出的信息 evaluate 检测到函数的输出" + s);
return s.toUpperCase();
}
}
最终这两种方式,你就可以在task级别日志中看到
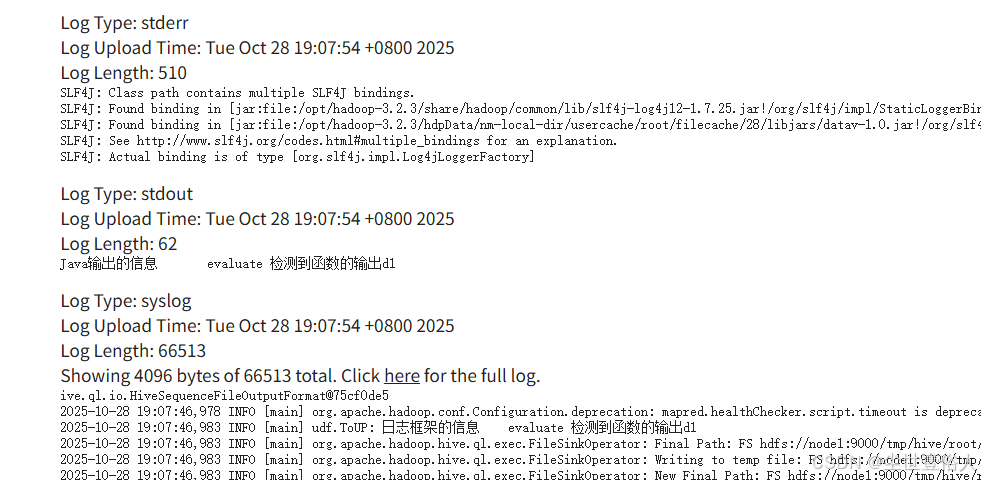
使用apache的日志类好处是你不需要自己准备log4j的配置文件等等,只需要获取调用就行,但是不方便的是它输出在syslog里面,如果你实实在在的就想输出在标准输出和标准错误输出中,可以参考阿里云上的一篇文章,自己写一个简易的日志类调用就行-》https://help.aliyun.com/zh/maxcompute/user-guide/print-udf-logs#9319d07073jn5
import java.io.PrintWriter;
import java.io.StringWriter;
import java.text.SimpleDateFormat;
public class MyLogger {
private static final SimpleDateFormat DATEFORMATE = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static MyLogger getLogger(String name) {
return new MyLogger(name);
}
private static boolean debug = false;
private String prefix;
public static void setDebug(boolean enableDebug) {
debug = enableDebug;
}
public MyLogger(String name) {
if (name == null) {
this.prefix = "";
} else {
this.prefix = name + " - ";
}
}
private String logCurrentTime() {
return "[" + dateFormat.format(System.currentTimeMillis()) + "]";
}
public void log(String msg) {
info(msg);
}
public void info(String msg) {
System.out.println(logCurrentTime() + " " + prefix + msg);
}
public void debug(String msg) {
if (MyLogger.debug) {
System.out.println(logCurrentTime() + " [DEBUG] " + prefix + msg);
}
}
public void warn(String msg) {
System.err.println(logCurrentTime() + " [WARNING] " + prefix + msg);
}
public void warn(String msg, Throwable ex) {
warn(msg);
System.err.println(getStackTrace(ex));
}
public void error(String msg) {
System.err.println(logCurrentTime() + " [ERROR] " + prefix + msg);
}
public void error(String msg, Throwable ex) {
error(msg);
System.err.println(getStackTrace(ex));
}
private String getStackTrace(Throwable t) {
StringWriter sw = new StringWriter();
t.printStackTrace(new PrintWriter(sw));
return sw.toString();
}
}
public class MyUdf extends UDF {
public static final MyLogger LOGGER = MyLogger.getLogger(MyUdf.class.getName());
@Override
public void setup(ExecutionContext ctx) throws UDFException, IOException {
logger.info("setup MyUdf");
}
public Integer evaluate(String s) {
logger.debug("input s: " + s);
int ret = 0;
try {
ret = Integer.parseInt(s);
} catch (Exception e) {
logger.error("parseInt error!", e);
}
return ret;
}
}

















 369
369




 到【灌水乐园】发言
到【灌水乐园】发言







