







(1)内容借鉴自:http://blog.qiniu.com/archives/1836 感谢原文作者
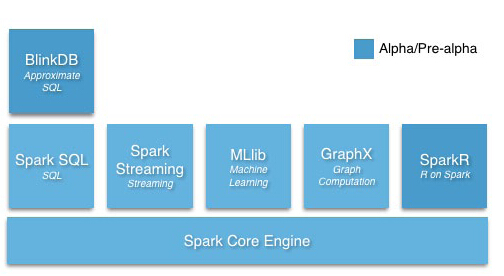
如图所示,可以看出Spark包含了批处理、流处理、图处理、机器学习、即时查询与关系查询等功能,这就意味着我们只需要一个框架就可以满足各种使用场景的需求。如果放在以前,我们可能需要为每个功能都准备一套框架,譬如采用Hadoop MapReduce来做批处理和采用Storm来做流式处理,这样做带来的结果是我们必须分别针对两套计算框架编写不同的业务代码,而编写出的业务代码也几乎无法重用;另一方面,为了使系统稳定,我们还得额外投入人力去深入理解Hadoop MapReduce及Storm的原理,这将造成很大的人力开销。当采用Spark后,我们只需要去理解Spark即可,另一个吸引人的地方在于Spark批处理与流计算的业务代码几乎可以完全重用,这也就意味着我们只需要编写一份逻辑代码就可以分别运行批处理与流计算。最后,Spark可以无缝使用存储在HDFS上的数据,无需任何数据迁移动作。
同时,由于现存系统必须要与以HDFS为代表的分布式文件系统进行数据共享和交换,由此造成的IO开销大幅度地降低了计算效率;除此之外,反复的序列化与反序列化也是不可忽略的开销。鉴于此,S**park中抽象出了RDD的概念,并基于RDD定义了一系列丰富的算子,MapReduce只是其中一个非常小的子集,与此同时,**RDD也可以被缓存在内存中,从而迭代计算可以充分地享受内存计算所带来的加速效果。与MapReduce基于进程的计算模型不一样,Spark基于的是多线程模型,这也意味着Spark的任务调度延迟可以控制在亚秒级,当任务特别多的时候,这么做可以大幅度降低整体调度时间,并且为基于macro batch的流式计算打下基础。
Spark的另一个特色是基于DAG的任务调度与优化,Spark不需要像MapReduce一样为每一步操作都去调度一个作业,相反,Spark丰富的算子可以更自然地以DAG形式表达运算。同时,在Spark中,每个stage内部是有pipeline优化的,所以即使我们不使用内存缓存数据,Spark的执行效率也要比Hadoop高。最后Spark基于RDD的lineage信息来容错,由于RDD是不可变的,Spark并不需要记录中间状态,当RDD的某些partition丢失时,Spark可以利用RDD的lineage信息来进行并行的恢复,不过当lineage较长时,还是推荐用户适时checkpoint,从而减少恢复时间。
(2) 内容借鉴自http://www.jdon.com/bigdata/spark.html 感谢原作者
Spark是hadoop的升级版本,Hadoop作为第一代产品使用HDFS,第二代加入了Cache来保存中间计算结果,并能适时主动推Map/Reduce任务,第三代就是Spark倡导的流Streaming。
Spark兼容Hadoop的APi,能够读写Hadoop的HDFS HBASE 顺序文件等。
Spark的编程模型
弹性的分布数据集(RDD) :分布式对象集合能够跨集群在内存中保存。多个并行操作,失败自动恢复。
使用内存集群计算, 内存访问要比磁盘快得多。有Scala Java Python API,能够从Scala和Python访问。















 265
265











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









