







2021.3.12 天气:晴朗
集合
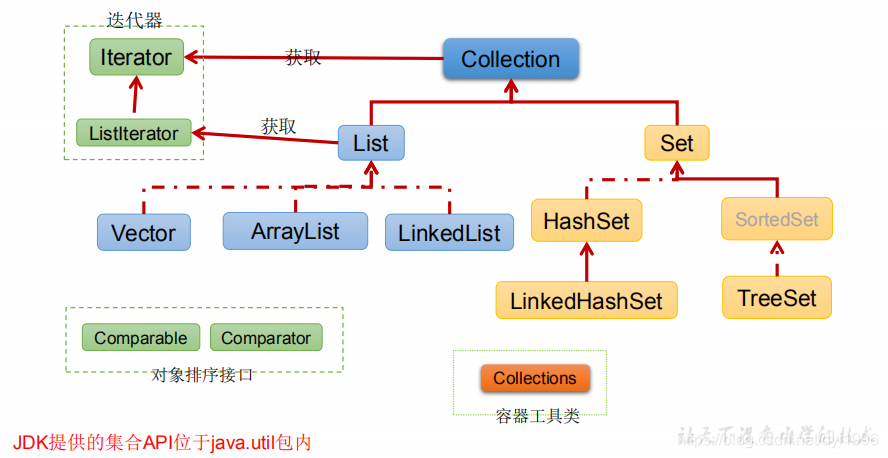
Java 集合就像一种容器,可以动态地把多个对象的引用放入容器中,Java 集合可分为 Collection 和 Map 两种体系。
一、Collection
单列数据,定义了存取一组对象的方法的集合
List:元素有序、可重复的集合
Set:元素无序、不可重复的集合
Collection 接口方法:
1、添加
add(Object obj)
addAll(Collection coll)2、获取有效元素的个数
int size()3、清空集合
void clear()4、是否是空集合
boolean isEmpty()5、是否包含某个元素
boolean contains(Object obj):是通过元素的equals方法来判断是否 是同一个对象
boolean containsAll(Collection c):也是调用元素的equals方法来比 较的。拿两个集合的元素挨个比较。6、删除
boolean remove(Object obj) :通过元素的equals方法判断是否是要删除的那个元素。只会删除找到的第一个元素
boolean removeAll(Collection coll):取当前集合的差集7、取两个集合的交集
boolean retainAll(Collection c):把交集的结果存在当前集合中,不影响c8、集合是否相等
boolean equals(Object obj)
9、转成对象数组
Object[] toArray()10、获取集合对象的哈希值
hashCode()
11、遍历
iterator():返回迭代器对象,用于集合遍历
1、Collection子接口之一:List接口
List集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。
JDK API中List接口的实现类常用的有:ArrayList、LinkedList和Vector。
ArrayList
本质上,ArrayList是对象引用的一个”变长”数组
LinkedList
LinkedList:双向链表,内部没有声明数组,而是定义了Node类型的first和last,
用于记录首末元素。同时,定义内部类Node,作为LinkedList中保存数据的基 本结构。Node除了保存数据,还定义了两个变量:
prev变量记录前一个元素的位置
next变量记录下一个元素的位置
2.Collection子接口之二:Set接口
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个Set 集合中,则添加操作失败。
HashSet
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存取、查找、删除性能。
LinkedHashSet
LinkedHashSet 根据元素的 hashCode
值来决定元素的存储位置,但它同时使用双向链表维护元素的次序,这使得元素看起来是以插入顺序保存的。
TreeSet
TreeSet 是 SortedSet 接口的实现类,TreeSet 可以确保集合元素处于排序状态。
TreeSet底层使用红黑树结构存储数据
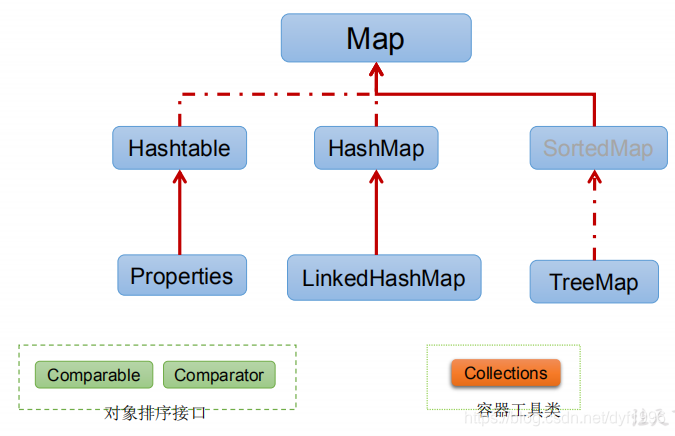
二、Map
双列数据,保存具有映射关系“key-value对”的集合
Map接口的常用实现类:HashMap、TreeMap、LinkedHashMap和Properties。其中,HashMap是 Map 接口使用频率最高的实现类
1.HashMap
允许使用null键和null值,与HashSet一样,不保证映射的顺序
所有的key构成的集合是Set:无序的、不可重复的。所以,key所在的类要重写:equals()和hashCode()
节点
JDK 7及以前版本:HashMap是数组+链表结构(即为链地址法),节点为Entry
JDK8版本发布以后:HashMap是数组+链表+红黑树实现。节点为Node
扩容
HashMap的默认容量,16
threshold:扩容的临界值,=容量*填充因子,默认12
loadFactor:填充因子,默认0.75拓展:扩容需要重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知HashMap中元素的个数,那么预设元素的个数能够有效的提高HashMap的性能。
总结:JDK1.8相较于之前的变化:
1.HashMap map = new HashMap();//默认情况下,先不创建长度为16的数组
2.当首次调用map.put()时,再创建长度为16的数组
3.数组为Node类型,在jdk7中称为Entry类型
4.形成链表结构时,新添加的key-value对在链表的尾部(七上八下)
5.当数组指定索引位置的链表长度>8时,且map中的数组的长度> 64时,此索引位置 上的所有key-value对使用红黑树进行存储。
2.LinkedHashMap
在HashMap存储结构的基础上,使用了一对双向链表来记录添加 元素 的顺序
与LinkedHashSet类似,LinkedHashMap 可以维护 Map 的迭代顺序:迭代顺序与 Key-Value 对的插入顺序一致
3.TreeMap
TreeMap存储 Key-Value 对时,需要根据 key-value 对进行排序。
TreeMap 可以保证所有的 Key-Value对处于有序状态。
4.Hashtable
Hashtable实现原理和HashMap相同,功能相同。底层都使用哈希表结构,查询速度快,很多情况下可以互用。
不同于HashMap,Hashtable是线程安全的,Hashtable 不允许使用 null 作为 key 和 value
5.Properties
Properties 类是 Hashtable 的子类,该对象用于处理属性文件
由于属性文件里的 key、value 都是字符串类型,所以 Properties 里的 key 和 value 都是字符串类型
二、Collections工具类
Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法
1.排序操作:(均为static方法)
reverse(List):反转 List 中元素的顺序
shuffle(List):对 List 集合元素进行随机排序
sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
swap(List,int, int):将指定 list 集合中的 i处元素和 j 处元素进行交换
2.查找、替换
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素
Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素
int frequency(Collection,Object):返回指定集合中指定元素的出现次数
void copy(List dest,List src):将src中的内容复制到dest中
boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换List 对象的所有旧值














 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









