







原文出处:http://blog.csdn.net/sparkliang/article/details/5671510
感谢作者的详解。转到此处以备学习。
作为blog再次发出来,详细描述一下CRC32算法的推导过程。
CRC算法的数学基础
CRC算法的数学基础就不再多啰嗦了,到处都是,简单提一下。它是以GF(2)多项式算术为数学基础的,GF(2)多项式中只有一个变量x,其系数也只有0和1,比如:
1*x^6 + 0*x^5 + 1*x^4 + 0*x^3 + 0*x^2 +1*x^1 + 1*x^0
=x^6 + x^4 + x + 1
加减运算不考虑进位和退位。说白了就是下面的运算规则:
0+ 0 = 0 0 - 0 = 0
0+ 1 = 1 0 - 1 = 1
1+ 0 = 1 1 - 0 = 1
1 + 1 = 0 1 - 1 = 0
看看这个规则,其实就是一个异或运算。
每个生成多项式的系数只能是0或1,因此我们可以把它转化为二进制形式表示,比如g(x)=x^4 + x + 1,那么g(x)对应的二进制形式就是 10011,于是我们就把GF(2)多项式的除法转换成了二进制形式,和普通除法没有区别,只是加减运算没有进位和退位。
比如基于上述规则计算11010/1001,那么商是11,余数就是101,简单吧。
CRC校验的基本过程
采用CRC校验时,发送方和接收方用同一个生成多项式g(x) ,g(x)是一个GF(2)多项式,并且g(x)的首位和最后一位的系数必须为1。
CRC的处理方法是:发送方用发送数据的二进制多项式t(x)除以g(x),得到余数y(x)作为CRC校验码。校验时,以计算的校正结果是否为0为据,判断数据帧是否出错。设生成多项式是r阶的(最高位是x^r)具体步骤如下面的描述。
发送方:
1)在发送的m位数据的二进制多项式t(x)后添加r个0,扩张到m+ r位,以容纳r位的校验码,追加0后的二进制多项式为 T(x);
2)用T(x)除以生成多项式g(x),得到r位的余数y(x),它就是CRC校验码;
3)把y(x)追加到t(x)后面,此时的数据s(x)就是包含了CRC校验码的待发送字符串;由于s(x) = t(x) y(x),因此s(x)肯定能被g(x)除尽。
接收方:
1)接收数据n(x),这个n(x)就是包含了CRC校验码的m+r位数据;
2)计算n(x)除以g(x),如果余数为0则表示传输过程没有错误,否则表示有错误。从n(x)去掉尾部的r位数据,得到的就是原始数据。
生成多项式可不是随意选择的,数学上的东西就免了,以下是一些标准的CRC算法的生成多项式:
| 标准 | 生成多项式 | 16进制表示 |
| CRC12 | x^12 + x^11 + x^3 + x^2 + x + 1 | 0x80F |
| CRC16 | x^16 + x^15 + x^2 + 1 | 0x8005 |
| CRC16-CCITT | x^16 + x^12 + x^5 + 1 | 0x1021 |
| CRC32 | x^32 + x^26 + x^23 + x^22 + x^16 + x^12 + x^11+ x^10 + x^8 + x^7 + x^5 + x^4 + x^2 + x + 1 | 0x04C11DB7 |
原始的CRC校验算法
根据多项式除法,我们就可以得到原始的CRC校验算法。假设生成多项式g(x)是r阶的,原始数据存放在data中,长度为len个bit,reg是r+1位的变量。以CRC-4为例,生成多项式g(x)=x^4 + x + 1,对应了一个5bits的二进制数字10011,那么reg就是5 bits。
reg[1]表明reg的最低位,reg[r+1]是reg的最高位。
通过反复的移位和进行除法,那么最终该寄存器中的值去掉最高一位就是我们所要求的余数。所以可以将上述步骤用下面的流程描述:
- reg = 0;
- data = data追加r个;
- pos = 1;
- while(pos <= len)
- {
- if(reg[r+1] == 1) // 表明reg可以除以g(x)
- {
- // 只关心余数,根据上面的算法规则可知就是XOR运算
- reg = reg XOR g(x);
- }
- // 移出最高位,移入新数据
- reg = (reg<<1) | (data[pos]);
- pos++;
- }
- return reg; // reg中的后r位存储的就是余数
改进一小步——从r+1到r
由于最后只需要r位的余数,所以我们可以尝试构造一个r位的reg,初值为0,数据data依次移入reg[1],同时把reg[r]移出 reg。
根据上面的算法可以知道,只有当移出的数据为1时,reg才和g(x)进行XOR运算;于是可以使用下面的算法:
- reg = 0;
- data = data追加r个;
- pos = 1;
- while(pos < len)
- {
- hi-bit = reg[r];
- // 移出最高位,移入新数据
- reg = (reg<<1) | (data[pos]);
- if(hi-bit == 1) // 表明reg可以除以g(x)
- {
- reg = reg XOR g(x);
- }
- pos++;
- }
- return reg; // reg中存储的就是余数
这种算法简单,容易实现,对任意长度生成多项式的G(x)都适用,对应的CRC-32的实现就是:
- // 以4 byte数据为例
- #define POLY 0x04C11DB7L // CRC32生成多项式
- unsigned int CRC32_1(unsigned int data)
- {
- unsigned char p[8];
- memset(p, 0, sizeof(p));
- memcpy(p, &data, 4);
- unsigned int reg = 0, idx = 0;
- for(int i = 0; i < 64; i++)
- {
- idx = i/8;
- int hi = (reg>>31)&0x01; // 取得reg的最高位
- // 把reg左移1bit,并移入新数据到reg0
- reg = (reg<<1)| (p[idx]>>7);
- if(hi) reg = reg^POLY; // hi=1就用reg除以g(x)
- p[idx]<<=1;
- }
- return reg;
- }
从bit扩张到byte的桥梁
但是如果发送的数据块很长的话,这种方法就不太适合了。它一次只能处理一个bit的数据,效率太低。考虑能不能每次处理一个byte的数据呢?事实上这也是当前的CRC-32实现采用的方法。
这一步骤是通往基于校验表方法的桥梁,让我们一步一步来分析上面逐bit的运算方式,我们把reg和g(x)都采用bit的方式表示如下:
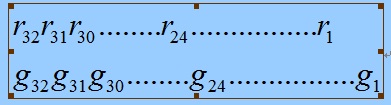
考虑把上面逐bit的算法执行8次,如果某次移出的不是1,那么reg不会和g(x)执行XOR运算,事实上这相当于将reg和0执行了XOR运算。执行过程如下所示,根据hi-bit的值,这里的G可能是g(x)也可能是0。

从上面的执行过程清楚的看到,执行8次后,old-reg的高8bit被完全移出,new-reg就是old-reg的低24bit和数据data新移入的8bit和G一次次执行XOR运算所得到的。
XOR运算满足结合律,那就是:A XOR B XOR C = A XOR (BXOR C),于是我们可以考虑把上面的运算分成两步进行:
1)先执行R高8bit与G之间的XOR运算,将计算结果存入X中,如下面的过程所示。
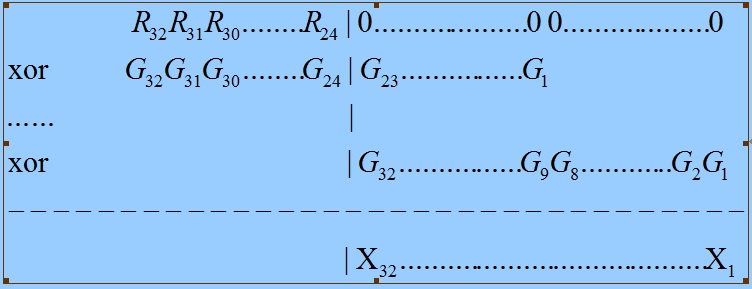
2)将R左移8bit,并移入8bit的数据,得到的值就是![]() ,然后再与X做XOR运算。
,然后再与X做XOR运算。
根据XOR运算的结合率,最后的结果就等于上面逐bit的算法执行8次后的结果,根据这个分解,我们可以修改逐bit的方式,写出下面的算法。
- // 以4 byte数据为例
- #define POLY 0x04C11DB7L // CRC32生成多项式
- unsigned int CRC32_2(unsigned int data)
- {
- unsigned char p[8];
- memset(p, 0, sizeof(p));
- memcpy(p, &data, 4);
- unsigned int reg = 0, sum_poly = 0;
- for(int i = 0; i < 8; i++)
- {
- // 计算步骤1
- sum_poly = reg&0xFF000000;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x80000000; // 测试reg最高位
- sum_poly <<= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- // 计算步骤2
- reg = (reg<<8)|p[i];
- reg = reg ^ sum_poly;
- }
- return reg;
- }
初见Table-Driven
变换到上面的方法后,我们离table-driven的方法只有一步之遥了,我们知道一个字节能表示的正整数范围是0~255,步骤1中的计算就是针对reg的高Byte位进行的,于是可以被提取出来,预先计算并存储到一个有256项的表中,于是下面的算法就出炉了,这个和上面的算法本质上并没有什么区别。
- #define POLY 0x04C11DB7L // CRC32生成多项式
- static unsigned int crc_table[256];
- unsigned int get_sum_poly(unsigned char data)
- {
- unsigned int sum_poly = data;
- sum_poly <<= 24;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x80000000; // 取得reg的最高位
- sum_poly <<= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- return sum_poly;
- }
- void create_crc_table()
- {
- for(int i = 0; i < 256; i++)
- {
- crc_table[i] = get_sum_poly(i&0xFF);
- }
- }
- // 以byte数据为例
- unsigned int CRC32_3(unsigned int data)
- {
- unsigned char p[8];
- memset(p, 0, sizeof(p));
- memcpy(p, &data, 4);
- unsigned int reg = 0, sum_poly = 0;
- for(int i = 0; i < 8; i++)
- {
- // 计算步骤1
- sum_poly = crc_table[(reg>>24)&0xFF];
- // 计算步骤2
- reg = (reg<<8)|p[i];
- reg = reg ^ sum_poly;
- }
- return reg;
- }
更进一步
上面的这个算法已经是一个Table-Driven的CRC-32算法了,但是实际上我们看到的CRC校验代码都是如下的形式:
- r=0;
- while(len--)
- r = (r<<8) ^ t[(r >> 24) ^ *p++];
下面我们将看看是做了什么转化而做到这一点的。
首先上述CRC算法中,我们需要为原始数据追加r/8Byte个0, CRC-32就是4Byte。或者我们可以再计算原始数据之后,把0放在后面单独计算,像这样:
- // 先计算原始数据
- for(int i = 0; i < len; i++)
- {
- sum_poly = crc_table[(reg>>24)&0xFF];
- reg = (reg<<8)|p[i];
- reg = reg ^ sum_poly;
- }
- // 再计算追加的4Byte 0
- for(int i = 0; i < 4; i++)
- {
- reg = (reg<<8) ^ crc_table[(reg>>24)&0xFF];
- }
这看起来已经足够好了,而事实上我们可以继续向下进行以免去为了附加的0而进行计算。在上面算法中,最后的4次循环是为了将输入数据的最后r/8位都移出reg,因为0对reg的值并没有丝毫影响。
对于CRC-32,对于任何输入数据Dn...D8…D5D4…D1,第一个for循环将Dn…D8…D5都依次移入,执行XOR运算再移出reg;并将D4…D1都移入了reg,但是并未移出;因此最后的4次循环是为了将D4…D1都移出reg。
Di与Ri执行XOR运算后值将会更新,设更新后的值表示为Di’,不论执行了多少次XOR运算。
如果reg初始值是0,那么第一个for循环中开始的4次循环干的事情就是,把Dn…Dn-3移入到reg中(与0做XOR结果不变),执行4次后reg的值就是Dn.Dn-1.Dn-2.Dn-3;
第5次循环的结果就是:reg =crc_table[Dn] ^ Dn-1.Dn-2.Dn-3.Dn-4;
第6次循环的结果就是:reg =crc_table[Dn-1’] ^ Dn-2’.Dn-3’.Dn-4;Dn移出reg。
因此上面的计算可以分为3个阶段:
1)前4次循环,将Dn.Dn-1.Dn-2.Dn-3装入reg;
2)中间的n-4次循环,依次将Di移入reg,在随后的4次循环中,依次计算Di+4,Di+3,Di+2和Di+1对Di的影响;最后移出reg;
3)最后的4次循环,实际上是为了计算D4,D3,D2和D1都能执行第2步的过程;
具体考察Di:
1)Di移入到reg中,R1=Di,接着与crc_table[R4]执行XOR运算;
2)循环4次后,Di成为reg的最高位R4,并且因为受到了Dn…Di+1的影响而更新为Di’;
上面的运算步骤如下面所示,其中F是对应得crc_table[R]的值。

可以清晰的看到,最后reg的高Byte是Di和F之间一次次XOR运算的结果。依然根据XOR运算的结合律,我们可以分两步走:
1) 先执行F之间的XOR运算,设结果为FF,它就是reg的首字节;
2) 然后再直接将Di和FF进行XOR运算,并根据结果查CRC表;
3) 计算出XOR运算后,Di…Di-3已经移入reg;因此再将查表结果和(reg<<8)执行XOR运算即可;
这就是方法2,于是我们的table-driven的CRC-32校验算法就可以写成如下的方式了:
- reg = 0;
- for(int i = 0; i < len; i++)
- {
- reg = (reg<<8) ^ crc_table[(reg>>24)&0xFF ^ p[i]];
- }
郁闷的位逆转
看起来我们已经得到CRC-32算法的最终形式了,可是、可是在实际的应用中,数据传输时是低位先行的;对于一个字节Byte来讲,传输将是按照b1,b2,...,b8的顺序。而我们上面的算法是按照高位在前的约定,不管是reg还是G(x),g32,g31,...,g1;b8,b7,...,b1; r32,r31,...,r1。
先来看看前面从bit转换到Byte一节中for循环的逻辑:
- sum_poly = reg&0xFF000000;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x80000000; // 测试reg最高位
- sum_poly <<= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- // 计算步骤2
- reg = (reg<<8)|p[i];
- reg = reg ^ sum_poly;
在这里的计算中,p[i]是按照p8,p7,...,p1的顺序;如果p[i]在这里变成了p1,p2,...,p8的顺序;那么reg也应该是r1,r2,...,r32的顺序,同样G(x)和sum_poly也要逆转顺序。转换后的G(x)= POLY = 0xEDB88320。
于是取reg的最高位的sum_poly的初值就从sum_poly= reg & 0xFF000000变成了sum_poly= reg & 0xFF,测试reg的最高位就从sum_poly & 0x80000000变成了sum_poly&0x01;
移出最高位也就从sum_poly<<=1变成了sum_poly>>=1;于是上面的代码就变成了如下的形式:
- sum_poly = reg&0xFF;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x01; // 测试reg最高位
- sum_poly >>= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- // 计算步骤2
- reg = (reg<<8)|p[i];
- reg = reg ^ sum_poly;
为了清晰起见,给出完整的代码:
- // 以4 byte数据为例
- #define POLY 0xEDB88320L // CRC32生成多项式
- unsigned int CRC32_2(unsigned int data)
- {
- unsigned char p[8];
- memset(p, 0, sizeof(p));
- memcpy(p, &data, 4);
- unsigned int reg = 0, sum_poly = 0;
- for(int i = 0; i < 8; i++)
- {
- // 计算步骤1
- sum_poly = reg&0xFF;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x01; // 测试reg最高位
- sum_poly >>= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- // 计算步骤2
- reg = (reg<<8)|p[i];
- reg = reg ^ sum_poly;
- }
- return reg;
- }
依旧像上面的思路,把计算sum_poly的代码段提取出来,生成256个元素的CRC校验表,再修改追加0的逻辑,最终的代码版本就完成了,为了对比;后面给出了字节序逆转前的完整代码段。
- // 字节逆转后的CRC32算法,字节序为b1,b2,…,b8
- #define POLY 0xEDB88320L // CRC32生成多项式
- static unsigned int crc_table[256];
- unsigned int get_sum_poly(unsigned char data)
- {
- unsigned int sum_poly = data;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x01; // 取得reg的最高位
- sum_poly >>= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- return sum_poly;
- }
- void create_crc_table()
- {
- for(int i = 0; i < 256; i++)
- {
- crc_table[i] = get_sum_poly(i&0xFF);
- }
- }
- unsigned int CRC32_4(unsigned char* data, int len)
- {
- unsigned int reg = 0; // 0xFFFFFFFF,见后面解释
- for(int i = 0; i < len; i++)
- {
- reg = (reg<<8) ^ crc_table[(reg&0xFF) ^ data[i]];
- return reg;
- }
- }
- // 最终生成的校验表将是:
- // {0x00000000, 0x77073096, 0xEE0E612C, 0x990951BA,
- // 0x076DC419, 0x706AF48F, 0xE963A535, 0x9E6495A3,
- // … …}
- // 字节逆转前的CRC32算法,字节序为b8,b7,…,b1
- #define POLY 0x04C11DB7L // CRC32生成多项式
- static unsigned int crc_table[256];
- unsigned int get_sum_poly(unsigned char data)
- {
- unsigned int sum_poly = data;
- sum_poly <<= 24;
- for(int j = 0; j < 8; j++)
- {
- int hi = sum_poly&0x80000000; // 取得reg的最高位
- sum_poly <<= 1;
- if(hi) sum_poly = sum_poly^POLY;
- }
- return sum_poly;
- }
- void create_crc_table()
- {
- for(int i = 0; i < 256; i++)
- {
- crc_table[i] = get_sum_poly(i&0xFF);
- }
- }
- unsigned int CRC32_4(unsigned char* data, int len)
- {
- unsigned int reg = 0;// 0xFFFFFFFF,见后面解释
- for(int i = 0; i < len; i++)
- {
- reg = (reg<<8) ^ crc_table[(reg>>24)&0xFF ^ data[i]];
- return reg;
- }
- }
长征结束了
到这里长征终于结束了,事实上,还有最后的一小步,那就是reg初始值的问题,上面的算法中reg初始值为0。在一些传输协议中,发送端并不指出消息长度,而是采用结束标志,考虑下面的这几种可能的差错:
1)在消息之前,增加1个或多个0字节;
2) 在消息(包括校验码)之后,增加1个或多个0字节;
显然,这几种差错都检测不出来,其原因就是如果reg=0,处理0消息字节(或位),reg的值保持不变。解决这种问题也很简单,只要使reg的初始值非0即可,一般取0Xffffffff,就像你在很多CRC32实现中发现的那样。
到这里终于可以松一口气了,CRC32并不是像想象的那样容易的算法啊!事实上还真不容易!这就叫做“简单的前面是优雅,背后是复杂”!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









