






3 Achievements
3.成就
In this section we will sketch in broad terms the state of the art in building systems for generalization and recognition. In practical applications it is not the primary goal to study the way of bridging the gap between observations and concepts in a scientific perspective. Still, we can learn a lot from the heuristic solutions that are created to assist the human analyst performing a recognition task. There are many systems that directly try to imitate the decision making process of a human expert, such as an operator guarding a chemical process, an inspector supervising the quality of industrial production or a medical doctor deriving a diagnosis from a series of medical tests. On the basis of systematic interviews the decision making can become explicit and imitated by a computer program: an expert system [54]. The possibility to improve such a system by learning from examples is usually very limited and restricted to logical inference that makes the rules as general as possible, and the estimation of the thresholds on observations. The latter is needed as the human expert is not always able to define exactly what he means, e.g. by ‘an unusually high temperature’.
在这节里我们将主要介绍推广和识别方面的系统构建的发展状况。在实际应用中,并不是主要研究在科学方法上如何把观察数据和概念联系起来,但是我们仍然可以从分析人类识别过程中得到很多启发。有很多系统直接地模仿专家的决策过程,如确保化学处理的正确操作,工业产品质量的监督,从一系列医学检查报告的病情诊断。分析这些决策的目标是要能够被计算机程序清楚表达和模仿:专家系统。从用例学习中来提高这个系统的可靠性,通常受限于和取决于运用逻辑推理,但逻辑推理能够使得规则尽可能地具有推广性,还有对观察数据的阀值估计也是很难的,专家所表达的意思总是无法被精确表示,例如“一个非常高的温度”。
In order to relate knowledge to observations, which are measurements in automatic systems, it is often needed to relate knowledge uncertainty to imprecise, noisy, or generally invalid measurements. Several frameworks have been developed to this end, e.g. fuzzy systems [74], Bayesian belief networks[42] and reasoning under uncertainty [82]. Characteristic for these approaches is that the given knowledge is already structured and needs explicitly defined parameters of uncertainty. New observations may adapt these parameters by relating them to observational frequencies. The knowledge structure is not learned; it has to be given and is hard to modify. An essential problem is that the variability of the external observations may be probabilistic, but the uncertainty in knowledge is based on ‘belief’ or ‘fuzzy’ definitions. Combining them in a single mathematical framework is disputable [39].
在观察数据方面,这些数据从自动系统中测量得到,这里经常要考虑到数据不可靠性,如数据不精确,存在噪音,或者测量方法有问题。已有几个较为系统的方法解决了这些问题,如模糊理论,贝叶斯置信网络和不确定性推理,这些方法的特点是这些理论已自成体系,需要明确定义与不确定性有关的参数,通过观察发现的频率可以解决这些参数问题。这种识别方法是不需要学习的,方法一经确定下来就难以被修改。一个本质的问题是外在观察的变数是随机的,但是观察数据不可靠性却是用“概率”或“模糊”来表示,把它们组合到一个单一的数学框架下来实现是不太可能的。
In the above approaches either the general knowledge or the concept underlying a class of observations is directly modeled. In structural pattern recognition [26, 65] the starting point is the description of the structure of a single object. This can be done in several ways, e.g. by strings, contour descriptions, time sequences or other order-dependent data. Grammars that are inferred from a collection of strings are the basis of a syntactical approach to pattern recognition [26]. The incorporation of probabilities, e.g. needed for modeling the measurement noise, is not straightforward. Another possibility is the use of graphs. This is in fact already a reduction since objects are decomposed into highlights or landmarks, possibly given by attributes and also their relations, which may be attributed as well. Inferring a language from graphs is already much more difficult than from strings. Consequently, the generalization from a set of objects to a class is usually done by finding typical examples, prototypes, followed by graph matching [5, 78] for classifying new objects.
上面所谈到的方法,不管是一般化的知识还是对所观察到的数据进行概念性定义都是直接建模形式。而结构模式识别则起始于对单一对象的结构描述。这些描述形式有句子,轮廓描述,时序或其它有序的数据,从收集到的句子中进行推理得到的文法是运用上下文进行模式识别的基础。运用概率方法(因为测量中噪音的存在)并不是直接的建模方法。另一个可能用到的方法是运用图像比较,但自从采用把识别对象分解成各个特征或有意义的区域后这个方法实际上已较少被采用,而是采用图像的特征和特征之间的关系,这些关系也能一样地被用于识别中。从图像中发现语言种类比从句子中发现语言种类要困难得多。因此,从一个类别的一组对象进行推广通常被用来识别典型对象或原型,对于新的对象则采用图像匹配的方法来识别。
Generalization in structural pattern recognition is not straightforward. It is often based on the comparison of object descriptions using the entire available training set (the nearest neighbor rule) or a selected subset (the nearest prototype rule). Application knowledge is needed for defining the representation(strings, graphs) as well as for the dissimilarity measure to perform graph matching [51, 7]. The generalization may rely on an analysis of the matrix of dissimilarities, used to determine prototypes. More advanced techniques using the dissimilarity matrix will be described later.
结构模式识别中的推广无法直接进行,经常在可用整个训练集(采用最邻近法则)或其中一个子集(采用最邻近原型法则)采用对象描述比较方法。应用技术中需要确定表示方法(句子,图像),例如图像匹配时怎么确定图像间的不同点。推广可能依赖于对相异矩阵的分析,以此来确定原型。对于相异矩阵的更深层次应用将在后面介绍。
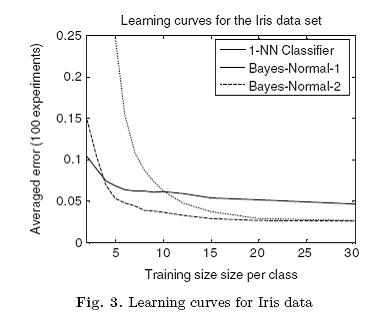
The 1-Nearest-Neighbor Rule (1-NN) is the simplest and most natural classification rule. It should always be used as a reference. It has a good asymptotic performance for metric measures [10, 14], not worse than twice the Bayes error, i.e. the lowest error possible. It works well in practice for finite training sets. Fig. 3 shows how it performs on the Iris data set in comparison to the linear and quadratic classifiers based on the assumption of normal distributions [27]. The k-NN rule, based on a class majority vote over the k nearest neighbors in the training set, is, like the Parzen classifier, even Bayes consistent. These classifiers approximate the Bayes error for increasing training sets [14, 27].
1-最邻近法则(1-NN)是最简单和最为自然的分类法则。这个方法应当会总被考虑到。在距离度量中具有很好的渐近性能,不会超过最低贝叶斯错误率的两倍。在有限训练集中这个方法效果很好。如图3则是这个方法在Iris数据集中的应用结果图,并且跟线性二次分类方法作了比较,这个图假定是在一般条件下测试得到。K-NN是训练集中根据K维最邻近原则来判定的分类法则,如Parzen分类器,甚至跟贝叶斯方法具有一致性。这些分类器在下图中随着测试集增大而其贝叶斯错误率被估算出来。
However, such results heavily rely on the assumption that the training examples are identically and independently drawn (iid) from the same distribution as the future objects to be tested. This assumption of a fixed and stationary distribution is very strong, but it yields the best possible classifier. There are, however, other reasons, why it cannot be claimed that pattern recognition is solved by these statistical tools. The 1-NN and k-NN rules have to store the entire training set. The solution is thereby based on a comparison with all possible examples, including ones that are very similar, and asymptotically identical to the new objects to be recognized. By this, a class or
a concept is not learned, as the decision relies on memorizing all possible instances. There is simply no generalization.
然而,上面的结果严重依赖于这样的假设:训练用例是在相同属性上被测试时具有独立同分布性(iid)。这个固定不变的属性假设是十分必要的,它是分类器最好效果的保证。然而,这个也是为什么不能认为模式识别是统计分析工具应用的原因。1-NN和k-NN规则需要保存整个训练集,通过比较所有可能样例来进行识别,甚至十分相似的样例也要进行比较,渐近地识别出新的对象。这种方法中不用学习类别和概念,分类方法依赖于所保存的所有实例,这种方法简单但不具有推广性。
Other classification procedures, giving rise to two learning curves shown in Fig. 3, are based on specific model assumptions. The classifiers may perform well when the assumptions hold and may entirely fail, otherwise. An important observation is that models used in statistical learning procedures have almost necessarily a statistical formulation. Human knowledge, however, certainly in daily life, has almost nothing to do with statistics. Perhaps it is hidden in the human learning process, but it is not explicitly available in the context of human recognition. As a result, there is a need to look for effective model assumptions that are not phrased in statistical terms.
图3中的另两条学习曲线所表示的两个分类方法是基于特定的模型假设,在满足所定假设情况下分类器性能表现不错,否则可能是相反的结果。一个重要的方面是这个模型是运用统计学习的方法,大都必须拥有一个统计公式。然而人类日常生活中的认知是几乎不会运用统计方法的,也许这是隐藏在人类的学习过程中,但在人类对上下文识别中确实是没用到的。因此,有必有去寻找不用统计方法来进行有效识别的方法。
In Fig. 3 we can see that a more complex quadratic classifier performs initially worse than the other ones, but it behaves similarly to a simple linear classifier for large training sets. In general, complex problems may be better solved by complex procedures. This is illustrated in Fig. 4, in which the resulting error curves are shown as functions of complexity and training size.
从图3我们可以看出更复杂的二次分类器在开始时性能比其它要差,但在大训练集中类似于线性分类器。一般情况下复杂的问题用复杂的方法来识别效果较好,这个可以在图4中得到说明,图4中的曲线表示错误率跟功能复杂度和训练集大小的关系。

Like in Fig. 3, small training sets require simple classifiers. Larger training sets may be used to train more complex classifiers, but the error will increase, if pushed too far. This is a well-known and frequently studied phenomenon in relation to the dimensionality (complexity) of the problem. Objects described by many features often rely on complex classifiers, which may thereby lead to worse results if the number of training examples is insufficient. This is the curse of dimensionality, also known as the Rao’s paradox or the peaking phenomenon [44, 45]. It is caused by the fact that the classifiers badly generalize,due to a poor estimation of their parameters or their focus/adaptation to the noisy information or irrelevant details in the data. The same phenomenon can be observed while training complex neural networks without taking proper precautions. As a result, they will adapt to accidental data configurations, hence they will overtrain. This phenomenon is also well known outside the pattern recognition field. For instance, it is one of the reasons one has to be careful with extensive mass screening in health care: the more diseases and their relations are considered (the more complex the task), the more people will we be unnecessarily sent to hospitals for further examinations.
由图3可知对于小的训练集可用较为简单的分类器,训练集越大则分类器可能需要越复杂,但是如果太大了则错误率会随之上升,这是众所周知的,即与经常被研究的问题维度(复杂度)有关。由于分类器的复杂,识别对象经常用很多特征来描述,如果测试用例没有足够多可能会导致更坏的结果,这就是所谓的维数灾难,也称为Rao悖论或峰值现象。这是由于分类器的推广性差造成的,这是由于对参数估计的偏差或考虑到数据中的噪音或不相关信息所产生的。如果不去预防这种情况的产生,训练复杂的神经网络也会出现这种现象。由此,为了去适配那些特殊而意外的数据导致产生了过学习。过学习在模式识别领域外的其它研究中也是较为常见的,例如这也是一个人在担心他的健康过程中会去经常拍片的原因:病人越不安及他们的亲人越关心(问题越复杂),其实越是不需要做更多的检查。
An important conclusion from this research is that the cardinality of the set of examples from which we want to infer a pattern concept bounds the complexity of the procedure used for generalization. Such a method should be simple if there are just a few examples. A somewhat complicated concept can only be learnt if sufficient prior knowledge is available and incorporated in such a way that the simple procedure is able to benefit from it.
这方面的研究得到一个重要的结论:我们从用例中推断得到模式概念,用例集的数量决定了推广过程的复杂度。如果只是一些用例,则这样的方法会较简单。如果有充足的先验知识可被用上且有适当方法来运用上,则用简单的方法就可以实现,稍微复杂的概念也能够被学习出来。
An extreme consequence of the lack of prior knowledge is given by Watanabe as the Ugly Duckling Theorem [75]. Assume that objects are described by a set of atomic properties and we consider predicates consisting of all possible logic combinations of these properties in order to train a pattern recognition system. Then, all pairs of objects are equally similar in terms of the number of predicates they share. This is caused by the fact that all atomic properties, their presence as well as their absence, have initially equal weights.As a result, the training set is of no use. Summarized briefly, if we do not know anything about the problem we cannot learn (generalize and/or infer) from observations.
一个缺乏先验知识的极端结论是Watanabe的丑小鸭定理(Ugly Duckling Theorem)[75].假设对象被描述成一个原子性质集,对这些性质进行所有可能的逻辑合并,合并后再进行组合成对象的属性,以此来训练一个模式识别系统。于是任何一对对对象在一些共有的属性上是同等相似的。这是由于对于所有原子性质,跟对象的存在与否无关,初始时二者都具有一样的权值。由此,这里训练集是没有用的。简要地总结一下,就是如果我们对这个问题什么都不了解,我们不可能从观察中学会(推广或推导)。
An entirely different reasoning pointing to the same phenomenon is the No-Free-Lunch Theorem formulated by Wolpert [81]. It states that all classifiers perform equally well if averaged over all possible classification problems.This also includes a random assignment of objects to classes. In order to understand this theorem it should be realized that the considered set of all possible classification problems includes all possible ways a given data set can be distributed over a set of classes. This again emphasizes that learning cannot be successful without any preference or knowledge.
对这相同现象有一个完全不同的论证:Wolpert的没有免费的午餐定理(No-Free-Lunch Therorem)[81]。他指出如果平衡所有可能的分类问题,则所有的分类器的性能是一样的,这也包括指对一个随机的分类方法。要理解这个定理则必须明白:对于所有可能的分类问题,包括所有的可能分类方法,总有一组数据可以被用于对一组类别的识别。这又强调了没有进行优化选择或缺少先验知识,这样的学习是不会成功的。
In essence, it has been established that without prior or background knowledge,no learning, no generalization from examples is possible. Concerning specific applications based on strong models for the classes, it has been shown that additional observations may lower the specified gaps or solve uncertainties in these models. In addition, if these uncertainties are formulated in statistical terms, it will be well possible to diminish their influence by a statistical analysis of the training set. It is, however, unclear what the minimum prior knowledge is that is necessary to make the learning from examples possible.This is of interest if we want to uncover the roots of concept formation, such as learning of a class from examples. There exists one principle, formulated at the very beginning of the study of automatic pattern recognition, which may point to a promising direction. This is the principle of compactness [1], also phrased as a compactness hypothesis. It states that we can only learn from examples or phenomena if their representation is such that small variations in these examples cause small deviations in the representation. This demands that the representation is based on a continuous transformation of the real world objects or phenomena. Consequently, it is assumed that a sufficiently small variation in the original object will not cause the change of its class membership. It will still be a realization of the same concept. Consequently,we may learn the class of objects that belong to the same concept by studying the domain of their corresponding representations.
实质上,没有先验或背景知识,从用例中进行学习或推广是不可能的,这点已被证实。关于以强大分类模型为基础的特定方向应用,已被表明通过观察数据可以减小某些方面的识别差距或者解决模型中的不确定问题。还有,如果是统计方法中的不确定问题,则通过对训练数据的统计分析可能可以很好地减少不确定问题造成的影响。然而,无法确定的是什么样的最小化先验知识对于从用例中实现学习是必须的,这对于我们揭示概念信息的根本是有用的,如从用例中学习某个分类。存在这样一个法则:这个法则叫紧性法则,或称紧性假设,在研究自动化模式识别的刚开始阶段,对各种有利于识别的知识进行整理,这个法则认为如果用例之间存在小的差异,但结果对用例的表示也偏差不大,对这样的表示方法我们只能从用例或现象中进行学习分类方法。对于现实世界中连续变化的对象或现象,用紧性来表示是必要的。因此,可以假定原始对象非常小的变化不会导致其分类归属的变化,仍将属于同一个概念。因此,通过研究分类对象相应的主要属性,我们可以进行学习以实现地属于同一概念的对象的分类方法。
The Ugly Duckling Theorem deals with discrete logical representations.These cannot be solved by the compactness hypothesis unless some metric is assumed that replaces the similarity measured by counting differences in predicates.The No-Free-Lunch Theorem clearly violates the compactness assumption as it makes object representations with contradictory labelings equally probable. In practice, however, we encounter only specific types of problems.
丑小鸭原理是用于处理离散的逻辑表示问题。离散的逻辑表示问题无法用紧性假设来解决,除非一些度量方法如相似度用差异个数来表示。没有免费的午餐原理明显违反了紧性假设:它用对立的等概率来表示对象。然而,实践中我们碰到的只是些特定种类的问题。
Building proper representations has become an important issue in pattern recognition [20]. For a long time this idea has been restricted to the reduction of overly large feature sets to the sizes for which generalization procedures can produce significant results, given the cardinality of the training set. Several procedures have been studied based on feature selection as well as linear and nonlinear feature extraction [45]. A pessimistic result was found that about any hierarchical ordering of (sub)space separability that fulfills the necessary monotonicity constraints can be constructed by an example based on normal distributions only [11]. Very advanced procedures are needed to find such ‘hidden’ subspaces in which classes are well separable [61]. It has to be doubted, however, whether such problems arise in practice, and whether such feature selection procedures are really necessary in problems with finite sample sizes. This doubt is further supported by an insight that feature reduction procedures should rely on global and not very detailed criteria if their purpose is to reduce the high dimensionality to a size which is in agreement with the given training set.
建立一个合适的表示方法成为模式识别中一个重要的问题。很长一段时间来这方面的考虑仅限于对太大特征集尺寸的缩小,给定训练集的势,大尺寸的特征集具有较好的推广性。已有几种方法可用于特征的选择,如线性和非线性特征提取[45]。有一个让人悲观的结论:如果满足单调性约束的特征空间(或子空间)可分离性,则可以只通过某个用例在普通的属性上进行等级化地排序。然而,这不得不让人怀疑在实践中这样的问题是否会出现,这样的特征选择方法对于有限的样本大小是否真的需要。更让人引起怀疑的原因是这样的一个观点:如果是为了减小从给定训练集中得出来的高维空间的维数,特征减少方法应当在全局上进行,而不是依赖于一个非常详细的标准。
Feed-forward neural networks are a very general tool that, among others, offer the possibility to train a single system built between sensor and classification [4, 41, 62]. They thereby cover the representation step in the input layer(s) and the generalization step in the output layer(s). These layers are simultaneously optimized. The number of neurons in the network should be sufficiently large to make the interesting optima tractable. This, however,brings the danger of overtraining. There exist several ways to prevent that by incorporating some regularization steps in the optimization process. This replaces the adaptation step in Fig. 1. A difficult point here, however, is that it is not sufficiently clear how to choose regularization of an appropriate strength.The other important application of neural networks is that the use of various regularization techniques enables one to control the nonlinearity of the resulting classifier. This gives also a possibility to use not only complex, but also moderately nonlinear functions. Neural networks are thereby one of the most general tools for building pattern recognition systems.
前向式反馈神经网络是一个非常流行的工具,可以实现在感应器和分类之间通过训练建立一个识别系统[4,41,62]。这个系统包括输入层的表示过程和输出层的推广过程。输入层和输出层同时可以被进行优化。神经网络中的神经个数必须足够多以达到所需要的性能要求,不过,也有可能会导致过学习,有几个方法可以防止产生过学习,在优化过程中综合一些调整方法,如图1中的适应性修改步骤就可以达到这个目的,有个困难是还不十分清楚怎么去选择可以产生更好效果的调整方法。神经网络其它重要的应用是可以用各种调整技术来控制分类器分类的非线性,可以选择复杂的函数,也可以选择非线性函数。神经网络在建立模式识别系统中成为最为流行的工具之一。
In statistical learning, Vapnik has rigorously studied the problem of adapting the complexity of the generalization procedure to a finite training set[72, 73]. The resulting Vapnik-Chervonenkis (VC) dimension, a complexity measure for a family of classification functions, gives a good insight into the mechanisms that determine the final performance (which depends on the training error and the VC dimension). The resulting error bounds, however,are too general for a direct use. One of the reasons is that, like in the No-Free-Lunch Theorem, the set of classification problems (positions and labeling of the data examples) is not restricted to the ones that obey the compactness assumption.
在统计学习中,Vapnik严密解决了在有限训练集中进行推广过程的复杂度衡量问题,定义了一个VC维概念(Vapnik-Chervonenkis),一个对分类泛函复杂度的度量方法,对于最后的性能分析提供了一个很好方法(根据训练错误率和VC维)。然而,直接用错误边界来进行识别是非常通用了。其中的一个原因是就如没有免费的午餐原理,分类问题(位置和用例数据标识)集不服从紧性假设。
One of the insights gained by studying the complexity measures of polynomial functions is that they have to be as simple as possible in terms of the number of their free parameters to be optimized. This was already realized by Cover in 1965 [9]. Vapnik extended this finding around 1994 to arbitrary non-linear classifiers [73]. In that case, however, the number of free parameters is not necessarily indicative for the complexity of a given family of functions,but the VC dimension is. In Vapnik’s terms, the VC dimension reflects the flexibility of a family of functions (such as polynomials or radial basis functions)to separate arbitrarily labeled and positioned n-element data in a vector space of a fixed dimension. This VC dimension should be finite and small to guarantee the good performance of the generalization function.
有一个观点:在研究多项式函数复杂度度量中发现,多项式函数复杂度可以简单地用要被优化的自由参数个数来衡量。Cover于1965年就已经发现了这个问题。Vapnik约在1994年左右把这个发现应用到任意非线性分类器中,然而,在那里他认为用自由参数的数目来度量一个函数集的复杂度是不必要的,而应该用VC维。在Vapnik描述中,VC维反映了一个函数集(诸如多项式函数或径基函数)的适应性,这个函数集用来在一个固定维数的特征空间中分开已被标识和被确定好位置的n-元数据。VC维应当是有限而且小以确保具有好的推广性。
This idea was elegantly incorporated to the Support Vector Machine (SVM) [73], in which the number of parameters is as small as a suitably determined subset of the training objects (the support vectors) and into independent of the dimensionality of the vector space. One way to phrase this principle is that the structure of the classifier itself is simplified as far as possible (following the Occam’s razor principle). So, after a detor along huge neural networks possibly having many more parameters than training examples, pattern recognition was back to the small-is-beautiful principle, but now better understood and elegantly formulated.
这个思想被完美地运用到支持向量机(SVM)中,SVM中用于划分训练对象的参数个数(支持向量)很少,且不依赖于向量空间的维数。SVM方法可以说是把分类器结构尽可能地简化(遵从Occam剃刀原则)。所以在绕过具有比训练用例还多的参数的巨大神经网络系统后,模式识别又回到了“小而美”的原则,且现在已能够更好的理解和完美地形式化这个原则。
The use of kernels largely enriched the applicability of the SVM to nonlinear decision functions [66, 67, 73]. The kernel approach virtually generates nonlinear transformations of the combinations of the existing features. By using the representer theorem, a linear classifier in this nonlinear feature space can be constructed, because the kernel encodes generalized inner products of the original vectors only. Consequently, well-performing nonlinear classifiers built on training sets of almost any size in almost any feature space can be computed by using the SVM in combination with the ‘kernel trick’ [66].
核的应用大大地丰富了SVM在非线性分类器中的适用性。核方法实质是对特征空间的整体非线性变换。根据SVM所陈述的定理,在非线性特征空间可以建立一个线性分类器,因为核函数对原始特征向量进行了变换使之线性可分。因此,在任何特征空间尺度上的训练集中,SVM都可以发挥其很好的非线性分类性能,在此核函数是必不可少的。
This method has still a few limitations, however. It was originally designed for separable classes, hence it suffers when high overlap occurs. The use of slack variables, necessary for handling such an overlap, leads to a large number of support vectors and, consequently, to a large VC dimension. In such cases,other learning procedures have to be preferred. Another difficulty is that the class of admissible kernels is very narrow to guarantee the optimal solution.A kernel K has to be (conditionally) positive semidefinite (cpd) functions of two variables as only then it can be interpreted as a generalized inner product in reproducing kernel Hilbert space induced by K. Kernels were first considered as functions in Euclidean vector spaces, but they are now also designed to handle more general representations. Special-purpose kernels are defined in a number of applications such as text processing and shape recognition, in which good features are difficult to obtain. They use background knowledge from the application in which similarities between objects are defined in such a way that a proper kernel can be constructed. The difficulty is, again, the strong requirement of kernels as being cpd.
然而,SVM方法仍存在一些局限性。SVM原来是用于对象可分的分类中,因此当分类对象交迭严重时SVM方法就不适用了。就是运用处理对象交迭的松驰变量,也会导致产生大量的支持向量,由此产生VC维很大。这种情况下,最好采用其它的学习方法。另一个会导致的困难是能保证理想分类功能的可用的核函数很少。一个K核函数必须是两个变量的半正定(cpd)函数,只有这样的函数才能在Hilbert空间中应用。核函数初始被认为是欧几里得向量空间中的函数,但现在核函数已被应用在了更具一般性的表示方法。特定功能的核函数被用在了不同应用中,如文本处理和形状识别,这些应用中较难得到好的特征。对象间的相似性被定义了出来,依此运用应用背景知识就可以定义出适宜的核函数。这里的困难还是核函数必须是半正定的。
The next step is the so-called dissimilarity representation [56] in which general proximity measures between objects can be used for their representation.The measure itself may be arbitrary, provided that it is meaningful for the problem. Proximity plays a key role in the quest for an integrated structural and statistical learning model, since it is a natural bridge between these two approaches [6, 56]. Proximity is the basic quality to capture the characteristics of a set objects forming a group. It can be defined in various ways and contexts, based on sensory measurements, numerical descriptions, sequences, graphs, relations and other non-vectorial representations, as well as their combinations. A representation based on proximities is, therefore,universal.
下个步骤就是所谓的相异点表示法[56],对象间的一般相似性度量方法可以代替相异点表示法。度量方法本身可以是任意的,只要是能够解决问题就可以了。接近度在集成结构模式识别方法和统计学习方法中起着关键性的角色,在两个方法之间架起了一个天然桥梁[6,56]。在同一类的一组对象中获取其特征,接近度是一个基本考量方法。接近度可以用各种方法和上下文来定义,取决于感观度量、数字化描述、序列、图表、关联和其它的非向量表示法,也取决于于其中的组合方法。所以基于接近度的表示法是通用的。
Although some foundations are laid down [56], the ways for effective learning from general proximity representations are still to be developed. Since measures may not belong to the class of permissable kernels, the traditional SVM, as such, cannot be used. There exist alternative interpretations of indefinite kernels and their relation to pseudo-Euclidean and Krein spaces[38, 50, 55, 56, 58], in which learning is possible for non-Euclidean representations.In general, proximity representations are embedded into suitable vector spaces equipped with a generalized inner product or norm, in which numerical techniques can either be developed or adapted from the existing ones. It has been experimentally shown that many classification techniques may perform well for general dissimilarity representations.
虽然已有了一些理论基础,从接近度表示法来提高学习有效性仍被研究中。既然这方法和分类中的核函数无关,传统的SVM方法就无法适用这种情况了。存在对不定核的替代表示方法,这跟欧几里得几何和Krein空间有关[38,50,55,56,58],通过这个方法可以实现非欧几里得表示法的学习。一般地,接近率表示法被嵌入到具有一般化内积或范数的相应向量空间中,这个向量空间可以被标量化或适应性修改后的标量化。通过实验已表明一般相异点的表示法在许多分类技术中可以表现出很好的性能。















 7212
7212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









