







Set不保存重复的元素,如果我们试图将相同对象的多个实例添加到Set中,编译器会阻止我们这样做。在Set中,最常被使用的功能是询问某个对象是否在某个Set中,所以查找成为了Set中一项最重要的操作,并且我们通常都会选择HashSet,因为它专门针对查找进行了优化。Set具有同Collection完全一样的接口,没有额外的功能,不像List有ArrayList和LinkedList两种,实际上Set就是Collection,只是行为不同,也就是说Set继承了Collection并采用多态形成了不同的方法。Set是基于对象的值来确定归属性的。看下面一段代码:
package access;
import java.util.*;
public class SetOfInteger {
public static void main(String[] args) {
// TODO Auto-generated method stub
Random rand = new Random(47);
Set<Integer> intset = new TreeSet<Integer>();
for(int i =0; i < 10000; i++)
intset.add(rand.nextInt(10));
System.out.println(intset);
}
}
在0到10之间的10000个随机数被添加到Set中,每个数都被重复了很多次,但出现在Set中的只有0到10之间的一个数。在后续的JAVA版本中对HashSet的输出顺序进行了改进,使得输出根据升序来排列,而这在早期的JAVA版本中并没有,早期的输出结果排序是错乱的。但是出于速度原因的考虑,HashSet使用了散列,HashSet所维护的顺序与TreeSet和LinkedHashSet都不同,TreeSet将元素存储到红-黑树数据结构当中;LinkedHashSet也使用了散列,但是它使用了链表来维护元素的插入顺序。

我们最常进行的操作之一是使用contains方法测试Set的归属性,看下面一段代码:
package access;
import java.util.*;
public class SetOperations {
public static void main(String[] args) {
// TODO Auto-generated method stub
Set<String> set1 = new HashSet<String>();
Collections.addAll(set1,
"A B C D E F G H I J K L".split(" "));
set1.add("M");
System.out.println("H:" + set1.contains("H"));
System.out.println("N:" + set1.contains("N"));
Set<String> set2 = new HashSet<String>();
Collections.addAll(set2, "H I J K L".split(" "));
System.out.println("set2 in set1:" + set1.containsAll(set2));
set1.remove("H");
System.out.println("set1: " + set1);
System.out.println("set2 in set1:" + set1.containsAll(set2));
set1.removeAll(set2);
System.out.println("set2 removed from set1:" + set1);
Collections.addAll(set1, "X Y Z".split(" "));
System.out.println("'X Y Z' added to set1: " + set1);
}
}
结果显而易见,其中的split方法用于分割并返回一个数组。
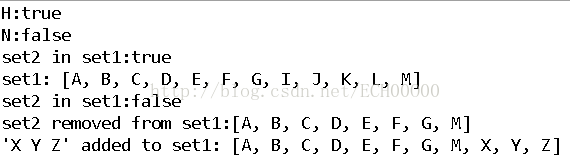














 1304
1304











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









