







 本文介绍协同过滤推荐算法,包括基于用户和基于物品两种方法。基于用户的协同过滤通过计算用户间的相似度来推荐物品,而基于物品的方法则通过计算物品间的相似度实现推荐。文中还展示了如何使用MovieLens数据集进行实践。
本文介绍协同过滤推荐算法,包括基于用户和基于物品两种方法。基于用户的协同过滤通过计算用户间的相似度来推荐物品,而基于物品的方法则通过计算物品间的相似度实现推荐。文中还展示了如何使用MovieLens数据集进行实践。
协同过滤(Collaborative Filtering)是推荐系统常用的算法。它包括User-based和Item-based两种基本算法。
1.基于用户(User-based)
基于用户的CF主要流程是:寻找相似的用户——推荐物品。寻找相似用户时,书中提供了欧几里德距离(Euclidean Distance)和皮尔逊相关系数(Pearson Correlation)两种度量。
1.1先在文件中存一些用户爱好数据。
critics = {'Lisa Rose': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.5, 'Just My Luck': 3.0, 'Superman Returns': 3.5, 'You, Me and Dupree': 2.5, 'The Night Listener': 3.0},
'Gene Seymour':{'Lady in the Water': 3.0, 'Snakes on a Plane': 3.5, 'Just My Luck': 1.5, 'Superman Returns': 5.0, 'The Night Listener':3.0, 'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5, 'Snakes on a Plane': 3.0, 'Superman Returns': 3.5, 'The Night Listener':4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5, 'Just My Luck': 3.0, 'Superman Returns': 4.0, 'The Night Listener':4.5, 'You, Me and Dupree': 2.5},
'Mick LaSalle':{'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0, 'Just My Luck': 2.0, 'Superman Returns': 3.0, 'The Night Listener':3.0, 'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0, 'Snakes on a Plane': 4.0,'The Night Listener':3.0, 'Superman Returns':5.0, 'You, Me and Dupree': 3.5},
'Toby':{ 'Snakes on a Plane': 4.5, 'Superman Returns': 4.0, 'You, Me and Dupree': 1.0}}
1.2寻找相似用户
1.2.1欧几里德距离(Euclidean Distance)
欧几里德空间中,两点x,y的距离计算公式:
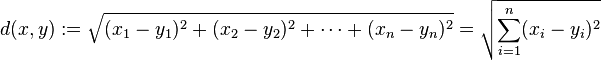
def sim_distance(prefs, person1, person2):
si = {}
for item in prefs[person1]:
if item in prefs[person2]:
si[item] = 1
if len(si) == 0:
return 0
sum_of_squares = sum([pow(prefs[person1][item]-prefs[person2][item],2) for item in si])
return 1/(1+sum_of_squares)1.2.2皮尔逊相关系数(Pearson Correlation)
计算公式:
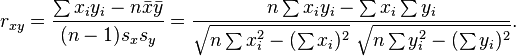
def sim_pearson(prefs, person1, person2):
s = {}
for item in prefs[person1]:
if item in prefs[person2]:
s[item] = 1
if len(s) == 0: return 0
sum1 = sum([prefs[person1][it] for it in s])
sum2 = sum([prefs[person2][it] for it in s])
sum1sq = sum([pow(prefs[person1][it], 2) for it in s])
sum2sq = sum([pow(prefs[person2][it], 2) for it in s])
sumofprod = sum([prefs[person1][it]*prefs[person2][it] for it in s])
num = sumofprod - (sum1*sum2/len(s))
den = sqrt((sum1sq - pow(sum1,2)/len(s))*(sum2sq - pow(sum2,2)/len(s)))
if den == 0:
return 0
r = num/den
return r定义了欧几里德距离和皮尔逊相关两种度量后,可以用这两种度量来寻找相似的用户。
def topMatches(prefs, person, n=5, similarity=sim_pearson):
scores = [(similarity(prefs, person, other), other) for other in prefs if other!=person]
scores.sort()
scores.reverse()
return scores[0:n]1.3推荐物品
推荐图品时,用(用户相似系数×物品评分)之和/(用户相似系数之和)。
比如,为Alice推荐电影。Bob与Alice的相似系数是0.6,对电影《Looper》的评分为3;Wendy与Alice的相似系数为0.8,对电影《Looper》的评分为4。则为Alice推荐电影《Looper》的指数为:(0.6*3+0.8*4)/(0.6+0.8)
def getRecommendations(prefs, person, similarity=sim_pearson):
totals = {}
simSums = {}
for other in prefs:
if other == person:
continue
sim = similarity(prefs, person, other)
if sim<=0:continue
for item in prefs[other]:
if item not in prefs[person] or prefs[person][item] == 0:
totals.setdefault(item,0)
totals[item] += prefs[other][item]*sim
simSums.setdefault(item,0)
simSums[item] += sim
rankings = [(total/simSums[item],item) for item,total in totals.items()]
rankings.sort()
rankings.reverse()
return rankings2.基于物品(Item-based)
基于用户的CF有它的局限性,比如:用户数量大的时候,计算用户之间的相似系数,然后又计算用户评价过的物品会比较慢。此外,物品数量很多的情况下,两个用户的交集就会很小,甚至完全没交集,数据集是稀疏的。为了解决这样的问题,可以采用基于物品的CF。对于像亚马逊这样的网站来说,销售的商品是相对比较固定的,可以预先计算物品之间的相似系数,然后根据用户的之前买过的物品进行推荐。
2.1建立物品比较数据集(Building the item comparison dataset)
#将数据集由用户主导转为物品主导
def transformPrefs(prefs):
result = {}
for person in prefs:
for item in prefs[person]:
result.setdefault(item,{})
result[item][person] = prefs[person][item]
return result
#构建相似物品数据集,默认为前10个相似物品
def calculateSimilarItems(prefs, n=10):
result = {}
itemPrefs = transformPrefs(prefs)
c = 0
for item in itemPrefs:
c += 1
if c % 100 == 0:
print "%4d / %4d" % (c,len(itemPrefs))
scores = topMatches(itemPrefs, item, n=n, similarity=sim_distance)
result[item] = scores
return result2.2推荐物品
def getRecommendedItems(prefs, itemMatch, user):
simSums = {}
recommend = {}
for filmwatched in prefs[user]:
for sim,film in itemMatch[filmwatched]:
if film in prefs[user]:
continue
recommend.setdefault(film,0)
recommend[film] += prefs[user][filmwatched] * sim
simSums.setdefault(film,0)
simSums[film] += sim
result = [(recommend[item]/simSums[item],item) for item in recommend]
result.sort()
result.reverse()
return result这样就可以基于物品进行推荐:
>>> import recommendations
>>> prefs = recommendations.calculateSimilarItems(recommendations.critics)
>>> recommendations.getRecommendedItems(recommendations.critics, prefs, 'Toby')
[(3.182634730538922, 'The Night Listener'), (2.5983318700614575, 'Just My Luck'), (2.4730878186968837, 'Lady in the Water')]3.一个实例——使用MovieLens Dataset
最后用一个电影评分数据集来做一个比较有实际意义的推荐。数据集可以在这里下载MovieLens数据集 里面有电影评分,电影信息,用户信息等各种东西,Readme很详细第介绍了各个文件的内容格式。现在就可以从文件中构建数据库,也就是将数据存成类似上面的critics的形式,{用户:{电影1:评分,电影2:评分}}
def loadMoviLens(path=r'存放的路径\Dataset\ml-100k'):
film = {}
filminfo = open(path + r'\u.item')
for line in filminfo.readlines():
(id, title) = line.strip('\n').split('|')[0:2]
film[id] = title
filminfo.close()
prefs = {}
ratedata = open(path + r'\u.data')
for line in ratedata.readlines():
(user, filmid, rating, ts) = line.strip('\n').split('\t')
prefs.setdefault(user,{})
prefs[user][film[filmid]] = float(rating)
return prefs
import pickle
import recommendations as recmd
try:
prefs = recmd.loadMovieLens()
filmsim = recmd.calculateSimilarItems(prefs, n=50)
f = open(r'你存放的数据的路径','wb')
pickle.dump(filmsim, f)
except:
print 'Something wrong!'
else:
print 'Done building dataset!'
finally:
f.close()
>>> from pprint import pprint
>>> import recommendations
>>> prefs = recommendations.loadMoviesLen()
>>> pprint(prefs['87'])
{'2001: A Space Odyssey (1968)': 5.0,
'Ace Ventura: Pet Detective (1994)': 4.0,
'Addams Family Values (1993)': 2.0,
'Addicted to Love (1997)': 4.0,
.....}
>>> pprint(recommendations.getRecommendations(prefs,'87')[0:10])
[(5.0, 'They Made Me a Criminal (1939)'),
(5.0, 'Star Kid (1997)'),
(5.0, 'Santa with Muscles (1996)'),
(5.0, 'Saint of Fort Washington, The (1993)'),
(5.0, 'Marlene Dietrich: Shadow and Light (1996) '),
(5.0, 'Great Day in Harlem, A (1994)'),
(5.0, 'Entertaining Angels: The Dorothy Day Story (1996)'),
(5.0, 'Boys, Les (1997)'),
(4.89884443128923, 'Legal Deceit (1997)'),
(4.815019082242709, 'Letter From Death Row, A (1998)')]














 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









