






日前,有网友发微博称,外卖订单付款出现延迟,部分用户付款后系统仍提示尚未付款;团购页面内容也无法正常显示。美团服务器出现大面积崩溃。
网友趣谈:
1、这是一个上了热搜,并让大家吃不上午饭的 Bug。
2、饭点时间,遇到这种事情,也真的糟心了!而且,这种情况还不是个例,在微博上一搜,反映美团外卖这种情况的还真不少。
3、连续尝试付款了好多次,但是钱出去了,却既没有下成单,也没有退款。
4、想找美团外卖的客服咨询情况,但是却一直联系不上,无论是网上客服还是电话客服。
美团方面:
1、事件当日12:16 分美团微博回复:订单问题已修复,订单问题已修复,订单问题已修复。
2、12:28 分 APP 仍然处于宕机状态。下午12:43分,美团在微博上回应:经紧急修复后,现已陆续恢复,重复支付的订单会原路退回,系统故障期间未完成服务的订单,用户可以无责取消退款。
事件结果:
1、部分重复下单的网友已经获得了退款和美团的致歉红包;
2、此次事故对美团的工程师们来说,简直是年度灾难,很可能直接导致美团的程序员们错失丰厚年终奖的机会。
事实上,美团并非第一次出现类似的问题,据了解,12 月 5 日,美团外卖也出现了一次服务器崩溃事故,中午当用户点完餐,想要查看订单进度时,页面要么显示“系统处理异常”,要么是“订单不存在”,使得用户无法追踪自己的餐品配送进度。
网友对结果吐槽:
1、美团的程序员是不是饿了去吃饭了,忽视了系统的 Bug,还是被祭天了?是不是放寒假了?
2、饿了么安插在美团身边的程序员终于发力了。继暴风影音、虾米音乐后,又一程序员要被祭天了。
那么我们奋战在一线的程序员们
从“美团外卖”事件里
可以学到哪些经验呢?
这里将详细解析美团外卖运维过程中问题发现、根因分析、问题解决等自动化运维体系的建设历程与相关设计原则。
问题发现:业务流程复杂
用户在使用美团外卖 App 过程中涉及到的技术模块,历经用户下单-->系统发给商家-->商家准备外卖-->配送,到最后用户收到商品比如热乎乎的盒饭,整个过程的时间需要控制在半小时之内。
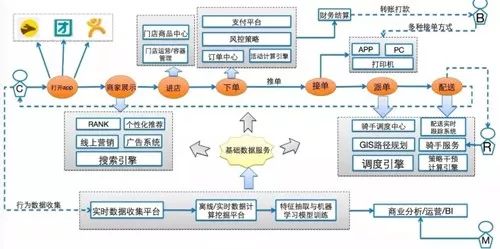
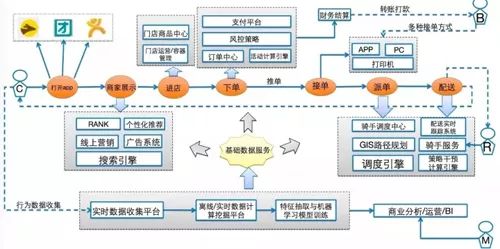
图1:用户角度的美团外卖技术体系
根因分析:需要解决问题
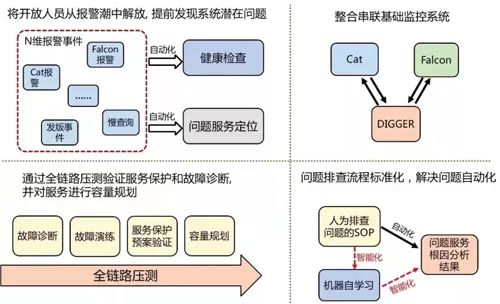
图 4:开发人员日常监控痛点
我们在日常的业务运维工作中经常会碰到一些问题困扰着开发人员,如图 4 所示。
四大主要痛点:
1、公司有多套监控系统,它们有各自的职责定位,但是互相没有关联,所以开发人员在排查问题时需要带着参数在不同的系统之间切换,这就降低了定位问题的效率。
2、事件通知、报警事件充斥着开发人员的 IM,我们需要花很多精力去配置和优化报警阈值、报警等级才不会出现很多误报。
3、开发人员收到各种报警之后,通常都会根据自己的经验进行问题的排查,这些排查经验完全可以标准化。
4、我们的代码中会有大量的降级限流开关,在服务异常时进行相应的保护操作。这些开关随着产品快速地迭代,我们并不能确定它们是否还有效。
问题解决一:通过一些自动化措施提升运维效率,触发服务保护有两条路径。
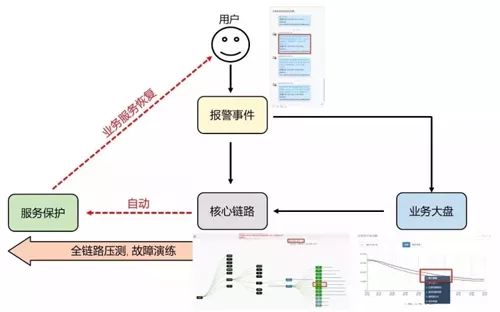
图 5:自动化业务运维系统核心建设目标
第一条,用户也可以直接通过诊断报警进入对应的核心链路,查看最终引起异常的根本原因,引导用户判断是否需要触发相应的服务保护预案。
第二条,当用户在前期接收到我们的诊断报警后,直接被引导进入该报警可能会影响到业务大盘。
问题解决二:开发产品,建设核心产品以及各个产品模块之间的关联。
1,业务大盘的预测报警、核心链路的红盘诊断报警以及已经收集到各个维度的报警事件,如果能对它们做进一步的统计分析,可以帮助开发人员从更加宏观的角度提前发现服务可能潜在的问题,相当于提前对服务做健康检查。
2、分析核心链路上服务状态,帮助开发人员定位最终的问题节点,并建议开发人员需要触发哪些服务保护预案。
3、我们需要定期通过全链路压测来不断验证问题诊断和服务保护是否有效,在压测时可以看到各个场景下的服务健康状态,对服务节点做到有效的容量规划。
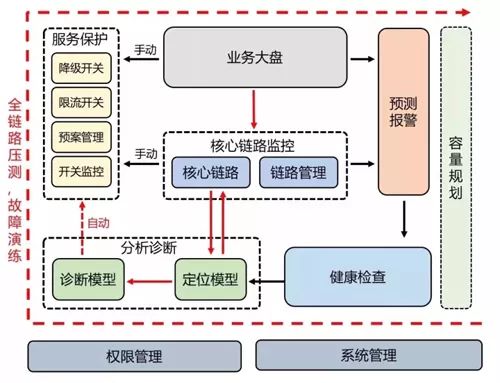
图 6:业务监控运维体系架构
问题解决三:业务监控大盘及拓展能力
1、当出现业务指标异常时,根据后台的监控数据分析,可以手动或者自动进行事件标记,告知开发人员是什么原因引起了业务指标的波动,做到用户信息量的快速同步。
2、可以带着时间戳与类型快速引导开发人员进入其他监控系统,提高开发人排查问题的效率。
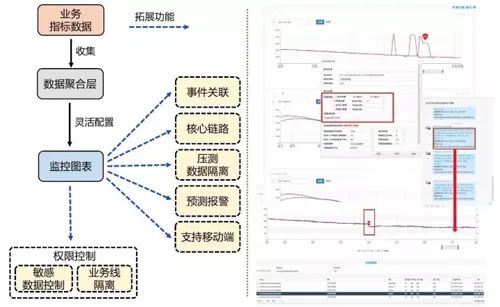
图 7:业务监控大盘及拓展能力
问题解决四:核心链路产品建设路径
1、我们需要给核心链路上的服务节点进行健康评分,根据评分模型来界定问题严重的链路。
2、这里我们会根据服务的各个指标来描绘一个服务的问题画像,问题画像中的指标也会有权重划分,比如:当服务出现了失败率报警、TP99 报警,大量异常日志则会进行高权重的加分。
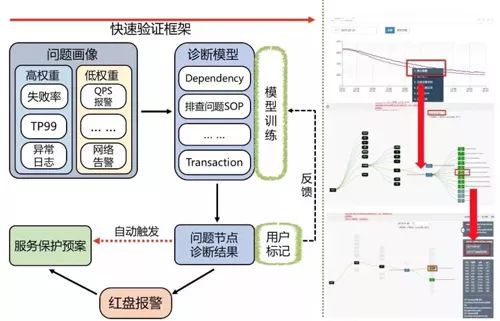
图 8:核心链路产品建设路径
问题解决五:服务保护&故障演练模块的核心功能
1、降级开关:由于业务快速发展,在代码中会有成百上千的降级开关。在业务出现异常时需要手动进行降级操作。
2、限流开关:有些针对特定业务场景需要有相应的限流保护措施。比如:针对单机限流主要是对自身服务器的资源保护,针对集群限流主要是针对底层的 DB 或者 Cache 等存储资源进行资源保护,还有一些其他限流需求都是希望可以在系统出现流量异常时进行有效地保护。
3、Hystrix自动熔断:可以通过监控异常数、线程数等简单指标,快速保护我们的服务健康状态不会急剧恶化。
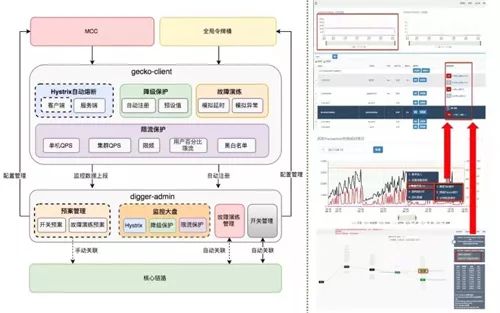
图 9:服务保护&故障演练模块的核心功能
问题解决六:提升全链路压测给我们带来的收益
1、定期组织外卖全链路压测,每次压测都会涉及很多人的配合,如果可以针对单一压测场景进行压测将会大大缩短我们组织压测的成本。
2、在全链路压测的时候,针对压测流量进行不同场景的故障演练,在制造故障的同时,验证服务保护预案是否可以像预期那样启动保护服务的目的。
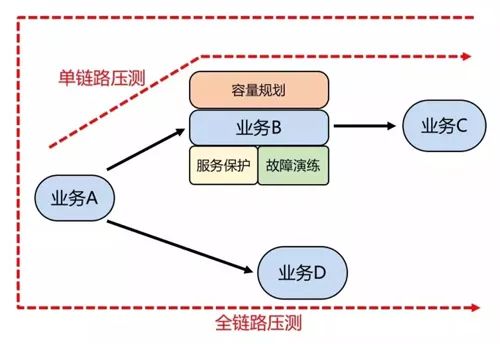
图 10:提升全链路压测给我们带来的收益
自动化路程
前面主要介绍了我们在做基于业务的运维系统时需要的各个核心功能,下面重点介绍一下,我们在整个系统建设中,自动化方面的建设主要集中在什么地方。
1、异常点自动检测
通过分析历史数据来自动的检测出异常点,并自动计算出应有的报警阈值并设置。
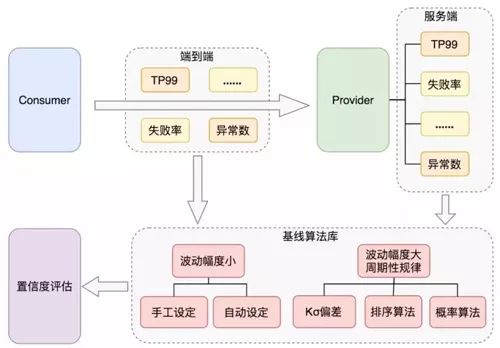
图 11:异常点自动检测
2、自动触发服务保护
根据各种监控指标准确的诊断出异常点,并事先将已经确定的异常场景与我们的服务保护预案进行关联,就可以自动化的进行服务保护预案的触发。
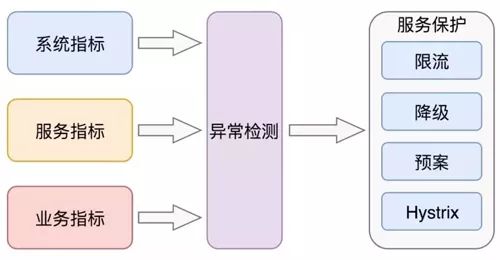
图 12:异常检测与服务保护联动
3、压测计划自动化
我们需要进行如下工作的准备:
针对真实流量的改造,基础数据构造、数据脱敏、数据校验等尽可能通过任务提前进行。
进入到流量回放阶段,我们可以针对典型的故障场景进行故障预案的触发(比如:Tair 故障等)。
在故障演练的同时,我们可以结合核心链路的关系数据准确定位出与故障场景强相关的问题节点。
结合我们针对典型故障场景事先建立的服务保护关系,自动触发对应的服务保护预案。
在整个流程中,我们需要最终确认各个环境的运行效果是否达到了我们的预期,就需要每个环节都有相应的监控日志输出,最终自动化产出最终的压测报告。
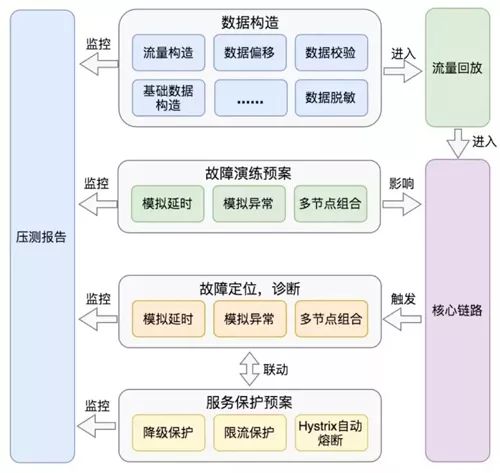
图 13:压测计划自动化
结语:自动化建设后期发力点
在整个业务运维系统建设中,只有更加准确定位问题根节点,诊断出问题根本原因才能逐步自动化去做一些运维动作(比如:触发降级开关,扩容集群等)。如图 14 所示,我们会在这些环节的精细化建设上进行持续投入,希望检测到任意维度的异常点,向上推测出可能会影响哪些业务指标,影响哪些用户体验;向下依托于全链路压测可以非常准确的进行容量规划,节省资源。
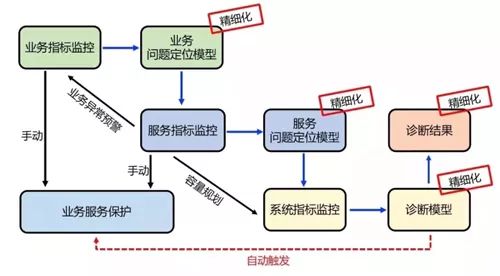
图 14:自动化建设后期发力点
公众号内回复“1”带你进粉丝群!















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









