






Hadoop 生态圈组件介绍
Hadoop是目前应用最为广泛的分布式大数据处理框架,其具备可靠、高效、可伸缩等特点。
Hadoop的核心组件是HDFS、MapReduce。随着处理任务不同,各种组件相继出现,丰富Hadoop生态圈,目前生态圈结构大致如图所示:
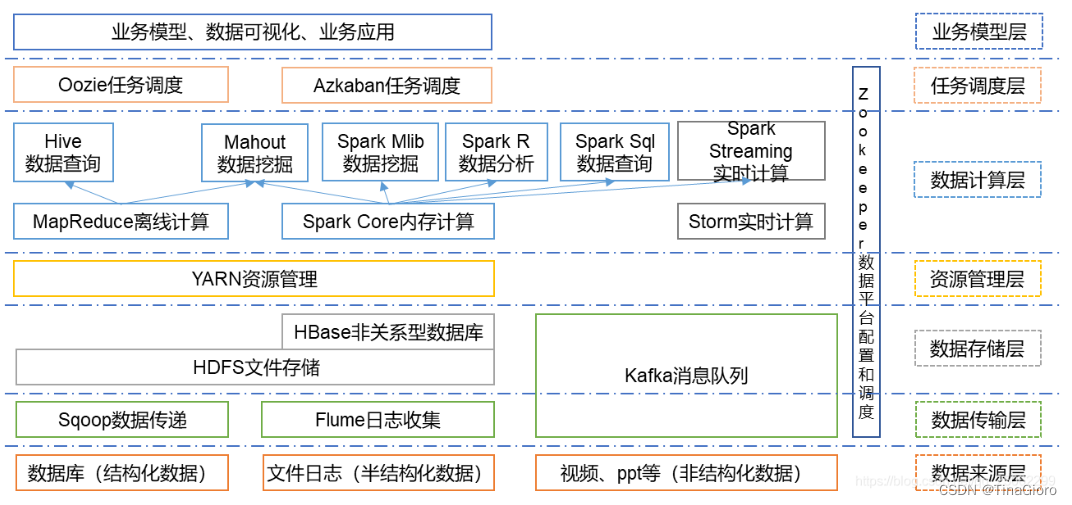 Storm已流行用Flink代替
Storm已流行用Flink代替
由于Google没有开源,所以其他互联网公司根据Google三篇论文中提到的原理,对照MapReduce搭建了Hadoop ,对照GFS搭建了HDFS ,对照BigTable搭建了HBase.
· 分布式计算框架 MapReduce → Hadoop
· 分布式文件系统 GFS(Google File System) → HDFS
· 数据存储系统 BigTable → HBase
HDFS(分布式文件系统)
负责数据的存储与管理,部署在硬盘上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
MapReduce (分布式计算框架)
MapReduce是一种基于磁盘的分布式并行批处理计算模型,用于处理大数据量的计算。其中Map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,Reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
Spark (分布式计算框架)
Spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
Flink (分布式计算框架)
Flink是一个基于内存的分布式并行处理框架,类似于Spark,但在部分设计思想有较大出入。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已。
补充
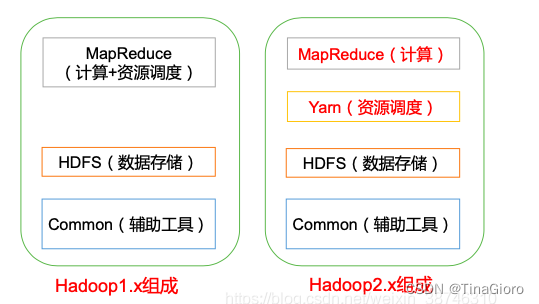
在Hadoop 1.x 时代,Hadoop 中的MapReduce 同时处理业务逻辑运算和资源的调度,耦合性较大。
在Hadoop 2.x 时代,增加了Yarn。Yarn 只负责资源的调度,MapReduce 只负责运算。















 1547
1547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









