









https://edu.huaweicloud.com/training/bdsd.html
华为认证大数据开发高级工程师
个人总结:主要介绍了大数据的主要各组件的职责,和应用场景及对应的解决方案。
课程导读
本课程为HCIP-Big Data Developer V2.0培训系列内容,请点击查看[ 完整课程系列](https://edu.huaweicloud.com/roadmap/bigdatadeveloper-hcip.html) ;想进一步考取华为认证大数据开发高级工程师HCIP-Big Data Developer,请点击查看职业认证考取流程。
HCIP-Big Data Developer V1.5****介绍:
面向对象
大数据方向的应用开发工程师;行业分析大数据的工程师。
定位
培训与认证具备使用开源技术平台和华为FusionInsight HD开发大数据解决方案能力的高级工程师
建议掌握的知识
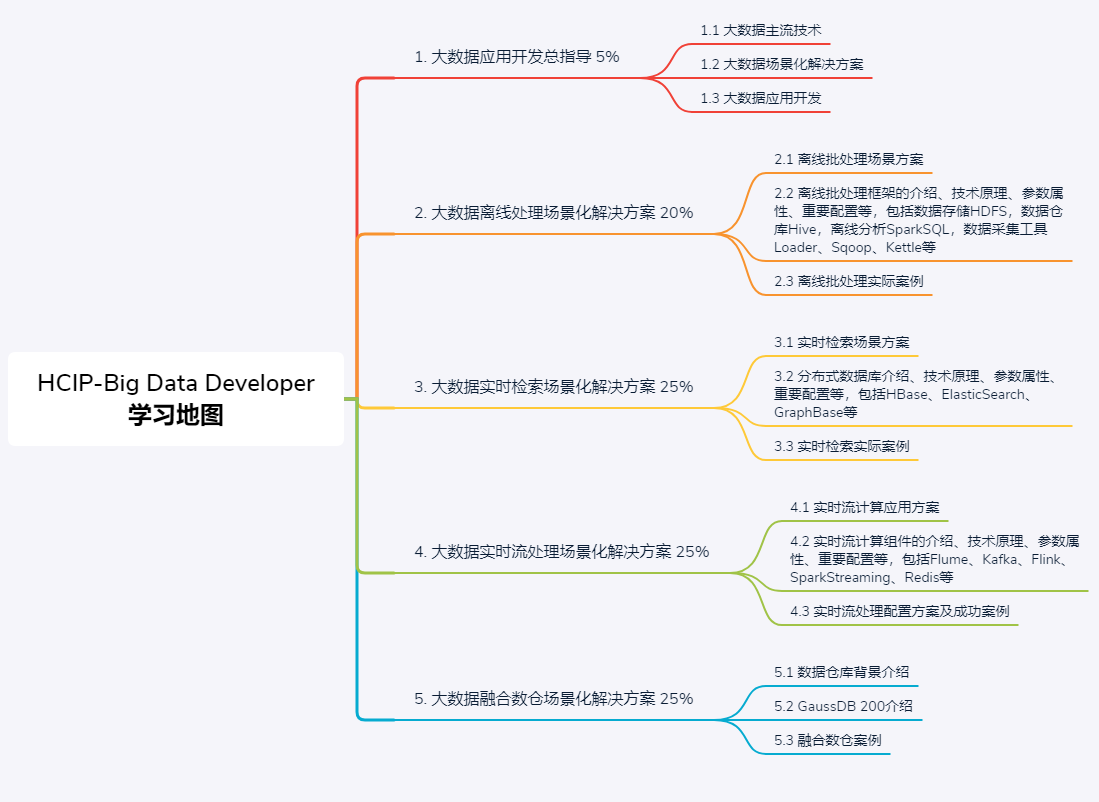
大数据应用开发流程、大数据主流技术、大数据场景化解决方案(离线批处理、实时检索、实时流处理、融合数仓GuassDB 200)等。
课程内容
一、大数据应用开发总指导
本课介绍了大数据主流技术、大数据场景化解决方案和如何进行大数据应用开发。
二、大数据离线处理场景化解决方案
本课主要给大家讲解了大数据离线批处理的概念,应用场景,常用组件的使用方法,以及简单介绍了离线批处理实战。基础的部分是大数据离线批处理概念和应用场景。难点是各个组件的具体使用,以及组件之间的组合使用。
三、大数据实时检索场景化解决方案
实时检索场景化解决方案的应用场景、技术架构、所采用的各种技术原理及使用,最后包含实际案例帮助大家更好的理解该解决方案。
四、大数据实时流处理场景化解决方案
大数据应用中实时流的场景解决方案,从方案架构到技术实现框架,包括数据的采集、处理、存储,包括实时流案例分析及实战。
五、大数据融合数仓场景化解决方案
大数据融合数仓的场景解决方案,从方案架构到技术实现框架,包括数据分析平台、华为GaussDB解决方案等。
1. 大数据主流技术
大数据定义 4V:体量巨大、处理速度快、类型繁多、价值密度低大数据的三架马车
- 分布式文件系统 GFS
- 分布式计算框架 MapReduce
- 分布式数据库系统 BigTable
大数据技术演变
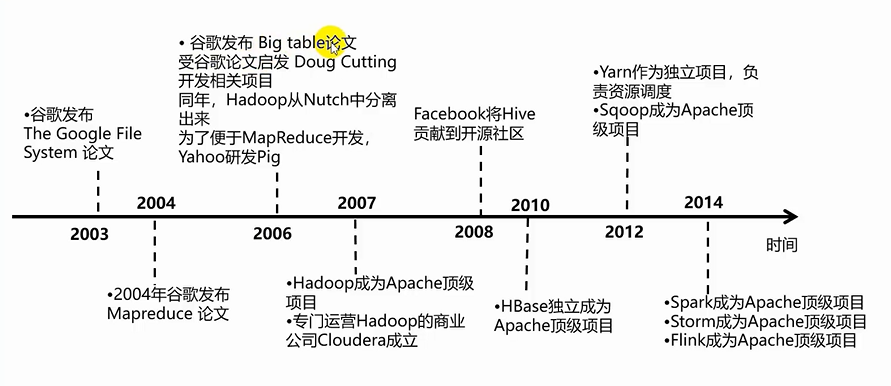
大数据主流技术
——大数据技术伴随大数据的采集、存储、处理和分析的相关技术。
大数据主流技术-数据采集
- 使用 Flume,可进行流式日志数据的收集
- 使用 Sqoop 可以交互关系型数据库,进行导入导出数据
- 使用爬虫技术,可在网上爬取海量网页数据
大数据主流技术-数据存储与管理
——大数据利用分布式文件系统HDFS、HBase、Hive,实现对结构化、半结构化和非结构化数据的存储和管理。
大数据主流技术-数据处理与分析
——利用分布式并行编程模型和计算框架,结合机器学习和数据挖掘算法,实现对海量数据的处理和分析。Hadoop、Sparck、Flink。
思考题
1. Google 发布的三篇论文是哪些?() 1. GFS 2. HDFS 3. MapReduce 4. BigTable-
大数据的 4V 不包含哪一个?()
- 数据量大
- 种类多
- 价值密度低
- 分布式
- 处理速度快
-
以下哪些属于大数据存储与管理技术?()
- HDFS
- HBase
- Tez
- Durid
2. 大数据场景化解决方案
`2024年9月26日17:15:57`大数据应用
| 领域 | 大数据的应用 |
|---|---|
| 金融 | 高频交易,市场舆情分析,信贷风险分析等 |
| 物流 | 智慧物流,包括成本控制、风险管理等 |
| 医疗 | 流行病预测,智慧医疗,健康管理等 |
| 互联网 | 用户画像,个性化推荐,广告投放等 |
| 城市 | 智慧交通,城市规划,智能安防等 |
场景化解决方案的分类
- 离线批处理
- 实时检索
- 实时流处理
- 融合数仓
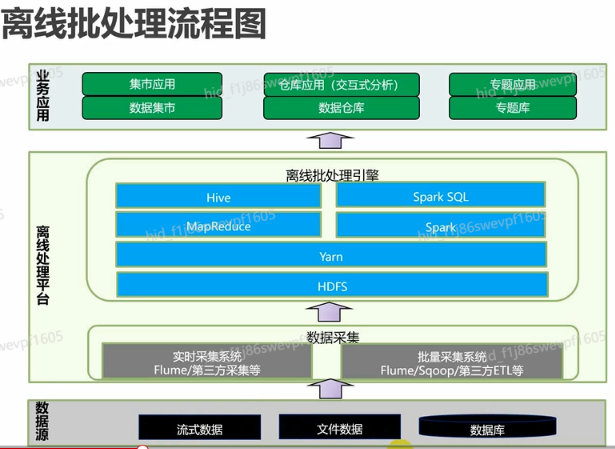
离线批处理
**离线批处理的概念**- 离线批处理,是指对海量历史数据进处理和分析,生成结果数据,供下一步数据应用使用的过程。
- 离线批处理对数据处理的时延要求不高,但是处理的数据量较大,占用的计算存储资源较多,通常通过MR作业、Spark作业或者HQL作业实现。
离线批处理的特点
- 处理时间要求不高
- 处理数据量巨大
- 处理数据格式多样
- 占用计算存储资源的多
离线批处理流程图
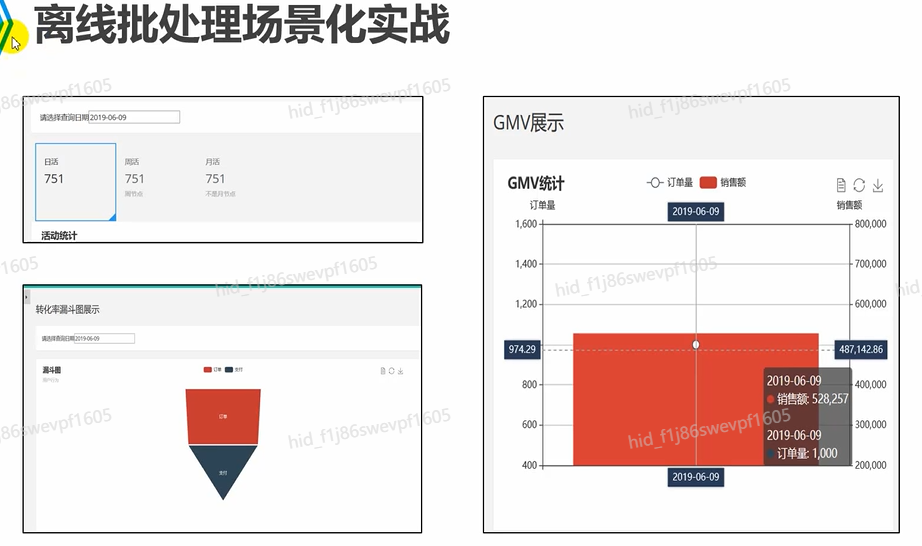
离线批处理场景化实战
实时检索
实时检索的概念
——实时检索简而言之就是对系统内的一些信息根据关键词进行即使、快速搜索,实现即搜即得的效果。强调的是实时低延迟。
核心诉求
- 检索性能要求高:基于主键的检索需要在1秒内响应,基于非主键的检索需要在3秒内响应,不承担复杂查询和统计类查询
- 高并发查询:通常有大于100的并发查询
- 数据量大:PB级数据量,集群规模在1000节点以上。对图数据库的场景,点个数在10亿以上,边个数在100亿以上
- 支持结构化和非结构化:需要同时保存结构化数据和非结构化数据,经常用来对图片等小文件进行检索
- 高效的数据加载:数据加载要求高,每小时可以加载TB级数据
- 支持图检索:支持检索图数据,支持图标准查询接口
实时检索流图
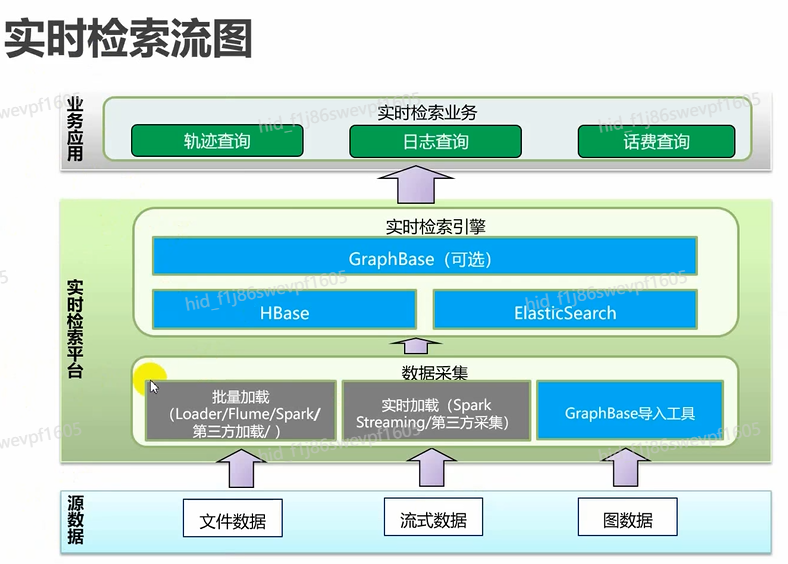
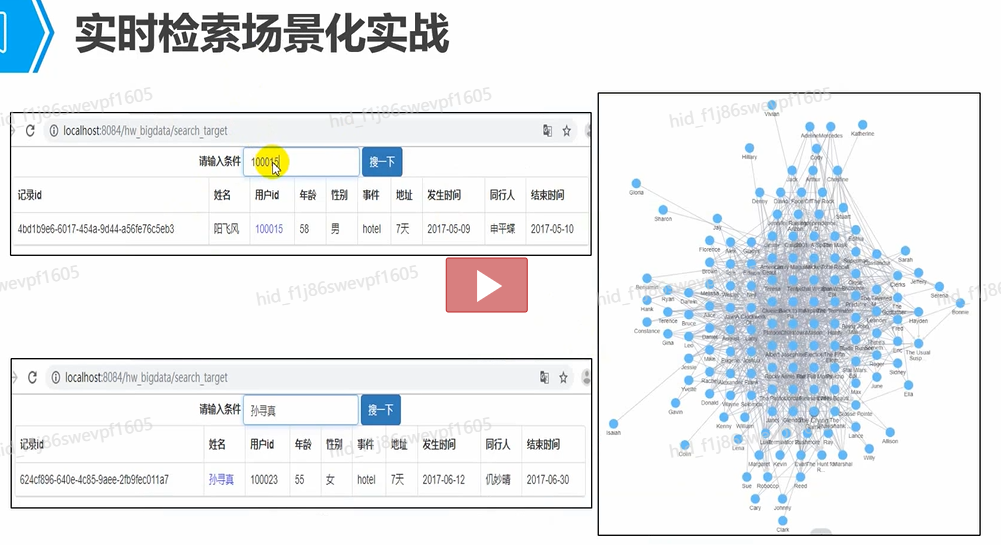
实时检索场景化实战
实时流处理
实时流处理的概念
——实时流处理,通常是指对实时数据源进行快速分析,迅速触发下一步动作的场景。实时数据对分析处理速度要求极高,数据处理规模巨大,对CPU和内存要求很高,但是通常数据不落地,对存储量要求不高。实时处理,通常通过StructuredStreaming或者Flink任务实现。
实时数据处理系统的诉求
- 处理速度快:端到端处理需要达到秒级,流处理平台负责的数据采集和数据处理要在1秒内完成。如风控项目要求单条数据处理时间达到秒级,单节点TPS大于2000。
- 吞吐量高:需在短时内接收并处理大量数据记录,吞吐量需要达到数十兆/秒/节点。
- 抗震性强:为应对数据源端业务数据产生速度会突然出现峰值的情形,需提供数据缓存机制。
- 可靠性高:网络、软件等故障发生时1需保止爸委据不丢失,数据处理不遗漏、不重复。
- 水平扩展:当系统处理能力出现瓶颈后,可通过节点的水平扩展提升处理性能。
- 多数据源支持:支持网络流、文件、数据库表、IOT等格式的数据源。对于文件数据源,可以处理增量数据的加载。
- 数据权限和资源隔离:消息处理、流处理需要有数据权限控制,不同的作业、用户可以访问、处理不同的消息和数据。多种流处理应用之间要进行资源控制和隔离,防止发生资源争抢。
- 第三方工具对接:支持与第三方规则引擎、决策系统、实时推荐系统等对接。
实时流处理数据流图
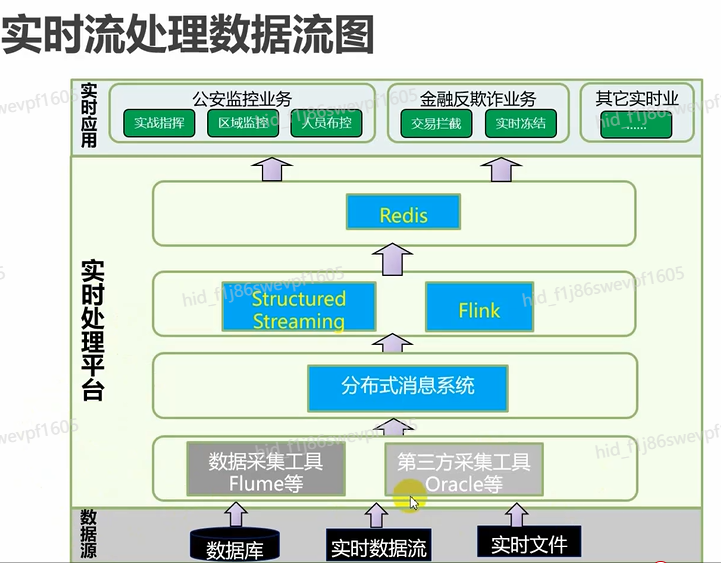
融合数仓
**融合数仓的概念**——在数据慢慢呈现数据处理量大、数据处理时延低、数据处理格式多样的要求下,基于模块化存储的数据仓库重要性日益增加,但同时也带来了新的问题。
————随着精准营销、客户画像、互联网平台等业务的上线,需要引入非结构化数据,以及提升对实时数据的计算处理能力,需要建立大数据平台满足上述业务需求。
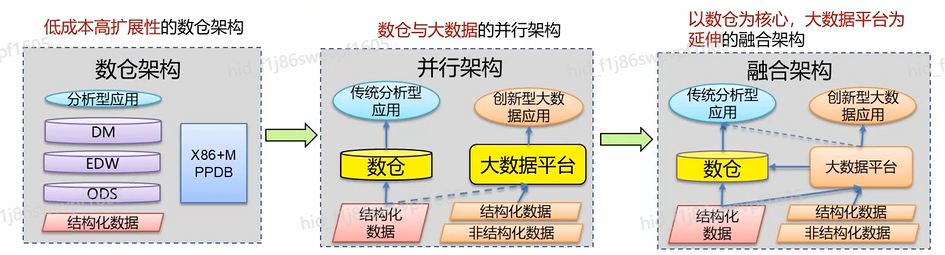
融合数仓流图
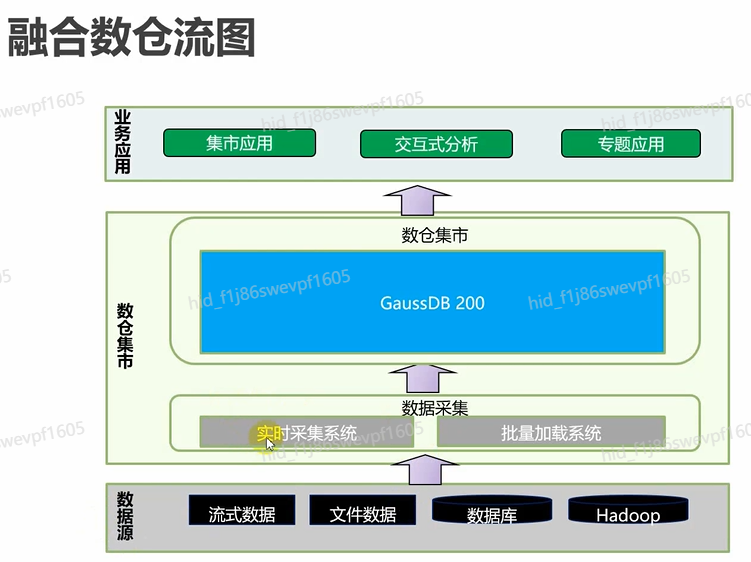
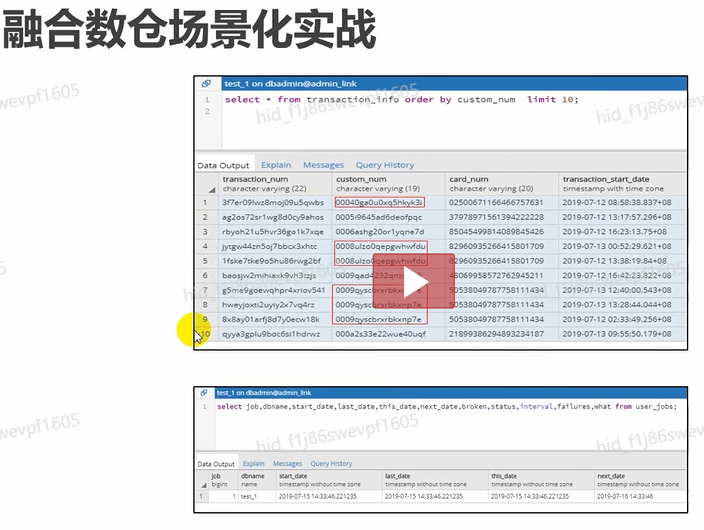
融合数仓场景化实战
思考题
1. 大数据可以用于流行病预测?() 2. 离线批处理通常通过MR作业、Spark作业或者HQL作业实现。() 3. 实时流处理对时延的要求不高。()3. 大数据应用开发
`2024年9月26日17:52:44`技能要求-编程基础
- 具备JAVA/Scala编程能力
- 熟悉SQL
- 熟悉Linux常规操作
技能要求-熟悉业务开发
- 理解研发开发流程
- 理解本应用业务背景
大数据应用开发流程
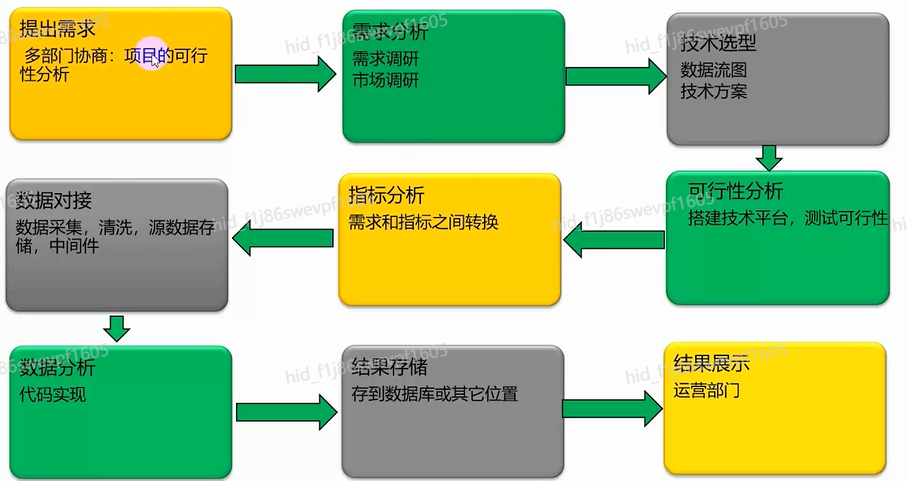
思考题
- 应用开发需要进行需求分析,包括需求调研和市场调研。()
- 技术选型时应该采用最新的技术不需要考虑技术的稳定性。()
- 服务器选型可以选择云主机和物理机。()















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









