





概述
随着互联网快速发展,数据量增长快,达到TB、PB,以交通车流量为例,如湖南省每月的车辆流量至少达到4亿,这个数据量远不止如此。数据量如此大,如何满足后期分析,传统面向OLTP型数据库(ORACLE、MYSQL等)无法要求,渐渐开始转向OLAP,如GreenPlum等,虽然很多OLAP数据库吸收分布式计算思想,数据达到20亿以上后,进行Count、聚合等操作性能仍然达不到客户实时分析要求。
虽然相关大数据框架及组件已经很流行:Hadoop(离线分析)、Spark、storm、Hive、Impala、Hbase等,Hadoop生态系统大庞大,Spark一站式安装部署,但是满足实时分析还需借助其它组件、开发要求很高。
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式时序数据库系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。尤其是当发生代码部署、机器故障以及其他产品系统遇到宕机等情况时,Druid仍能够保持100%正常运行。创建Druid的最初意图主要是为了解决查询延迟问题,当时试图使用Hadoop来实现交互式查询分析,但是很难满足实时分析的需要。而Druid提供了以交互方式访问数据的能力,并权衡了查询的灵活性和性能而采取了特殊的存储格式。
Druid适用场景
Druid应用最多的是类似于广告分析创业公司Metamarkets中的应用场景,如广告分析、互联网广告系统监控以及网络监控等。当业务中出现以下情况时,Druid是一个很好的技术方案选择:
- 需要交互式聚合和快速探究大量数据时;
- 需要实时查询分析时;
- 具有大量数据时,如每天数亿事件的新增、每天数10T数据的增加;
- 对数据尤其是大数据进行实时分析时;
- 需要一个高可用、高容错、高性能数据库时
Druid数据
Druid是一个开源的数据存储设计的事件数据的OLAP查询,提供一个高层次的概述如何存储数据和Druid集群的体系结构。
数据样例
timestamp publisher advertiser gender country click price
2011-01-01T01:01:35Z bieberfever.com google.com Male USA 0 0.65
2011-01-01T01:03:63Z bieberfever.com google.com Male USA 0 0.62
2011-01-01T01:04:51Z bieberfever.com google.com Male USA 1 0.45
2011-01-01T01:00:00Z ultratrimfast.com google.com Female UK 0 0.87
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 0 0.99
2011-01-01T02:00:00Z ultratrimfast.com google.com Female UK 1 1.53数据集由三个不同的组件组成:
时间序列化列:以时间序列进行数据分片,所有查询以时间为中心轴。
维度列:Druid基于列式存储,查询结果展示列,常用于数据过滤,如示例数据集有四个维度:出版商,广告商,性别和国家。
聚合列:通常用于计算值,操作方法如:COUNT、SUM等。
Druid 聚合
上述例子数据集中的单条信息作用不大,因为这样的数据万亿。然而这种类型的数据研究概述可以产生经济效益。Druid使用我们称之为“聚合”的过程对这些原始数据聚合操作,类似(伪代码)如下:
GROUP BY timestamp, publisher, advertiser, gender, country
:: impressions = COUNT(1), clicks = SUM(click), revenue = SUM(price) 在实践中我们看到聚合数据可以大大减少需要被存储的数据的大小(高达100倍)。减少存储确实是以成本为代价的,聚合数据后无法查询单个数据的能力;另一种解决方式减少聚合粒度,尽量满足查询数据的最小粒度。因此Druid通过queryGranularity方法(或属性granularity)定义这个粒度查询数据,最低支持为毫秒。
通过上述伪代码聚合后的数据:
timestamp publisher advertiser gender country impressions clicks revenue
2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70
2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18
2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31
2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01
Druid 分片数据
Druid的分片称之为Segment(即段),通常按时间对数据进行分片。如对示例数据进行压缩,我们可以创建两个段,按每小时分片。
段是保存时间间隔内数据,段包含按列存储的数据以及这些列的索引,Druid查询索引扫描段。段由数据源、间隔、版本的唯一标识,和一个可选的分区号。段命名规范如:
datasource_interval_version_partitionnumber
例如:
Segment sampleData_2011-01-01T01:00:00:00Z_2011-01-01T02:00:00:00Z_v1_0 contains
2011-01-01T01:00:00Z ultratrimfast.com google.com Male USA 1800 25 15.70
2011-01-01T01:00:00Z bieberfever.com google.com Male USA 2912 42 29.18Segment sampleData_2011-01-01T02:00:00:00Z_2011-01-01T03:00:00:00Z_v1_0 contains
2011-01-01T02:00:00Z ultratrimfast.com google.com Male UK 1953 17 17.31
2011-01-01T02:00:00Z bieberfever.com google.com Male UK 3194 170 34.01Druid 索引数据
Druid查询速度取决于如何存储数据。从搜索基础架构借用想法,Druid创建只读数据快照,查询分析存储在高度优化的数据结构。
Druid是一个列存储,每列被单独存储。Druid查询相当好,是因为只查询所需的列。不同的列还可以采用不同的压缩方式,不同的列也可以有与它们相关的不同的索引。
Druid 索引数据在数据分片级别上。
Druid 数据加载
Druid有两方式获取数据,实时和批量,Druid实时获取很费劲,确切的说Druid不能保证实时获取。批量获取可以保证批量创建段及相应数据。Druid通常采用实时管道获取实时数据(最近数据),采用批管道获取副本数据。
Druid 数据查询
Druid的本地查询语言是JSON通过HTTP,虽然社区在众多的语言中提供了查询库,包括SQL查询贡献库;Druid设计用于单表操作,目前不支持联接
Druid 集群
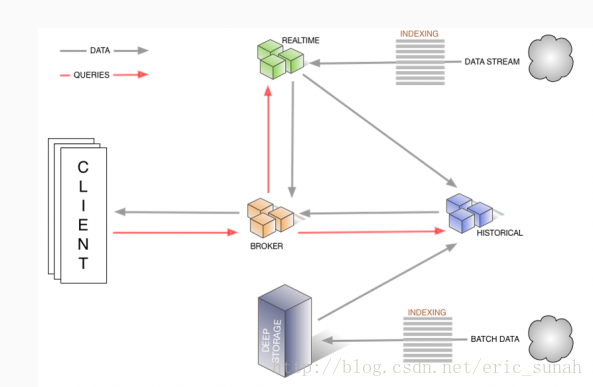
Druid是由不同角色的系统构建而成的一个整体系统,它的名字来自在许多角色扮演游戏中的Druid类:它是一个shape-shifter,可以在一个群组中采取许多不同的形式来满足各种不同的角色。Druid的整体架构中目前包括以下节点类型:
- Historical
对“historical”数据(非实时)进行处理存储和查询的地方。historical节点响应从broker节点发来的查询,并将结果返回给broker节点。它们在Zookeeper的管理下提供服务,并使用Zookeeper监视信号加载或删除新数据段。
- Realtime
实时摄取数据,它们负责监听输入数据流并让其在内部的Druid系统立即获取,Realtime节点同样只响应broker节点的查询请求,返回查询结果到broker节点。旧数据会被从Realtime节点转存至Historical节点。
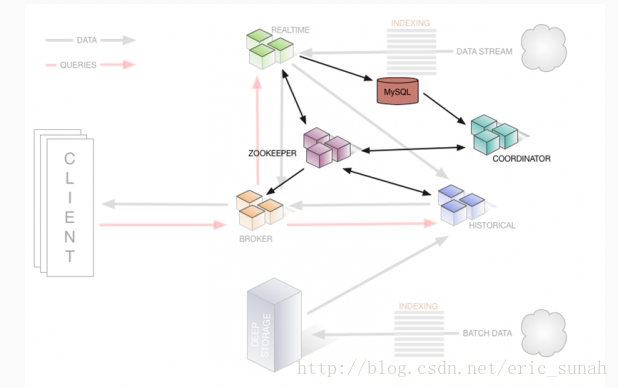
- Coordinator
监控historical节点组,以确保数据可用、可复制,并且在一般的“最佳”配置。它们通过从MySQL读取数据段的元数据信息,来决定哪些数据段应该在集群中被加载,使用Zookeeper来确定哪个historical节点存在,并且创建Zookeeper条目告诉historical节点加载和删除新数据段。
- Broker
接收来自外部客户端的查询,并将这些查询转发到Realtime和Historical节点。当Broker节点收到结果,它们将合并这些结果并将它们返回给调用者。由于了解拓扑,Broker节点使用Zookeeper来确定哪些Realtime和Historical节点的存在。
- Indexer
节点会形成一个加载批处理和实时数据到系统中的集群,同时会对存储在系统中的数据变更(也称为索引服务)做出响应。这种分离让每个节点只关心自身的最优操作。通过将Historical和Realtime分离,将对进入系统的实时流数据监控和处理的内存分离。通过将Coordinator和Broker分离,把查询操作和维持集群上的“好的”数据分布的操作分离。
数据流和各个节点的关系如下图:
相关节点和集群管理所依赖的其他组件(Zookeeper)如下:
高可用
Druid为高可用架构,不会存在单点故障,一种节点出现问题后,其他节点的服务也不会受到影响。














 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









