







简述
在我上一篇完结的Tianic测试中,我曾提到了一个在使用sklenlearn包中出现的一个问题,这成为了我们这里预留的一个悬念,也就是为了防止不拟合时而使用了scaling,但是当时我在scaling的时候报错了,这一下就十分尴尬了,因此我在网上查找了一些相关的资料,最终我找出了问题的所在。当然没读过上一篇的童鞋也不需要担心,这一篇文章的内容我将结合查找到的资料,简要的介绍一下梯度下降过程中的归一化问题,其中涉及到相关特征的缩放(scaling),同时,我也会在下一节介绍sklenlearn包中的相关操作。
归一化和标准化
归一化这个问题,在我前面的多元线性回归算法的优化中曾有提到过这个问题,但是当时因为懒没有做相关的详细介绍,同时,当时我们并不是这样说的,当时我们是称该算法为缩放。但是这里其实是有一些问题的,我们来先看一下官方的概念,来加深一下了解。
归一化方法:归一化方法有两种形式,一种是把数变为(0,1)之间的小数,一种是把有量纲表达式变为无量纲表达式。
我们在查看后发现这里并没有提到缩放这个问题。但是当我查找一些资料后发现一个问题就是,每当我们提及到归一化问题时,总会见到另外一个概念就是数据标准化 那么我们就来在看一下数据标准化的这个概念
数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。由于信用指标体系的各个指标度量单位是不同的,为了能够将指标参与评价计算,需要对指标进行规范化处理,通过函数变换将其数值映射到某个数值区间。
看到这里我们可能会有点迷糊,那意思缩放属于数据标准化而并非数据归一化了么?其实不然,如果仔细阅读,我们会发现数据按比例缩放,童鞋们你们不觉得就是把数字变为为(0,1)之间的小数很相似么。所以,其实归一化的方法是标准化的手段之一。
到这里,童鞋们是不是还是觉得有些糊涂,如果这里还不清楚我举一个简单的例子。在NG教授的machinelearning如果仔细看的童鞋们会发现,NG教授在房价问题(在我前面几篇的相关博客中有提到)时,曾提到过特征缩放,这里我们看到的很明显就是数据标准化的问题,但是教授的特征缩放是把数变为了(0,1)之间的小数,这下我们就应该很清楚这两者之间的关系了。
为何采取归一化
在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这样我们能够帮助梯度下降算法更快地收敛,但是,大多数的情况下我们会发现数据有时候会出现很大的差异,就比如说在Tiannic中我们拟合预测出缺失的年龄,有几岁的小盆友,同样的还有七八十的老大(tu)爷(hao)。可能有人会觉得这其实差的不大,但是我们要知道,在我们进行数据拟合时这小小的问题会对我们最终的判断造成极大的伤害。另一个例子就很好地说明了这一问题,就是我们在说明标准化和归一化问题时提到的房价预测问题。假设我们使用两个特征,房屋的尺寸和房屋的数量,尺寸的值为0-2000平方英尺,而房间数量的值是0-5,以两个参数为横纵坐标,绘制代价函数的等高线图。如左图
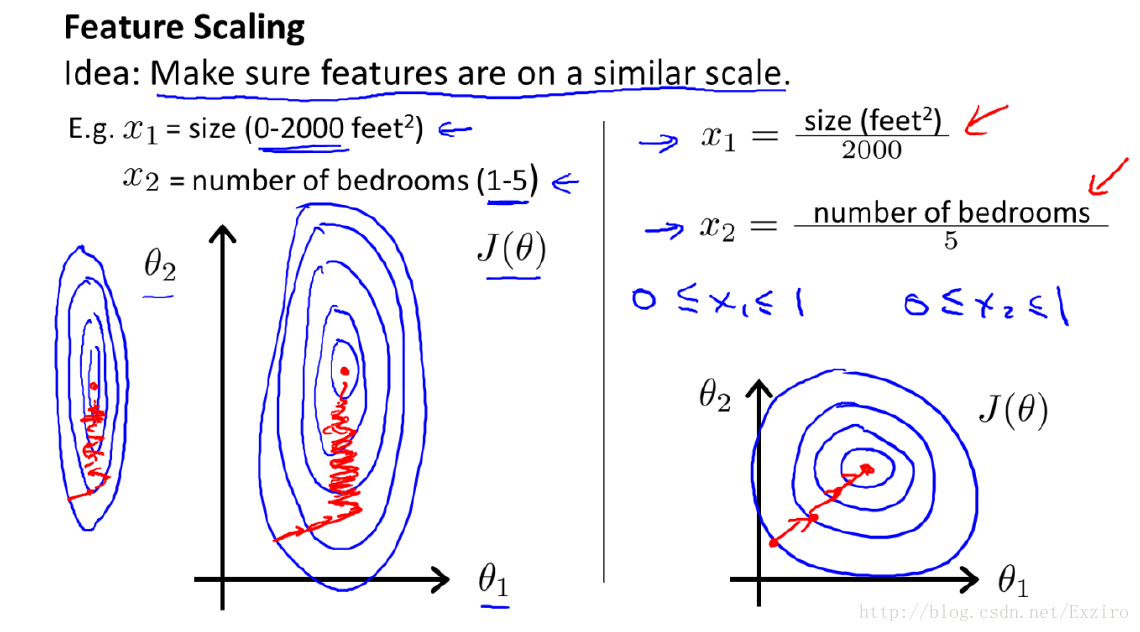
我们会发现梯度下降算法需要进行多次迭代才能收敛,而解决的方法就是特征缩放,将所有特征的尺度都缩放到(0,1)之间。(如右图)我们能够明显看出,迭代的次数明显下降,很快地就收敛了。
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标进行相关的操作。
数据归一化方法
这里我们简单介绍两种归一化的方法,当然方法还有很多我们就不一一介绍了。
1.min-max标准化(Min-max normalization)/0-1标准化(0-1 normalization)
也叫离差标准化,是对原始数据的线性变换,使结果落到[0,1]区间,转换函数如下:
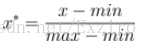
其中max为样本数据的最大值,min为样本数据的最小值。
def Normalization(x):
return [(float(i)-min(x))/float(max(x)-min(x)) for i in x]
如果想要将数据映射到[-1,1],则将公式换成:
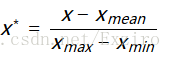
x_mean表示数据的均值。
def Normalization2(x):
return [(float(i)-np.mean(x))/(max(x)-min(x)) for i in x]
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
2.log函数转换
通过以10为底的log函数转换的方法同样可以实现归一下,具体方法如下:
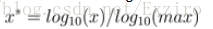
看了下网上很多介绍都是x*=log10(x),其实是有问题的,这个结果并非一定落到[0,1]区间上,应该还要除以log10(max),max为样本数据最大值,并且所有的数据都要大于等于1。
总结
这里我们大概总结了归一化、标准化相关概念及一些区别还有一些相关的实现。如果有问题的童鞋可以在下面留言,Scikit-learn中的实现我会在下一篇博客中详细介绍。同时如果别中有问题 请看到的大佬们多多指教,谢谢。














 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









