



分布式架构
分布式架构:根据业务功能对系统进行拆分,每个业务模块作为独立项目开发,称为一个服务
优点:
- 降低服务耦合
- 有利于服务升级拓展
微服务是一种经过良好架构设计的分布式架构方案,微服务架构特征:
- 单一职责:微服务拆分粒度更小,每一个服务都对应唯一的业务能力,做到单一职责,避免重复业务开发
- 面向服务:微服务对外暴露业务接口
- 自治:团队独立、技术独立、数据独立、部署独立
- 隔离性强:服务调用做好隔离、容错、降级,避免出现级联问题
服务远程调用
/**
*创建 RestTemplate 并注入Spring容器
* @return
*/
@Bean
public RestTemplate restTemplate(){
return new RestTemplate();
} public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
//2.发起http请求
String url = "http://localhost:8081/user/" + order.getUserId();
User user = restTemplate.getForObject(url, User.class);
//封装user到order
order.setUser(user);
// 4.返回
return order;
}提供者与消费者
- 服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
- 服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)
一个服务可以既是消费者,也是提供者。
Eureka注册中心

消费者获取服务提供者具体信息的方式:
- 服务提供者启动时向eureka注册自己的信息
- eureka保存这些信息
- 消费者根据服务名称向eureka拉取提供者信息
如果有多个服务提供者,消费者利用负载均衡算法,从服务列表中挑选一个
消费者感知服务提供者健康状态:
- 服务提供者会每隔30秒向EurekaServer发送心跳请求,报告健康状态
- eureka会更新记录服务列表信息,心跳不正常会被剔除
- 消费者就可以拉取到最新的信息
在Eureka架构中,微服务角色有两类:
- EurekaServer:服务端,注册中心
记录服务信息
心跳监控
EurekaClient:客户端
- Provider:服务提供者,例如案例中的 user-service
注册自己的信息到EurekaServer
每隔30秒向EurekaServer发送心跳
- consumer:服务消费者,例如案例中的order-service
根据服务名称从Eurekaserver拉取服务列表
基于服务列表做负载均衡,选中一个微服务后发起远程调用
搭建eureka服务
引入依赖,写文件
<dependencies>
<!-- eureka服务端-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
</dependencies>server:
port: 10086
spring:
application:
name: eurekaserver # eureka的服务名称
eureka:
client:
service-url: #eureka的地址信息
dafaulZone: http://localhost:10086/eurekapackage com.eureka;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer;
@EnableEurekaServer
@SpringBootApplication
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class,args);
}
}
启动成功之后,会出现下面这个页面

服务注册
1.在user-service项目引入spring-cloud-starter-netflix-eureka-client的依赖
<!--引入eureka客户端依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>2.在application.yml文件,编写下面的配置:
eureka:
client:
service-url: #eureka的地址信息
defaultZone: http://localhost:10086/eureka 配置完成之后,在eureka客户端就能看到载入的两个服务
服务发现
由于之前远程调用使用的固定的ip,耦合度太高,所有在引入eureka之后,可以使用它的技术来实现低耦合的服务发现。
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
//2.发起http请求
String url = "http://userservice/user/" + order.getUserId();
User user = restTemplate.getForObject(url, User.class);
//封装user到order
order.setUser(user);
// 4.返回
return order;
} @Bean
@LoadBalanced
public RestTemplate restTemplate(){
return new RestTemplate();
}Nacos
nacos注册中心
基础配置
分别在父工程和子工程中加载nacos的xml文件
<!--nacos管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.5.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency> <!-- nacos客户端依赖包 -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>在完成以上配置后,打开nacos就能看到一下信息

服务多级存储
集群负载均衡
集群配置需要再yml文件中追加一下的信息
discovery:
cluster-name: HZ
#负载均衡规则
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule
之后的所有请求都会朝着本地服务进行发送,但当本地服务挂掉以后,nacos还是会选择进行跨集群访问。
08-20 11:45:10:888 WARN 25336 --- [nio-8080-exec-3] c.alibaba.cloud.nacos.ribbon.NacosRule : A cross-cluster call occurs,name = userservice, clusterName = HZ, instance = [Instance{instanceId='192.168.211.1#8081#SH#DEFAULT_GROUP@@userservice', ip='192.168.211.1', port=8081, weight=1.0, healthy=true, enabled=true, ephemeral=true, clusterName='SH', serviceName='DEFAULT_GROUP@@userservice', metadata={preserved.register.source=SPRING_CLOUD}}]
NacosRule载均衡策略
- 优先选择同集群服务实例列表
- 本地集群找不到提供者,才去其它集群寻找,并且会报警告
- 确定了可用实例列表后,再采用随机负载均衡挑选实例
权重负载均衡
实际部署中会出现这样的场景:
- 服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求
Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高
- 在Nacos控制台可以设置实例的权重值,首先选中实例后面的编辑按钮
- 将权重设置为0.1,测试可以发现8081被访问到的频率大大降低


实例的权重控制
- Nacos控制台可以设置实例的权重值,0~1之间
- 同集群内的多个实例,权重越高被访问的频率越高
- 权重设置为0则完全不会被访问
环境隔离-namespace
Nacos中服务存储和数据存储的最外层都是一个名为namespace的东西,用来做最外层隔离。
命名空间需要再nacos中进行设置

将服务分配到哪一个命名空间是需要在yml文件中进行配置,配置完成之后,就可以在dev命名空间中发现服务。
namespace: 8bffbcda-7ef6-40f1-ab4a-51043ae9a880 
当他们不在一个空间内时,服务之间无法进行访问。
Nacos环境隔离
- namespace用来做环境隔离
- 每个namespace都有唯一id
- 不同namespace下的服务不可见
Nacos和Eureka的共同点和区别
Nacos与eureka的共同点
- 都支持服务注册和服务拉取
- 都支持服务提供者心跳方式做健康检测
Vacos与Eureka的区别
- Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
- 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
- Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
- Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
Nacos配置管理
微服务配置拉取

在yml文件中对信息填写完全后,就可以通过浏览器对数据进行读取
spring:
application:
name: userservice
profiles:
active: dev
cloud:
nacos:
server-addr: localhost:8848
config:
file-extension: yaml配置的热更新
但是普通模式下无法实现对数据的热更新,实现热更新有两种方式。
方式一:
添加RefreshScope注解
@RefreshScope方式二:使用@ConfigurationProperties注解(推荐)
@Component
@Data
@ConfigurationProperties(prefix="pattern")
public class PatternProperties {
private String dateformat;
}Nacos配置更改后,微服务可以实现热更新,方式:
- 通过@Value注解注入,结合@RefreshScope来刷新
- 通过@ConfigurationProperties注自动刷新
注意事项:
- 不是所有的配置都适合放到配置中心,维护起来比较麻烦
- 建议将一些关键参数,需要运行时调整的参数放到nacos配置中心,一般都是自定义配置
多环境配置共享
微服务启动时会从nacos读取多个配置文件

微服务会从nacos读取的配置文件
- [服务名]-[spring.profile.active].yaml,环境配置
- [服务名].yaml,默认配置,多环境共享
优先级:
- [服务名]-[环境].yaml>[服务名].yaml>本地配置
Nacos集群搭建
搭建集群的基本步骤
- 搭建数据库,初始化数据库表结构
- 下载nacos安装包
- 配置nacos
- 启动nacos集群
- nginx反向代理
http客户端Feign
远程调用
Feign是一个声明式的http客户端,官方地址:Feign 其作用就是帮助我们优雅的实现http请求的发送,解决发送请求的代码过于难解读的问题。
下面是使用的方法
1.引入依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>2.在启动类中添加注解开启Feign的功能
@EnableFeignClients3. 编写Feign客户端
主要是基于SpringMVC的注解来声明远程调用的信息,比如:
- 服务名称:userservice
- 请求方式:GET
- 请求路径:/user/{id)}
- 请求参数:Long id
- 返回值类型:User
@FeignClient("userservice")
public interface UserClient {
@GetMapping("user/{id}")
User findById(@PathVariable("id") Long id);
}
4.使用Feign方法
@Autowired
private UserClient userClient;
public Order queryOrderById(Long orderId) {
// 1.查询订单
Order order = orderMapper.findById(orderId);
//2.用Feign远程调用
User user = userClient.findById(order.getUserId());
//3.封装user到Order
order.setUser(user);
// 4.返回
return order;
}Feign的日志配置
方式一是配置文件,feign.client.config.xxx.loggerLevel
- 如果xxx是default则代表全局
- 如果xxx是服务名称,例如userservice则代表某服务
方式二是java代码配置Logger.Level这个Bean
- 如果在@EnableFeignclients注解声明则代表全局
- 如果在@FeignClient注解中声明则代表某服务
Feign的性能优化
Feign底层的客户端实现:
- URLConnection:默认实现,不支持连接池
- Apache HttpClient:支持连接池
- OKHttp:支持连接池
因此优化Feign的性能主要包括:
- 使用连接池代替默认的URLConnection
- 日志级别,最好用basic或none
feign:
httpclient:
enabled: true #支持HttpClient的开关
max-connections: 200
max-connections-per-route: 50Feign的优化:
1.日志级别尽量用basic
2.使用HttpClient或OKHttp代替URLConnection
引入feign-httpClient依赖
配置文件开启httpClient功能,设置连接池参数
Feign的最佳实践
为了避免在日常开发中,过多服务都需要去调用Contorller的情况,使用以下情况来避免重复开发。
将FeignCclient抽取为独立模块,并且把接口有关的POJ0、默认的Feign配置都放到这个模块中,提供给所有消费者使用。

Feign的最佳实践:
- 让controller和FeignClient继承同一接口
- 将FeignClient、POj0、Feign的默认配置都定义到一个项目中,供所有消费者使用
不同包的Feignclient的导入有两种方式
- 在@EnableFeignClients注解中添加basePackages,指定Feignclient所在的包
- 指定具体在@EnableFeignClients注解中添加clients,:FeignClient的字节码
Feign远超调用服务降级处理
当一个服务向另一个服务发起网络请求时,由于另一个服务接受不了此时发来的大量请求,可能导致我们整个系统的崩溃,所以在合理的情况下使用熔断降级是可行的。
1.编写降级逻辑
@Component
public class IArticleClientFallback implements IArticleClient {
@Override
public ResponseResult saveArticle(ArticleDto dto) {
return ResponseResult.errorResult(AppHttpCodeEnum.SERVER_ERROR,"获取数据失败");
}
}
2.远程接口中指定降级代码
3.客户端开启降级
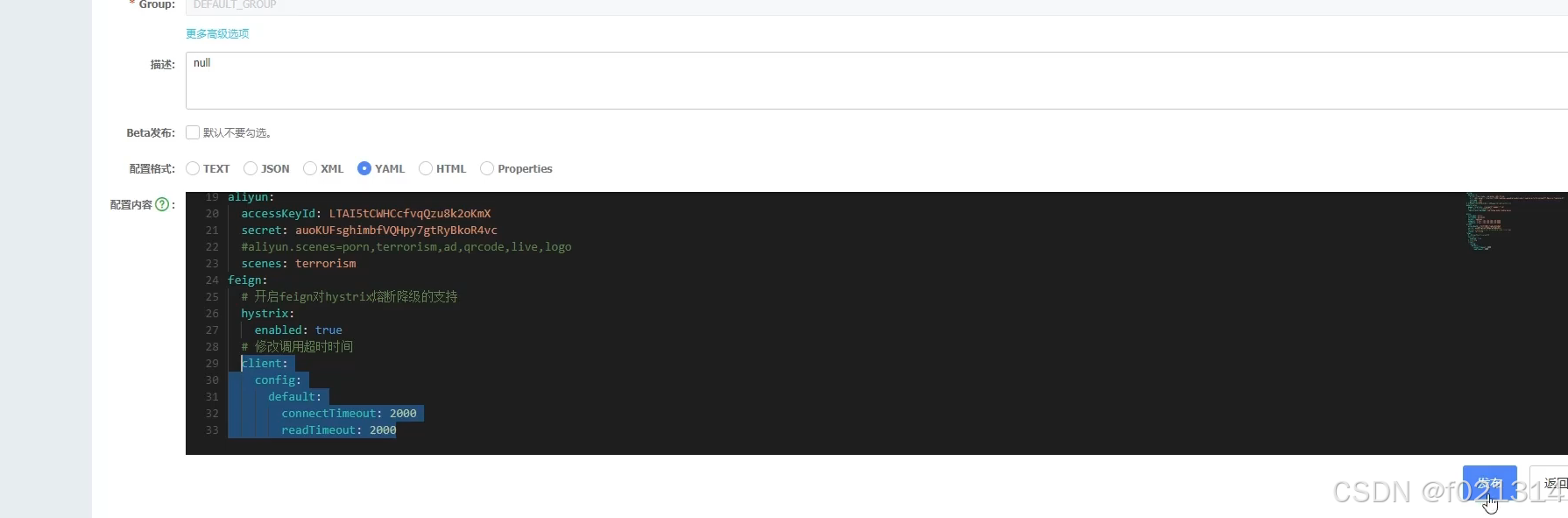
统一网关Gateway
网关功能
- :身份认证和权限
- 校验服务路由、负载均衡
- 请求限流
在SpringCloud中网关的实现包括两种:
- gateway
- Zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的Webflux,属于响应式编程的实现,具备更好的性能。
搭建网关服务
1.创建新的module,引入SpringCloudGateway的依赖和nacos的服务发现依赖。
<dependencies>
<!--服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--网关依赖-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
</dependencies>2.编写路由配置及nacos地址
server:
port: 10010
spring:
application:
name: gateway
cloud:
nacos:
server-addr: localhost:8848 #nacos地
gateway:
routes:
- id: user-service #路由标示,必须唯一
uri: lb://userservice #路由的目标地址
predicates: #路由断言,判断请求是否符合规则
- Path=/user/** #路径断言,判断路径是否是以/user开头,如果是则符合
- id: order-service
uri: lb://orderservice
predicates:
- Path=/order/**
现在通过访问gateway晚安的端口,也能对我们的目标数据进行访问了。
网关搭建步骤
- 创建项目,引入nacos服务发现和gateway依赖
- 配置application.yml,包括服务基本信息、nacos地址、路由
路由配置包括
- 路由id:路由的唯一标示
- 路由目标(uri):路由的目标地址,http代表固定地址,lb代表根据服务名负载均衡
- 路由断言(predicates):判断路由的规则
- 路由过滤器(filters):对请求或响应做处理
路由断言工厂
网关路由可以配置的内容包括:
- 路由id:路由唯一标示
- uri:路由目的地,支持lb和http两种
- predicates:路由断言,判断请求是否符合要求,符合则转发到路由目的地
- filters:路由过滤器,处理请求或响应

路由过滤器
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:

过滤器的作用是什么?
- 对路由的请求或响应做加工处理,比如添加请求头配置在路由下的过滤器只对当前路由的请求生效
defaultFilters的作用是什么?
- 对所有路由都生效的过滤器
全局过滤器(GloalFilter)
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。
区别在于GatewayFilter通过配置定义,处理逻辑是固定的。而GlobalFiter的逻辑需要自己写代码实现。
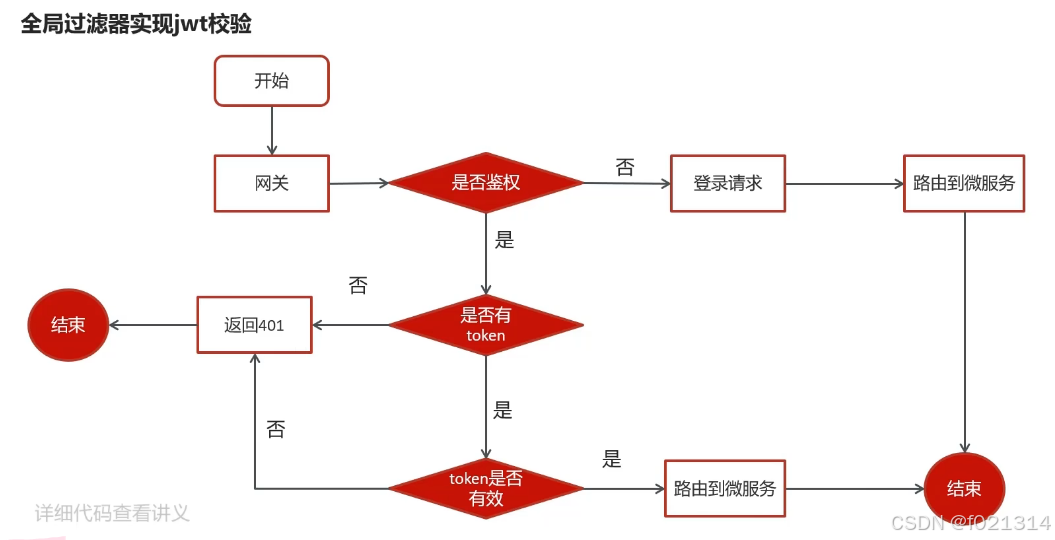
@Order(-1)
@Component
public class AuthorizeFilter implements GlobalFilter, Ordered {
@0verride
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterchain chain){
//1.获取请求参数
ServerHttpRequest request=exchange.getequest();
MultiValueMap<String,String>params=request.getQueryParams();
//2.获取参数中的 authorization 参数
String auth=params.getFirst( key:"authorization");
//3.判断参数值是否等于 admin
if("admin".equals(auth)){
//4.是,放行
return chain.filter(exchange);
// 5.否,拦截
//5.1.设置状态码
exchange.getResponse().setStatusCode(HttpStatus.UNAUTHORIZED);
//5.2.拦鼓请求
return exchange.getResponse().setComplete();
}全局过滤器的作用
- 对所有路由都生效的过滤器,并且可以自定义处理逻辑
实现全局过滤器的步骤
- 实现GlobalFilter接口
- 添加@Order注解或实现Ordered接
- 编写处理逻辑
过滤器执行顺序
- 每一个过滤器都必须指定一个int类型的order值,order值越小,优先级越高,执行顺序越靠前。
- GlobalFilter通过实现Ordered接口,或者添加@Order注解来指定order值,由我们自己指定
- 路由过滤器和defaultFilter的order由Spring指定,默认是按照声明顺序从1递增。
- 当过滤器的order值一样时,会按照 defaultFilter >路由过滤器>GlobalFilter的顺序执行。
跨域问题处理
跨域:域名不一致就是跨域,主要包括:
- 域名不同:www.taobao.com和www.taobao.org 和 www,jd.com 和 miaosha.jd.com
- 域名相同,端口不同:localhost:8080和localhost:8081
跨域问题:浏览器禁止请求的发起者与服务端发生跨域ajax请求,请求被浏览器拦截的问题
解决方案:CORS
spring:
cloud:
gateway:
globalcors: #全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins:#允许哪些网站的跨域请求
"http://localhost:8090"
"http://www.leyou.com"
allowedMethods:#允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders:"*"#允许在请求中携带的头信息
allowCredentials:true#是否允许携带cookie
maxAge: 360000#这次跨域检测的有效期Docker
什么是Docker
Docker实际上就相当于一个封闭的沙盒或者是集装箱,它可以把不同的应用全都放在它的集装箱里面,并且以后有需要的时候,可以直接把集装箱搬到其他平台或者服务器上,实现容器虚拟化技术,随用随搬。
一句话,Docker解决了运行环境和配置问题软件容器,方便做持续集成并有助于整体发布的容器虚拟化技术。
Docker解决大型项目依赖关系复杂,不同组件依赖的兼容性问题
- Docker允许开发中将应用、依赖、函数库、配置一起打包,形成可移植镜像
- Docker应用运行在容器中,使用沙箱机制,相互隔离
Docker解决开发、测试、生产环境有差异的问题
- Docker镜像中包含完整运行环境,包括系统函数库,仅依赖系统的Linux内核,因此可以在任意Linux操作系统上运行
Docker和虚拟机
虚拟机(virtualmachine)是在操作系统中模拟硬件设备,然后运行另一个操作系统,比如在 Windows 系统里面运行Ubuntu 系统,这样就可以运行任意的Ubuntu应用了。

Docker和虚拟机的差异
- docker是一个系统进程;虚拟机是在操作系统中的操作系统
- docker体积小、启动速度快、性能好:虚拟机体积大、启动速度慢、性能一般
Docker架构
镜像和容器
- 镜像(lmage):Docker将应用程序及其所需的依赖、函数库、环境、配置等文件打包在一起,称为镜像
- 容器(Container):镜像中的应用程序运行后形成的进程就是容器,只是Docker会给容器做隔离,对外不可见。
Docker和DockerHub
- DockerHub:DockerHub是一个Docker镜像的托管平台。这样的平台称为Docker Registry。
- 国内也有类似于DockerHub 的公开服务,比如 网易云镜像服务、阿里云镜像库。
Docker是一个CS架构的程序,由两部分组成:
- 服务端(server):Docker守护进程,负责处理Docker指令,管理镜像、容器等
- 客户端(client):通过命令或RestAPI向Docker服务端发送指令。可以在本地或远程向服务端发送指令
MQ
MQ(MessageQueue),中文是消息队列,字面来看就是存放消息的队列。也就是事件驱动架构中的Broker。
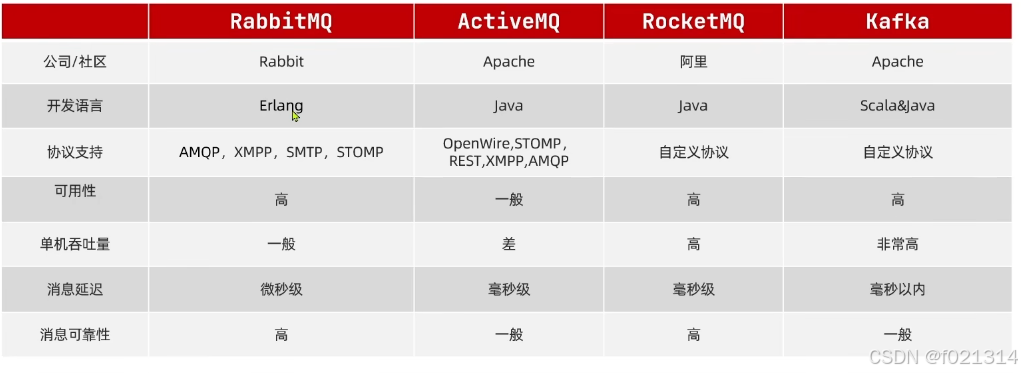
MQ可靠性
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。这样会导致两个问题:
- 一旦MO宕机,内存中的消息会丢失
- 内存空间有限,当消费者故障或处理过慢时,会导致消息积压,引发MQ阻塞
数据持久化
RabbitMO实现数据持久化包括3个方面:
- 交换机持久化
- 队列持久化
- 消息持久化(spring发送的消息默认持久)
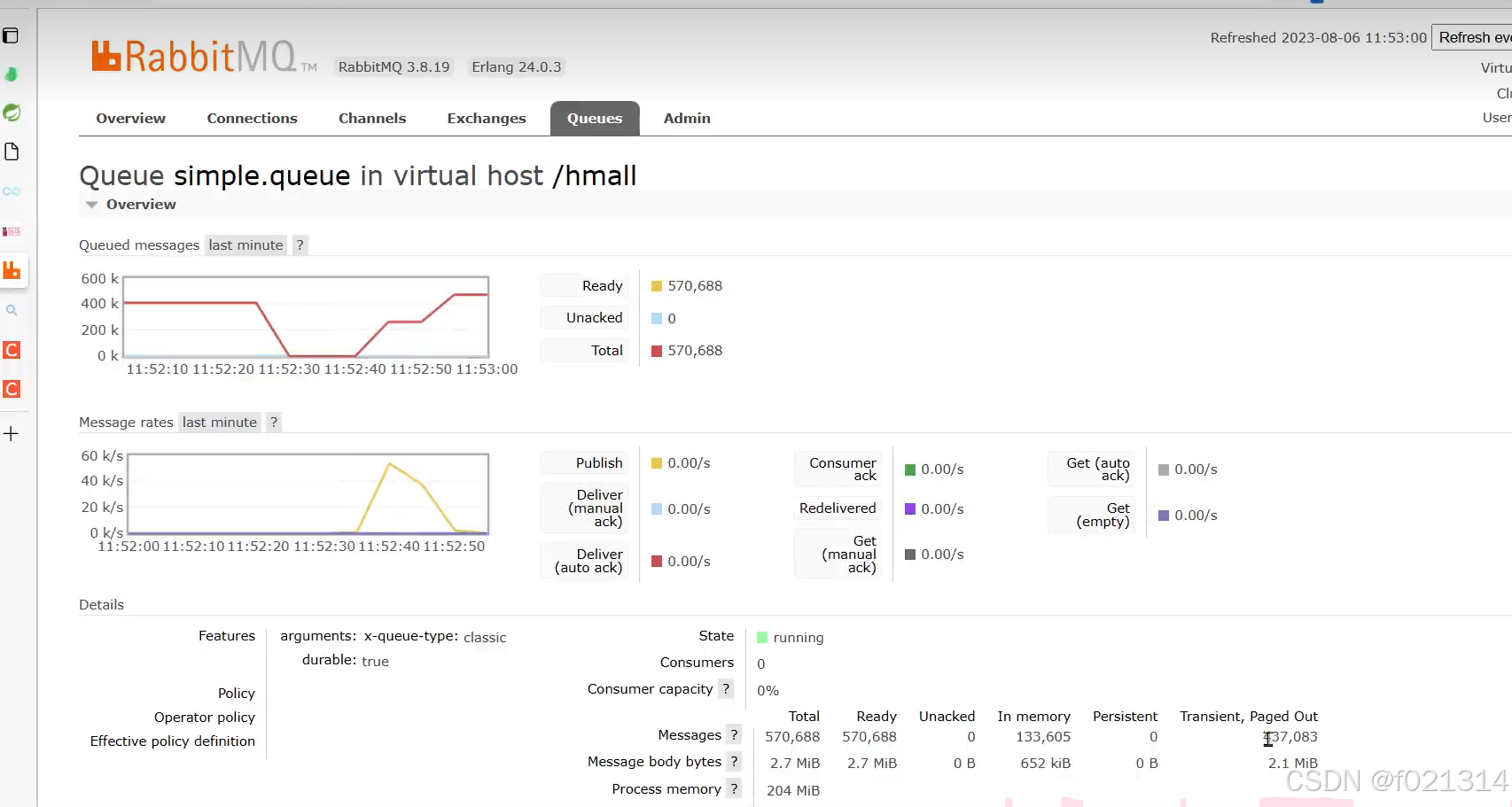
利用for循环给mq发送了100百万条临时消息,下面是他的详细信息。
@Test
public void testPageOut() {
Message msg = MessageBuilder
.withBody("hello".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.NON_PERSISTENT).build();
for (int i = 0; i < 1000000; i++) {
rabbitTemplate.convertAndSend("simple",msg);
}
}
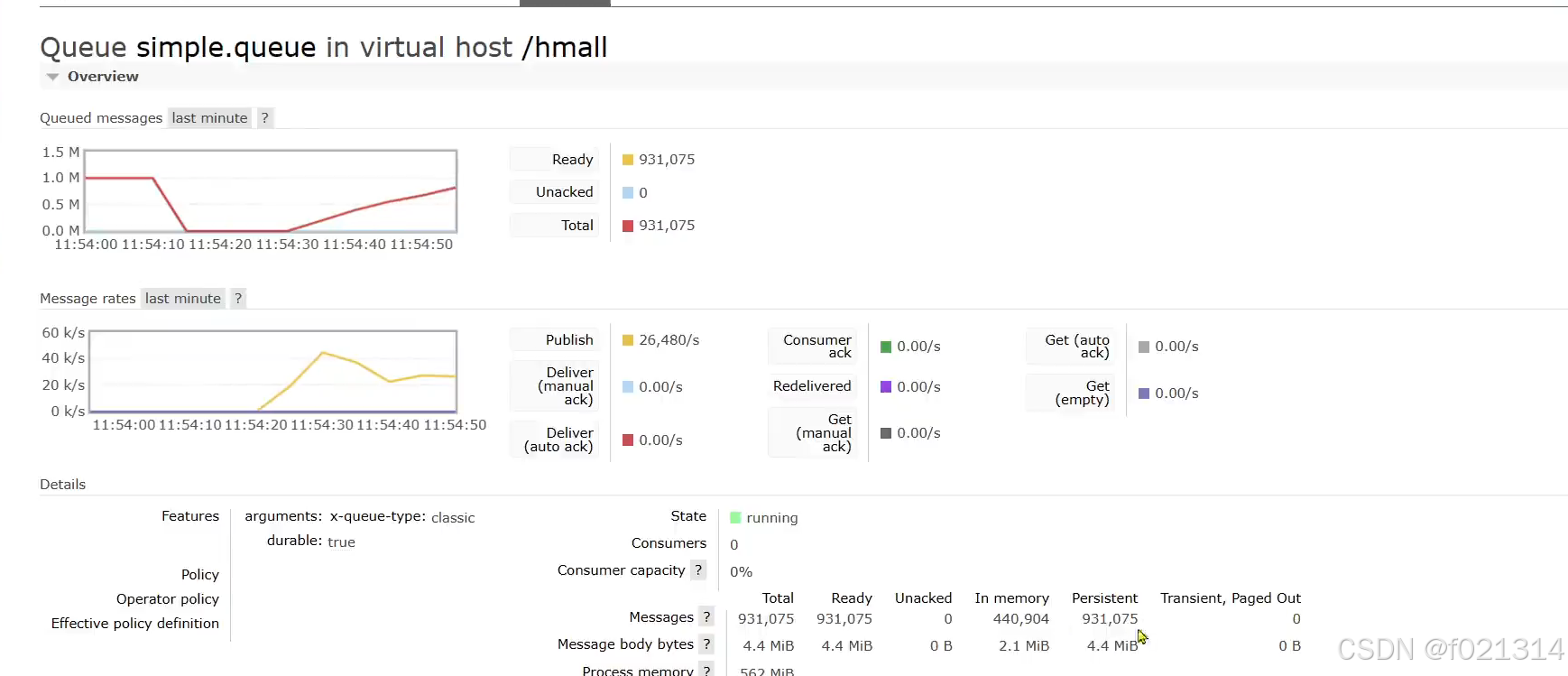
利用for循环给mq发送了100百万条永久消息,下面是他的详细信息。
@Test
public void testPageOut() {
Message msg = MessageBuilder
.withBody("hello".getBytes(StandardCharsets.UTF_8))
.setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();
for (int i = 0; i < 1000000; i++) {
rabbitTemplate.convertAndSend("simple",msg);
}
}
Lazy Queue
从RabbitMQ的3.6.0版本开始,就增加了LazyQueue的概念,也就是惰性队列。
惰性队列的特征如下:
- 接收到消息后直接存入磁盘而非内存(内存中只保留最近的消息,默认2048条)
- 消费者要消费消息时才会从磁盘中读取并加载到内存
- 支持数百万条的消息存储
在3.12版本后,所有队列都是Lazy Queue模式,无法更改
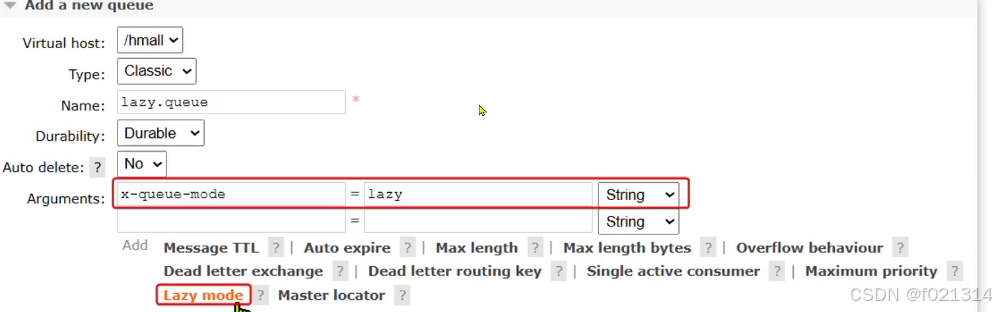
用代码实现如下:
@Bean
public Queue lazyQueue() {
return QueueBuilder
.durable("lazy.queue")
.lazy()
.build();
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "topic",type = ExchangeTypes.TOPIC),
arguments = @Argument(name = "x-queue-mode",value = "lazy"),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.err.println("消费者2接收到topic.queue2的消息:【"+msg+"】");
}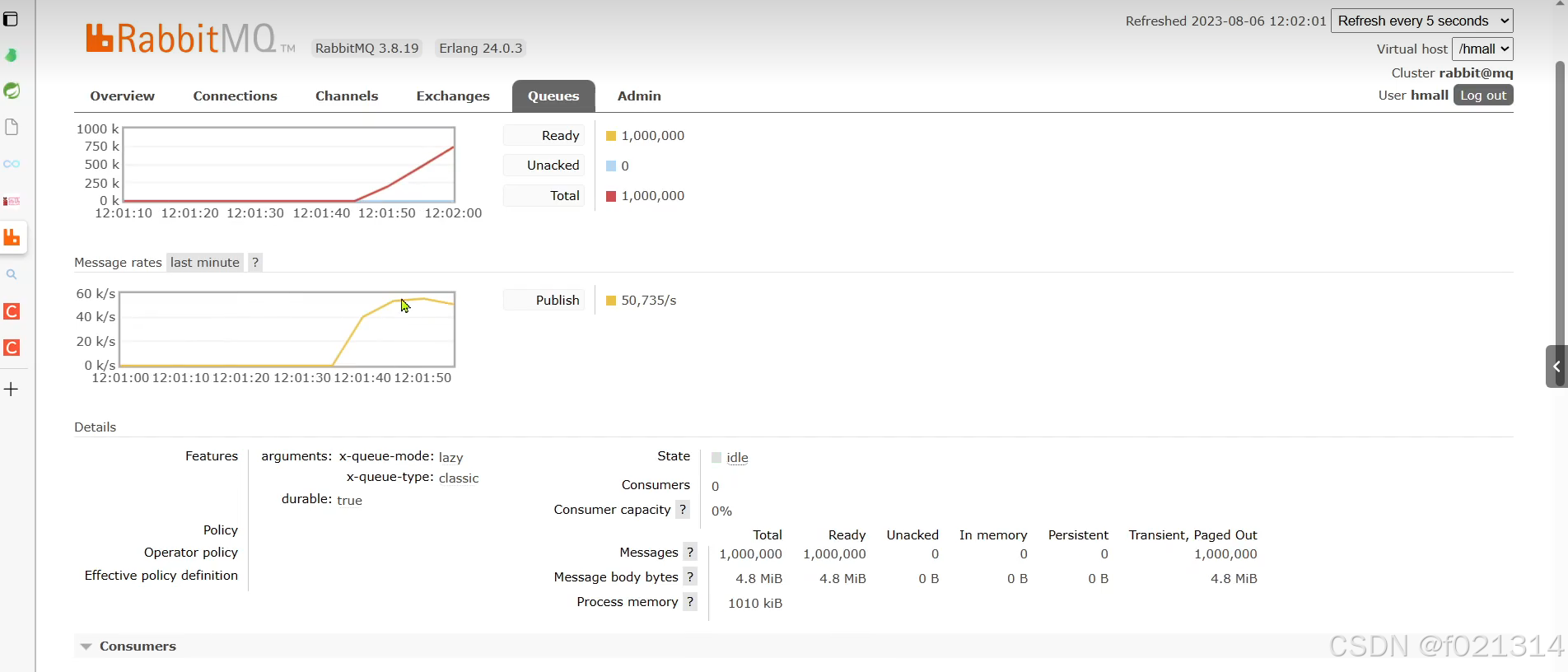
lazyqueue的效率明显是高于数据持久化方式的。
RabbitMQ如何保证消息的可靠性
- 首先通过配置可以让交换机、队列、以及发送的消息都持久化。这样队列中的消息会持久化到磁盘,MO重启消息依然存在。
- RabbitMO在3.6版本引入了LazyQueue,并且在3.12版本后会称为队列的默认模式。LazyQueue会将所有消息都持久化。
- 开启持久化和生产者确认时,RabbitM0只有在消息持久化完成后才会给生产者返回ACK回执
消费者可靠性
消费者确认
为了确认消费者是否成功处理消息,RabbitMO提供了消费者确认机制(ConsumerAcknowledgement)。当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态。回执有三种可选值:
- ack:成功处理消息,RabbitMO从队列中删除该消息
- nack:消息处理失败,RabbitMO需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
SpringAMQP已经实现了消息确认功能。并允许我们通过配置文件选择ACK处理方式,有三种方式:
- none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MO删除。非常不安全,不建议使用
- manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活
- auto:自动模式。SpringAMOP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack当业务出现异常时,根据异常判断返回不同结果:
- 如果是业务异常,会自动返回nack
- 如果是消息处理或校验异常,自动返回 reject
消费失败处理
当消费者出现异常后,消息会不断requeue(重新入队)到队列,再重新发送给消费者,然后再次异常,再次requeue无限循环,导致mq的消息处理飙升,带来不必要的压力。
我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列:
listener:
simple:
prefetch: 1
acknowledge-mode: auto
retry:
enabled: true #开启重试机制在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
- RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机
将失败处理策略改为RepublishMessageRecoverer:
- 首先,定义接收失败消息的交换机、队列及其绑定关系,此处略:
- 然后,定义RepublishMessageRecoverer
@Bean
public DirectExchange directExchange() {
return new DirectExchange("error.direct");
}
@Bean
public Queue errorQueue() {
return new Queue("error.queue");
}
@Bean
public Binding errorBinding(Queue errorQueue, DirectExchange directExchange) {
return BindingBuilder.bind(errorQueue).to(directExchange).with("error");
}
@Bean
public MessageRecoverer messageConverter(RabbitTemplate rabbitTemplate) {
return new RepublishMessageRecoverer(rabbitTemplate, "error,direct", "error");
}业务幂等性
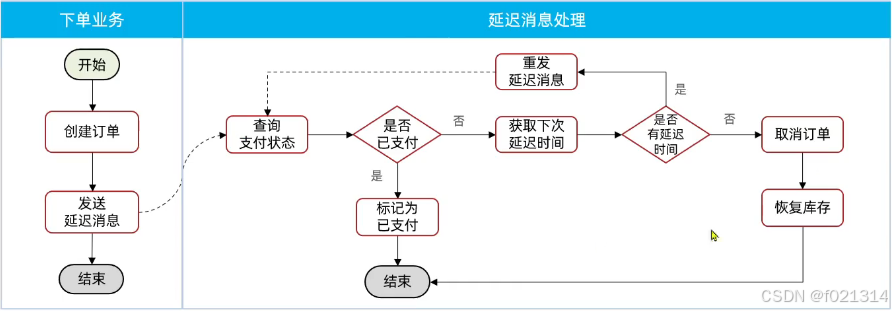
延时消息
延迟消息:生产者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间之后才收到消息
死信交换机
当一个队列中的消息满足下列情况之一时,就会成为死信(dead letter)
- 消费者使用basic.reject或 basic.nack声明消费失败,并且消息的requeue参数设置为false
- 消息是一个过期消息(达到了队列或消息本身设置的过期时间),超时无人消费
- 要投递的队列消息堆积满了,最早的消息可能成为死信
如果队列通过dead-letter-exchange属性指定了一个交换机,那么该队列中的死信就会投递到这个交换机中。这个交换机称为死信交换机(Dead LetterExchange,简称DLX)。
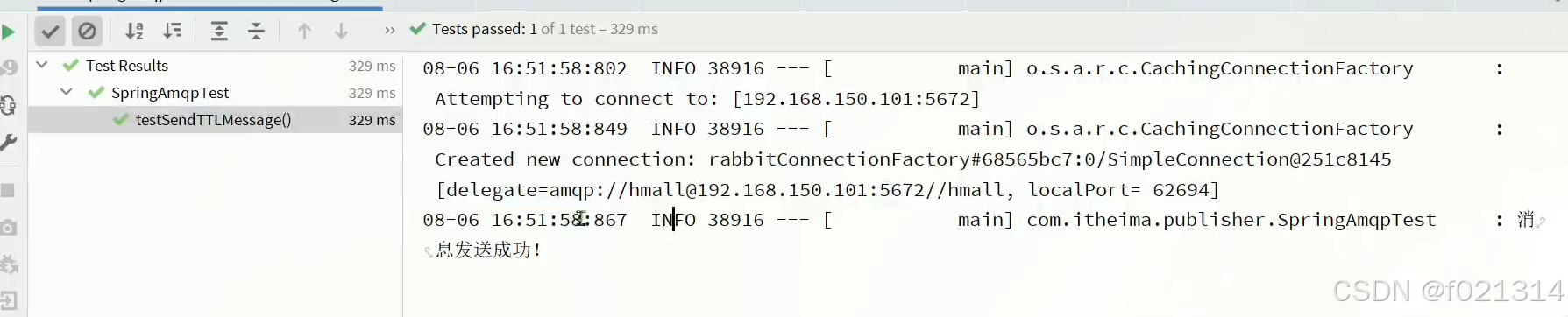
使用java代码将时间设为10秒钟
@Test
public void testSendTTLMessage() {
Message msg = MessageBuilder
.withBody("hello".getBytes(StandardCharsets.UTF_8))
.setExpiration("10000")
.build();
rabbitTemplate.convertAndSend("simple.queue", "hi", msg);
}

延迟消息插件
RabbitMO的官方也推出了一个插件,原生支持延迟消息功能。该插件的原理是设计了一种支持延迟消息功能的交换机当消息投递到交换机后可以暂存一定时间,到期后再投递到队列。
声明如下:
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = "delay.queue", durable = "true"),
exchange = @Exchange(value = "delay.exchange", delayed = "true", type = "direct"),
key = "hi"
))
public void listenDelayQueue(String msg) {
System.out.println("接收到delay.queue的消息");
} @Test
public void testSendDelayMessage() {
rabbitTemplate.convertAndSend("delay.queue", "hi", "hello",new MessagePostProcessor() {
@Override
public Message postProcessMessage(Message message) throws AmqpException {
message.getMessageProperties().setDelay(10000);
return message;
}
});
}但是由于这种方式的延迟消息,都是在系统中维护一个时钟,当我们写了多个延迟消息时,会给我们的cpu带来巨大的消耗。
RabbitMQ
RabbitMQ概述
RabbitMQ是基于Erlang语言开发的开源消息通信中间件,官方网址:RabbitMQ: One broker to queue them all | RabbitMQ
RabbitMQ中的几个概念:
- channel:操作MQ的工具
- exchange:路由消息到队列中
- queue:缓存消息
- virtualhost:虚拟主机,是对queue、exchange等
- 资源的逻辑分组
HelloWorld案例
官方的HelloWorld是基于最基础的消息队列模型来实现的,只包括三个角色
- publisher:消息发布者,将消息发送到队列queue
- queue:消息队列,负责接受并缓存消息
- consumer:订阅队列,处理队列中的消息
发布者发布消息
public class PublisherTest {
@Test
public void testSendMessage() throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.150.101");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.发送消息
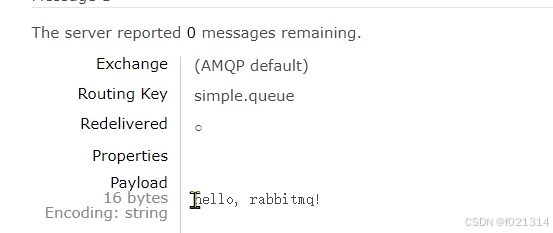
String message = "hello, rabbitmq!";
channel.basicPublish("", queueName, null, message.getBytes());
System.out.println("发送消息成功:【" + message + "】");
// 5.关闭通道和连接
channel.close();
connection.close();
}
}在运行完代码后,在rabbitmq中能看到发送的信息。
消费者订阅消息
public class ConsumerTest {
public static void main(String[] args) throws IOException, TimeoutException {
// 1.建立连接
ConnectionFactory factory = new ConnectionFactory();
// 1.1.设置连接参数,分别是:主机名、端口号、vhost、用户名、密码
factory.setHost("192.168.150.101");
factory.setPort(5672);
factory.setVirtualHost("/");
factory.setUsername("itcast");
factory.setPassword("123321");
// 1.2.建立连接
Connection connection = factory.newConnection();
// 2.创建通道Channel
Channel channel = connection.createChannel();
// 3.创建队列
String queueName = "simple.queue";
channel.queueDeclare(queueName, false, false, false, null);
// 4.订阅消息
channel.basicConsume(queueName, true, new DefaultConsumer(channel){
@Override
public void handleDelivery(String consumerTag, Envelope envelope,
AMQP.BasicProperties properties, byte[] body) throws IOException {
// 5.处理消息
String message = new String(body);
System.out.println("接收到消息:【" + message + "】");
}
});
System.out.println("等待接收消息。。。。");
}
}
基本消息队列的消息发送流程:
- 建立connection
- 创建channel
- 利用channel声明队列
- 利用channel向队列发送消息
基本消息队列的消息接收流程:
- 建立connection
- 创建channel
- 利用channel声明队列
- 定义consumer的消费行为handleDelivery()
- 利用channel将消费者与队列绑定
SpringAMQP
AMQP:Advanced Message Queuing Protocol,是用于在应用程序或之间传递业务消息的开放标准。该协议与语言和平台无关,更符合微服务中独立性的要求。
SpringAMQP:基于AMQP协议定义的一套API规范,提供了模板来发送和接收消息。包含两部分,其中spring-amqp是基础抽象,spring-rabbit是底层的默认实现。
入门案例
下面是生产者代码
spring:
rabbitmq:
host:
port: 5672
username: xiaofu
password: 123321
virtual-host: /
@RunWith(SpringRunner.class)
@SpringBootTest
public class springAMQP {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
public void testSentMessage2SimpleQueue(){
String queueName = "simple.queue";
String message = "hello SpringAMPQ";
rabbitTemplate.convertAndSend(queueName,message);
}
}
下面是消费者代码
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String msg){
System.out.println("消费者接收到simple.queue的消息:【"+msg+"】");
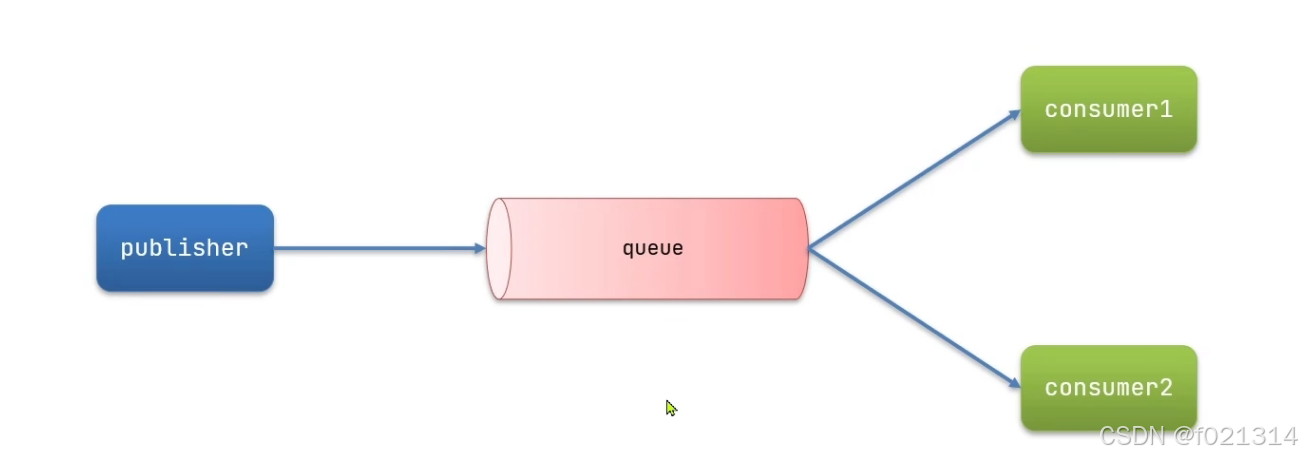
}Work Queue 工作队列
由于工作队列使用多消费者模式,可以提高消息处理速度,避免队列消息堆积。
下面是生产者代码
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2接收到simple.queue的消息:【"+msg+"】");
Thread.sleep(200);
}下面是消费者代码
(由于spring amqp默认机制,我们开启“能者多劳”模式需要对yml文件进行修改)
spring:
rabbitmq:
host: 192.168.112.139
port: 5672
username: xiaofu
password: 123321
virtual-host: /
listener:
simple:
prefetch: 1
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue1(String msg) throws InterruptedException {
System.out.println("消费者1接收到simple.queue的消息:【"+msg+"】");
Thread.sleep(20);
}
@RabbitListener(queues = "simple.queue")
public void listenWorkQueue2(String msg) throws InterruptedException {
System.err.println("消费者2接收到simple.queue的消息:【"+msg+"】");
Thread.sleep(200);
}发布(Publish)、订阅(Subscribe )
FanoutExchange
发布订阅模式与之前案例的区别就是允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)。
发布订阅模式与之前案例的区别就是允许将同一消息发送给多个消费者。实现方式是加入了exchange(交换机)常见exchange类型包括:
- Fanout:广播
- Direct::路由
- Topic:话题
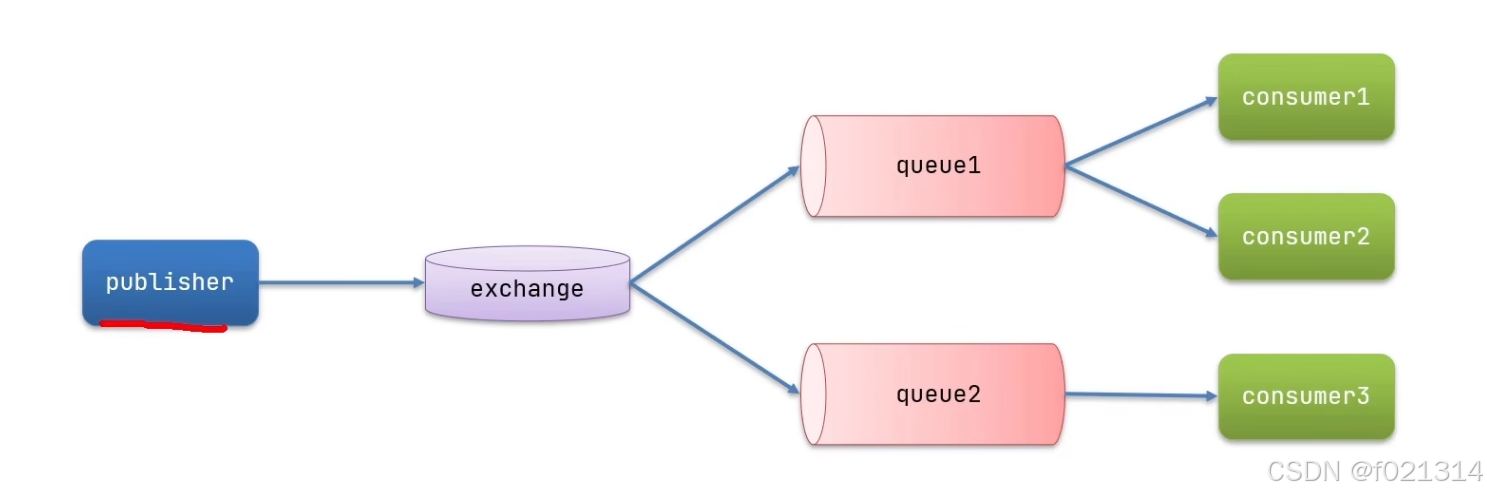
Exchanqe 会将接收到的消息路由到每一个跟其绑定的queue
注意:exchange负责消息路由,而不是存储,路由失败则消息丢失。
下面是消费者代码
@Configuration
public class FanoutConfig {
@Bean
public FanoutExchange fanoutExchange() {
return new FanoutExchange("fanout");
}
@Bean
public Queue fanoutQueue1() {
return new Queue("fanout.queue1");
}
//绑定队列1到交换机
@Bean
public Binding fanoutBinding1(Queue fanoutQueue1, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue1).to(fanoutExchange);
}
@Bean
public Queue fanoutQueue2() {
return new Queue("fanout.queue2");
}
//绑定队列1到交换机
@Bean
public Binding fanoutBinding2(Queue fanoutQueue2, FanoutExchange fanoutExchange) {
return BindingBuilder.bind(fanoutQueue2).to(fanoutExchange);
}
}
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) throws InterruptedException {
System.err.println("消费者1接收到fanout.queue1的消息:【"+msg+"】");
Thread.sleep(200);
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) throws InterruptedException {
System.err.println("消费者2接收到fanout.queue2的消息:【"+msg+"】");
Thread.sleep(200);
}下面是生产者代码
@RabbitListener(queues = "fanout.queue1")
public void listenFanoutQueue1(String msg) throws InterruptedException {
System.err.println("消费者1接收到fanout.queue1的消息:【"+msg+"】");
Thread.sleep(200);
}
@RabbitListener(queues = "fanout.queue2")
public void listenFanoutQueue2(String msg) throws InterruptedException {
System.err.println("消费者2接收到fanout.queue2的消息:【"+msg+"】");
Thread.sleep(200);
}
交换机的作用
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
声明队列、交换机、绑定关系的Bean
- Queue
- FanoutExchange
- Binding
DirectExchange
Direct Exchange 会将接收到的消息根据规则路由到指定的Queue,因此称为路由模式(routes)
- 每一个Queue都与Exchange设置一个BindingKey
- 发布者发送消息时,指定消息的RoutingKey
- Exchange将消息路由到BindingKey与消息RoutingKey一致的队列
下面是消费者代码
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "direct",type = ExchangeTypes.DIRECT),
key = {"red","blue"}
))
public void listenDirectQueue1(String msg){
System.out.println("消费者1接收到direct.queue1的消息:【"+msg+"】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "direct",type = ExchangeTypes.DIRECT),
key = {"red","yello"}
))
public void listenDirectQueue2(String msg){
System.err.println("消费者1接收到direct.queue2的消息:【"+msg+"】");
}下面是生产者代码
@Test
public void testSendDirectExchange(){
//交换机名称
String exchangeName = "direct";
//消息
String msg = "hello red";
//发送消息
rabbitTemplate.convertAndSend(exchangeName,"red",msg);
}描述下Direct交换机与Fanout交换机的差异:
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
基于@RabbitListener注解声明队列和交换机有常见注解
- @Queue
- @Exchange
TopicExchange
TopicExchange与DirectExchange类似,区别在于routingKey必须是多个单词的列表,并且以,分割。
Queue与Exchange指定BindingKey时可以使用通配符
#:代指0个或多个单词
*:代指一个单词
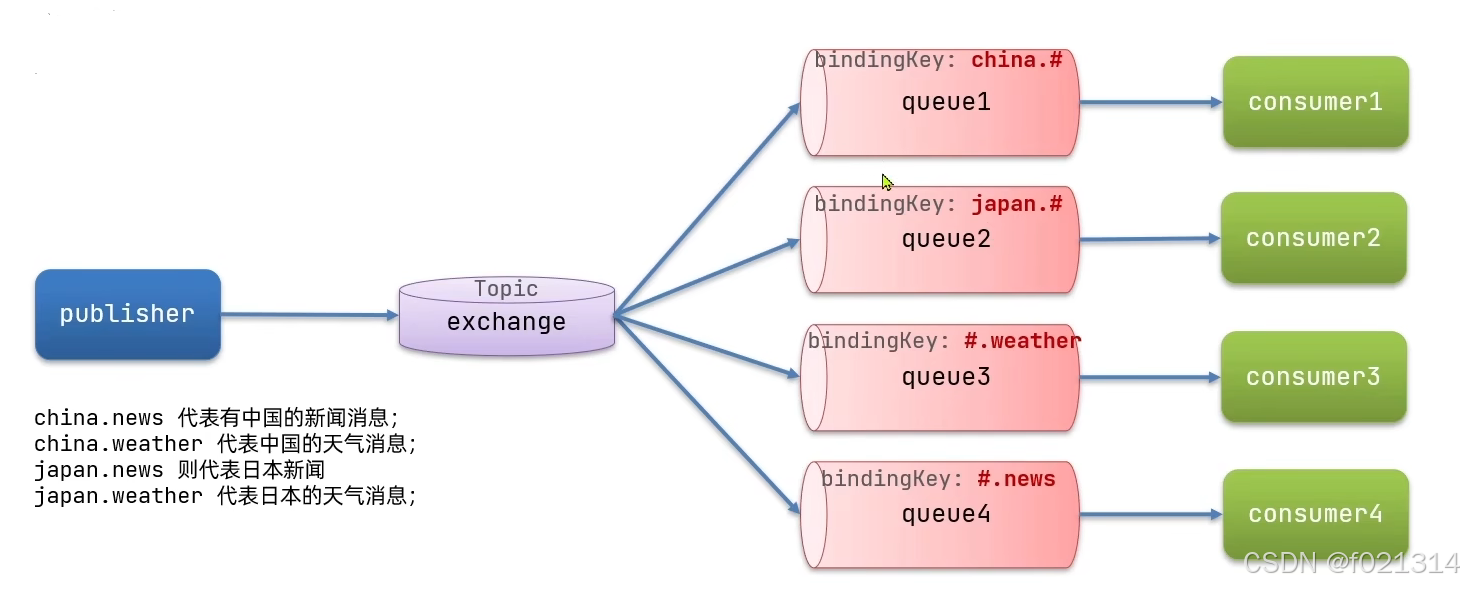
下面是消费者代码
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue1"),
exchange = @Exchange(name = "topic",type = ExchangeTypes.TOPIC),
key = "china.#"
))
public void listenTopicQueue1(String msg){
System.out.println("消费者1接收到direct.queue1的消息:【"+msg+"】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "topic.queue2"),
exchange = @Exchange(name = "topic",type = ExchangeTypes.TOPIC),
key = "#.news"
))
public void listenTopicQueue2(String msg){
System.err.println("消费者2接收到direct.queue2的消息:【"+msg+"】");
}下面是生产者代码
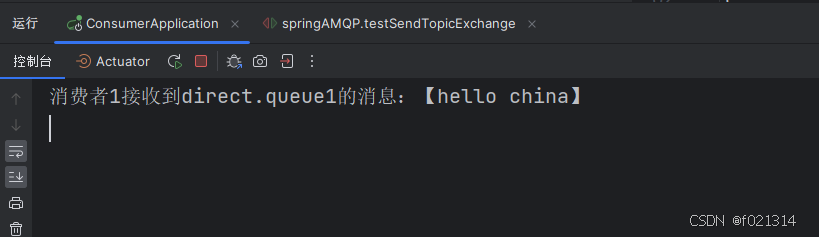
@Test
public void testSendTopicExchange(){
//交换机名称
String exchangeName = "topic";
//消息
String msg = "hello china";
//发送消息
rabbitTemplate.convertAndSend(exchangeName,"china.weacher",msg);
} 
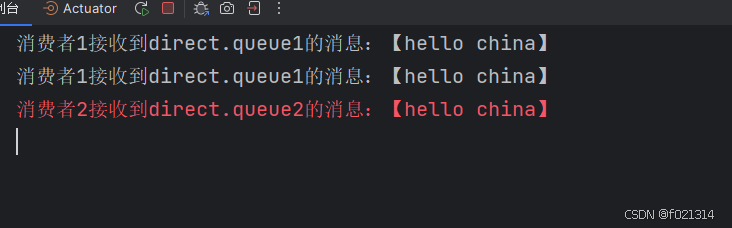
当对routingKey进行修改后,控制台也能输出其他信息
@Test
public void testSendTopicExchange(){
//交换机名称
String exchangeName = "topic";
//消息
String msg = "hello china";
//发送消息
rabbitTemplate.convertAndSend(exchangeName,"china.news",msg);
}
消息转换器
Spring的对消息对象的处理是出org.springframework.amgp.support.converter.MessageConverter来处理的。而默认实现是SimpleMessageConverter,基于JDK的ObjectOutputStream完成序列化。
如果要修改只需要定义一个MessageConverter 类型的Bean即可。推荐用JSON方式序列化,步骤如下:
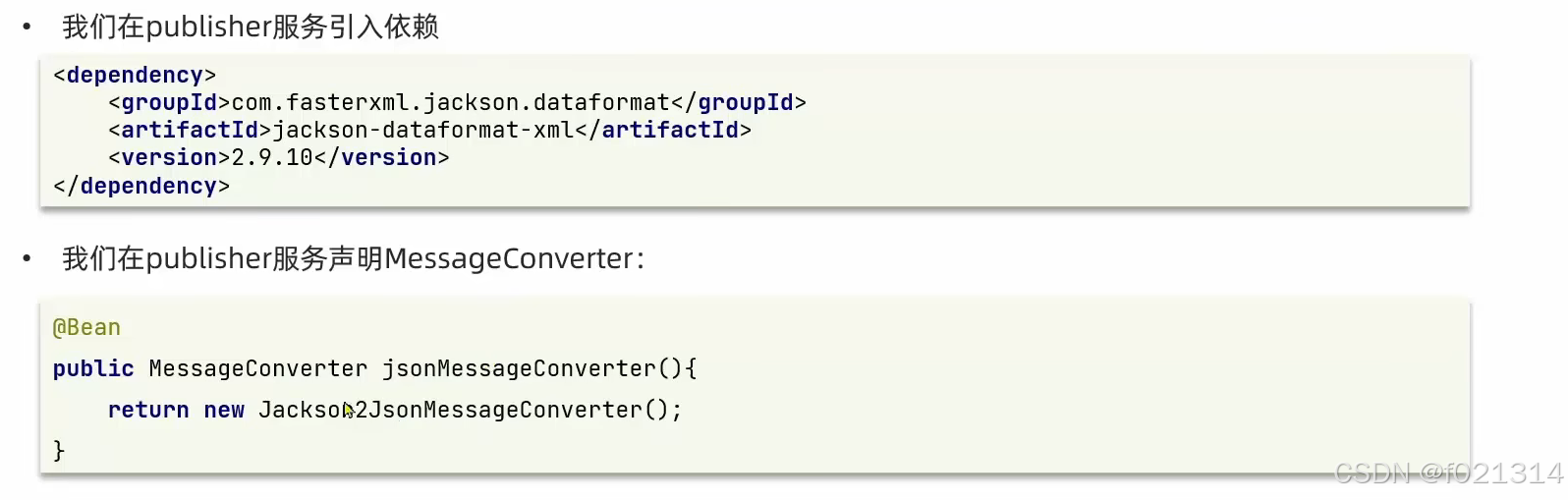
SpringAMQP中消息的序列化和反序列化实现:
- 利用Messageconvert@r实现的,默认是JDK的序列化
- 注意发送方与接收方必须使用相同的Messageconverter
elasticsearch
概况
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
elasticsearch:一个开源的分布式搜索引擎,可以用来实现搜索、日志统计、分析系统监控等功能。
elastic stack(ELK):是以elasticsearch为核心的技术栈,包括beats、Logstash、kibana、elasticsearch。
Lucene:是Apache的开源搜索引擎类库,提供了搜索引擎的核心API。
mysql和es
文档:一条数据就是一个文档,es中是Json格式
字段:Json文档中的字段
索引:同类型文档的集合
映射“”索引中文档的约束,比如字段名称、类型
elasticsearch与数据库的关系:
- 数据库负责事务类型操作
- elasticsearch负责海量数据的搜索、分析、计算
倒排索引
elasticsearch采用倒排索引
- 文档(document):每条数据就是一个文档
- 词条(term):文档按照语义分成的词语
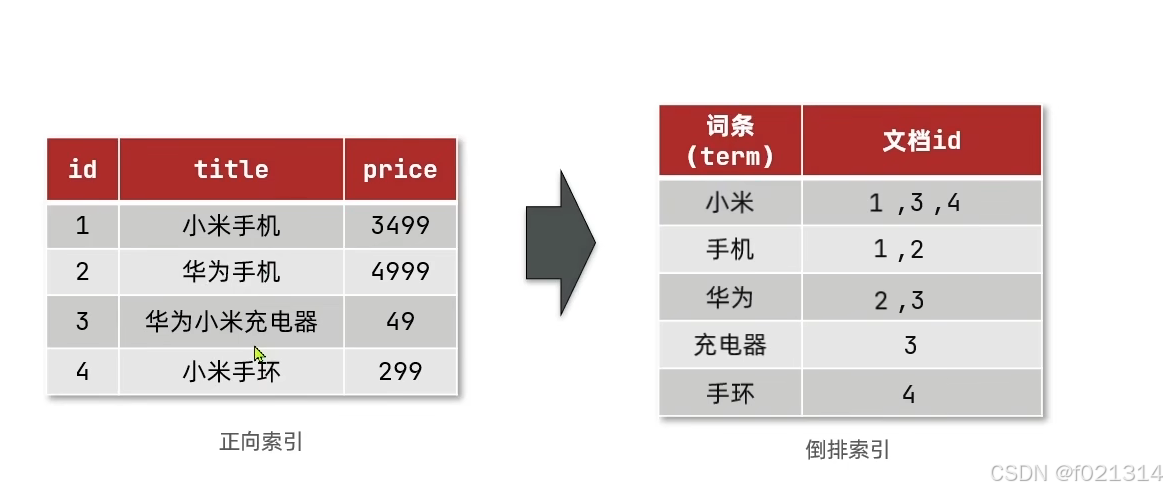
文档和词条
- 每一条数据就是一个文档
- 对文档中的内容分词,得到的词语就是词条
正向索引
- 基于文档id创建索引。查询词条时必须先找到文档,而后判断是否包含词条
倒排索引
- 对文档内容分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条查询到文档id,而后获取到文档
es的使用通常也搭配上kibana,来进行可视化展示。
 ik分词器
ik分词器
首先将ik分词器挂在到es的卷下,然后重启es。
[root@localhost ~]# docker volume inspect es-plugins
[
{
"CreatedAt": "2024-09-03T19:28:13-07:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]
[root@localhost ~]# cd /var/lib/docker/volumes/es-plugins/_data
[root@localhost _data]# ll
total 0
[root@localhost _data]# rz [root@localhost _data]# rz
[root@localhost _data]# ll
total 9660
-rw-r--r--. 1 root root 9888256 Sep 3 23:34 ik.tar
[root@localhost _data]# docker restart es
es
[root@localhost _data]# docker logs -f es | grep ik
{"type": "server", "timestamp": "2024-09-04T06:49:32,844Z", "level": "INFO", "component": "o.e.p.PluginsService", "cluster.name": "docker-cluster", "node.name": "d0ac3a40e83d", "message": "loaded plugin [analysis-ik]" }
{"type": "server", "timestamp": "2024-09-04T06:50:38,587Z", "level": "INFO", "component": "o.w.a.d.Dictionary", "cluster.name": "docker-cluster", "node.name": "d0ac3a40e83d", "message": "try load config from /usr/share/elasticsearch/config/analysis-ik/IKAnalyzer.cfg.xml", "cluster.uuid": "pnQ0UX12QL22R_YloCYMlA", "node.id": "3a4F-j6uSMm6tnNGTLjOXA" }
{"type": "server", "timestamp": "2024-09-04T06:50:38,607Z", "level": "INFO", "component": "o.w.a.d.Dictionary", "cluster.name": "docker-cluster", "node.name": "d0ac3a40e83d", "message": "try load config from /usr/share/elasticsearch/plugins/ik/config/IKAnalyzer.cfg.xml", "cluster.uuid": "pnQ0UX12QL22R_YloCYMlA", "node.id": "3a4F-j6uSMm6tnNGTLjOXA" }
之后再kibana页面端就能使用ik分词器
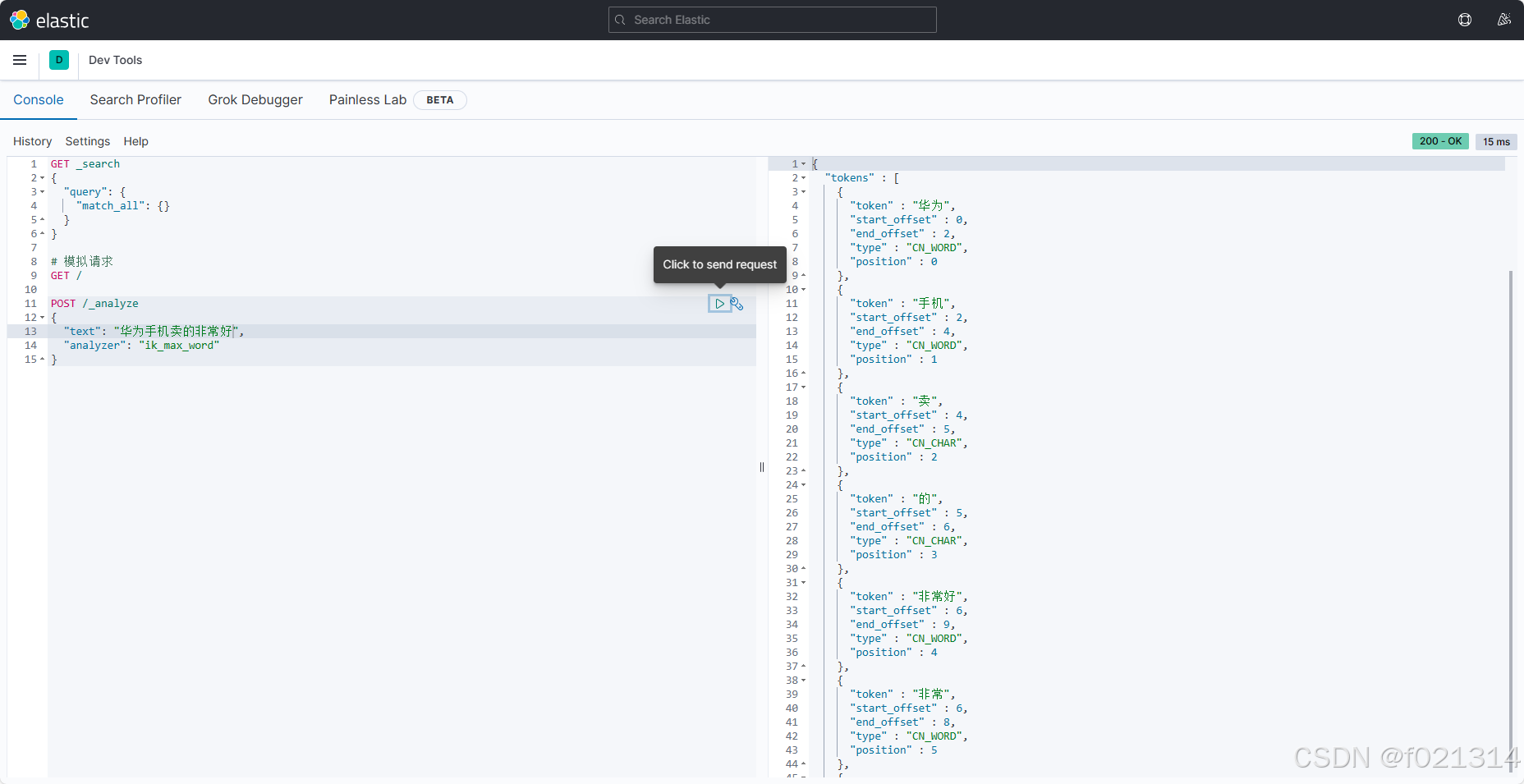
之所以他能将中文分词是因为它的背后有一套字典,但是不可能包含所有的词语,所以我们后期可以对它进行自定义设置。
要拓展ikK分词器的词库,只需要修改一个ik分词器目录中的config目录中的lkAnalyzer.cfg.xml文件
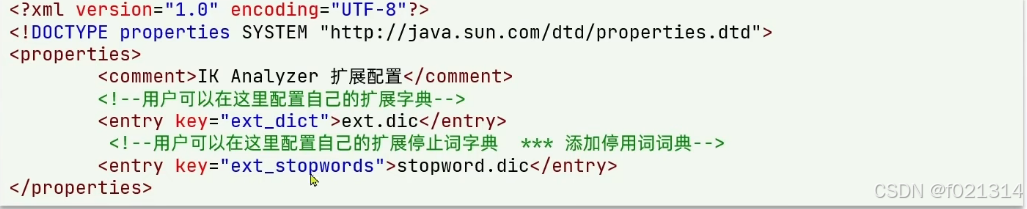
当我们对文件进行编辑前
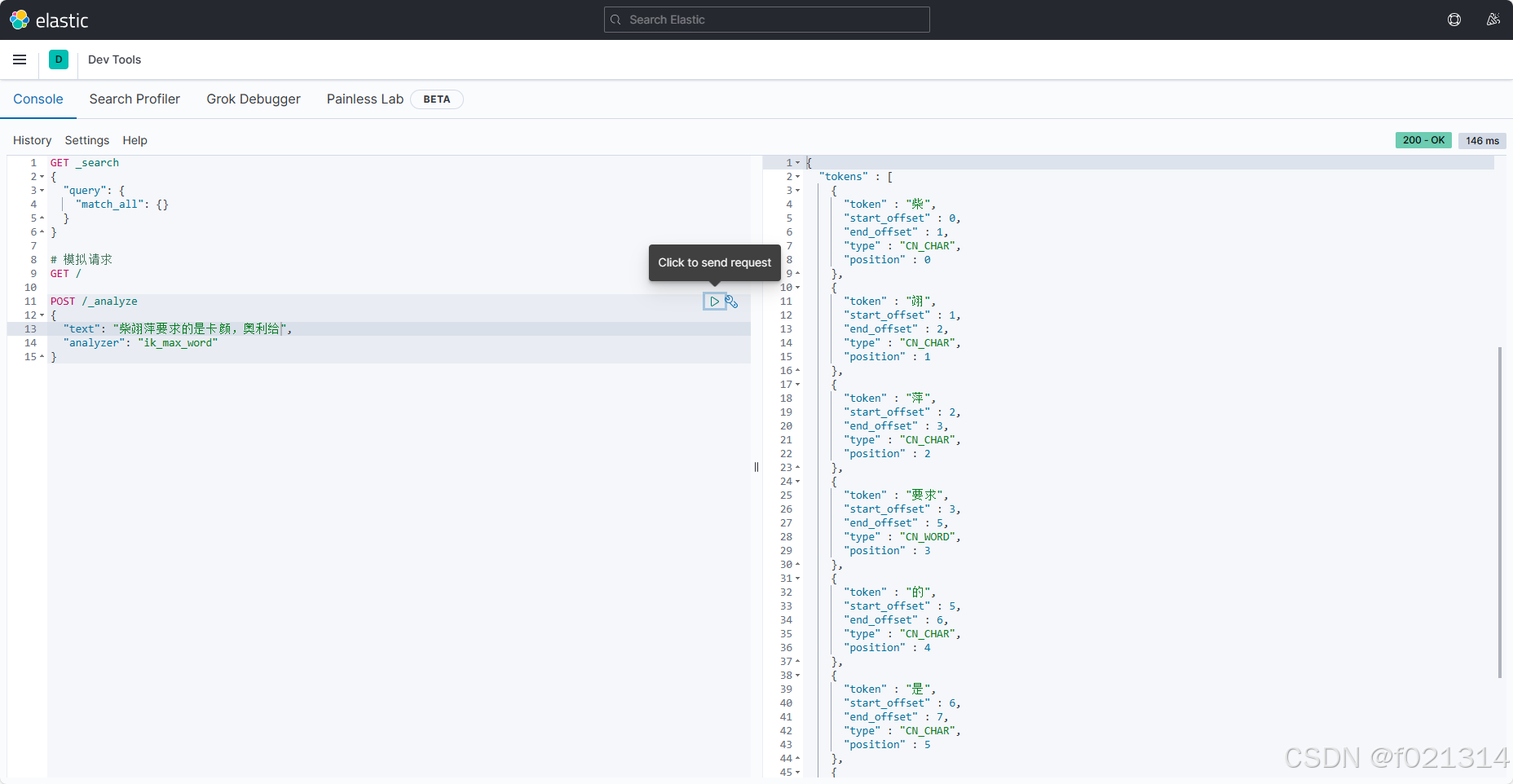
编辑后
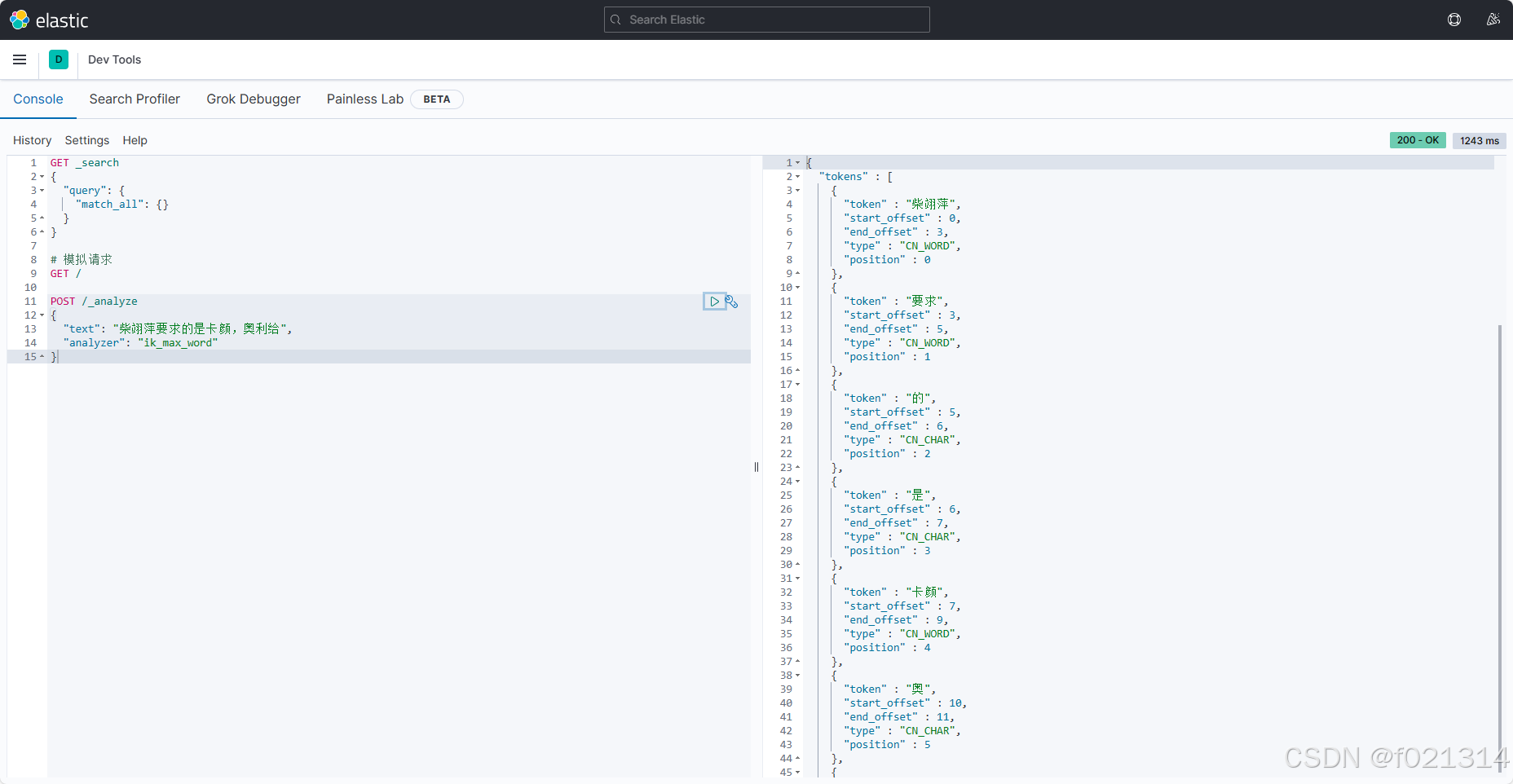 索引库
索引库
mapping属性

mapping常见属性
- type:数据类型
- index:是否索引
- analyzer:分词器
- properties:子字段
type常见的
- 字符串:text、keyword
- 数字:long、integer、short、byte、double、float
- 布尔:boolean
- 日期:date
- 对象:object
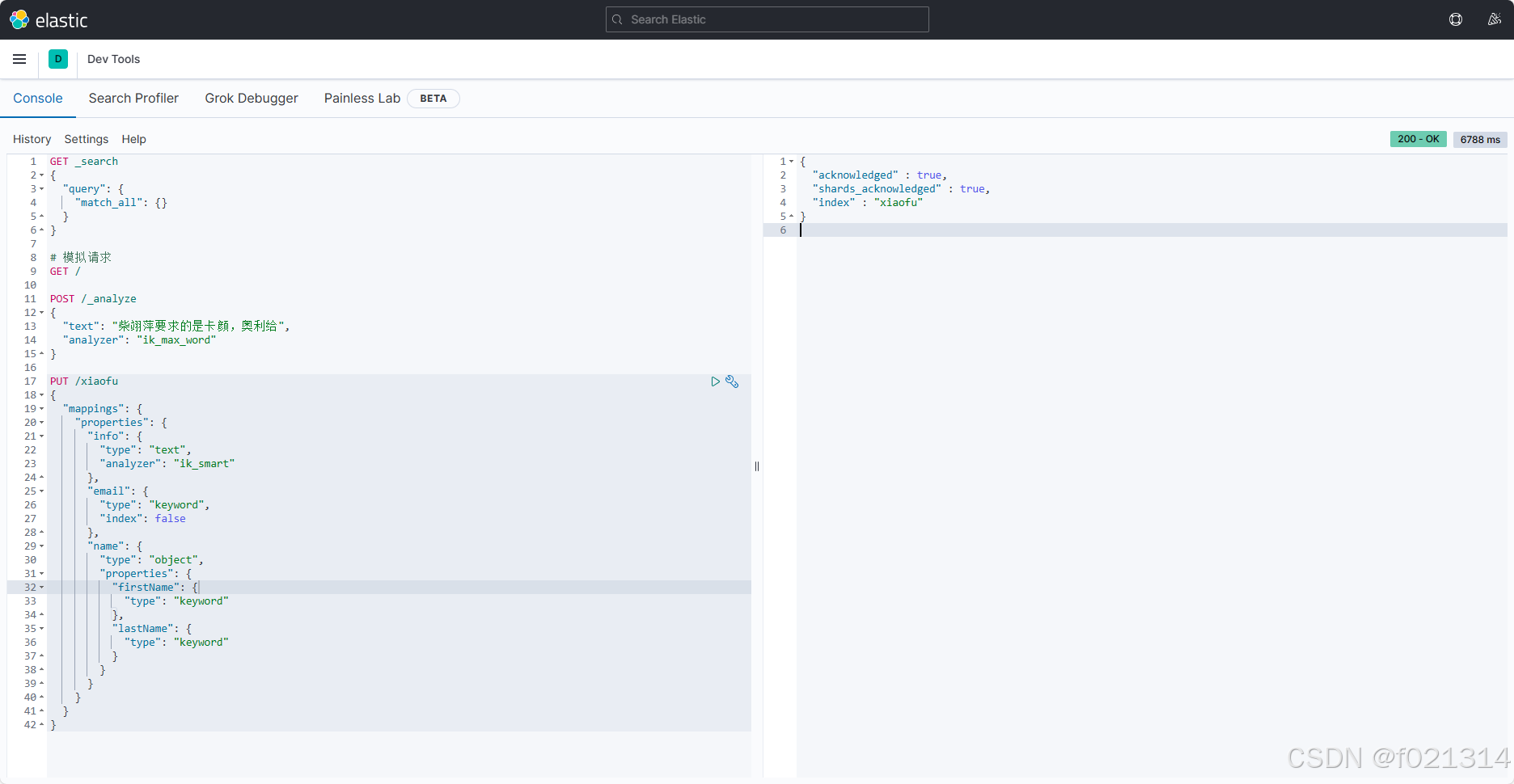
创建索引库
查看、删除索引库
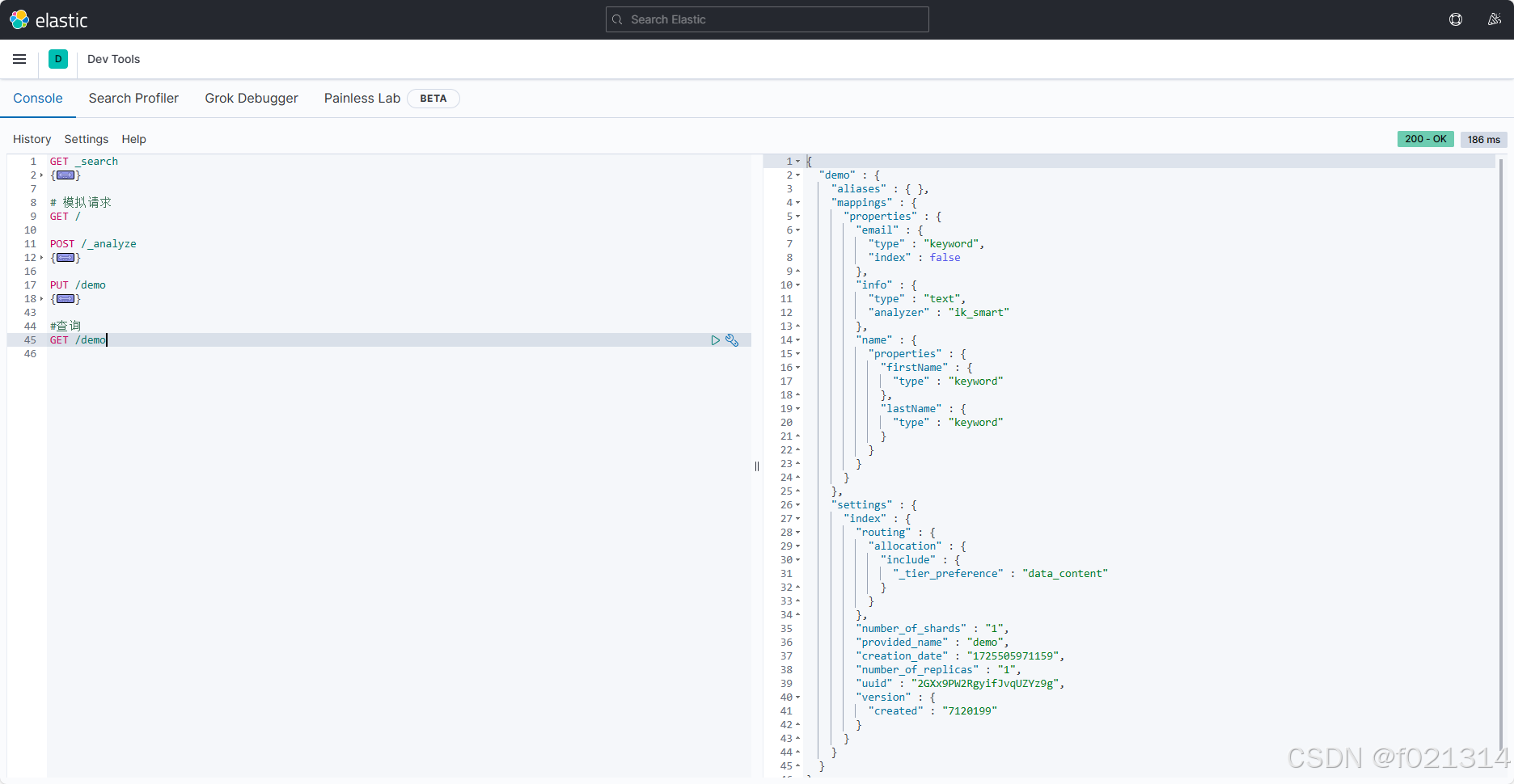
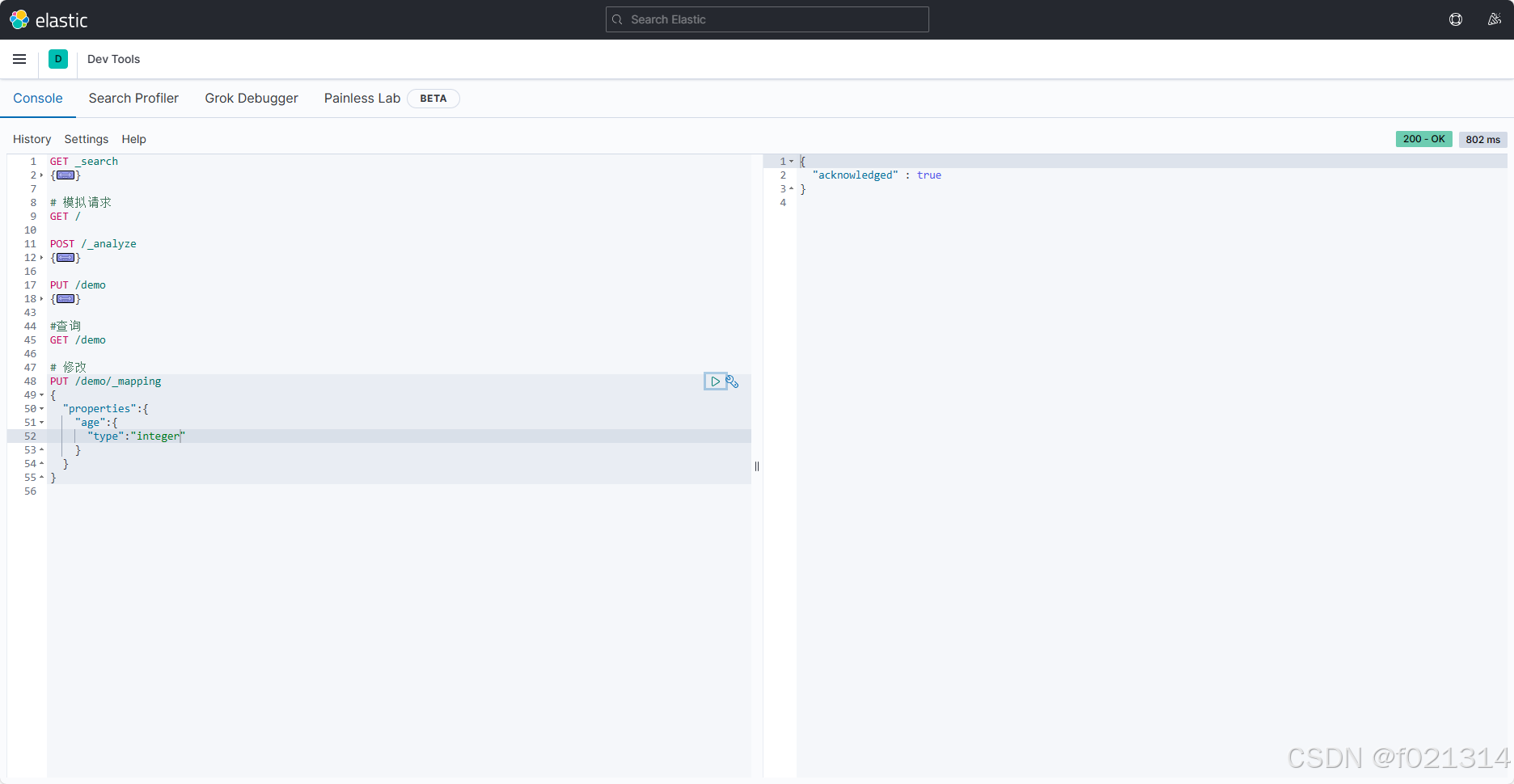
修改索引库
索引库和mapping一旦创建无法修改,但是可以添加新的字段
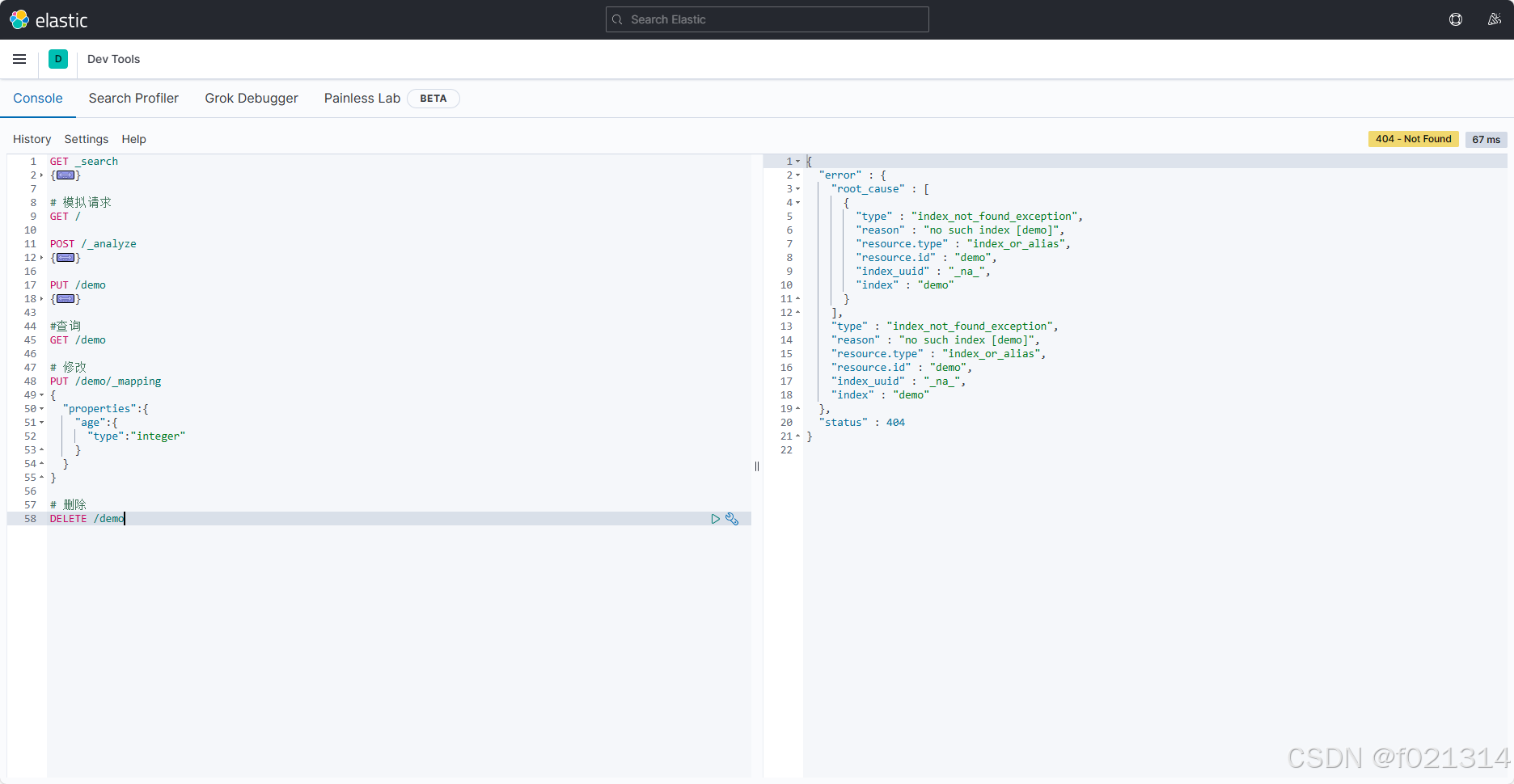
索引库操作
- 创建索引库:PUT /索引库名
- 查询索引库:GET/索引库名
- 删除索引库:DELETE/索引库名
- 添加字段:PUT/索引库名/mapping
文档操作
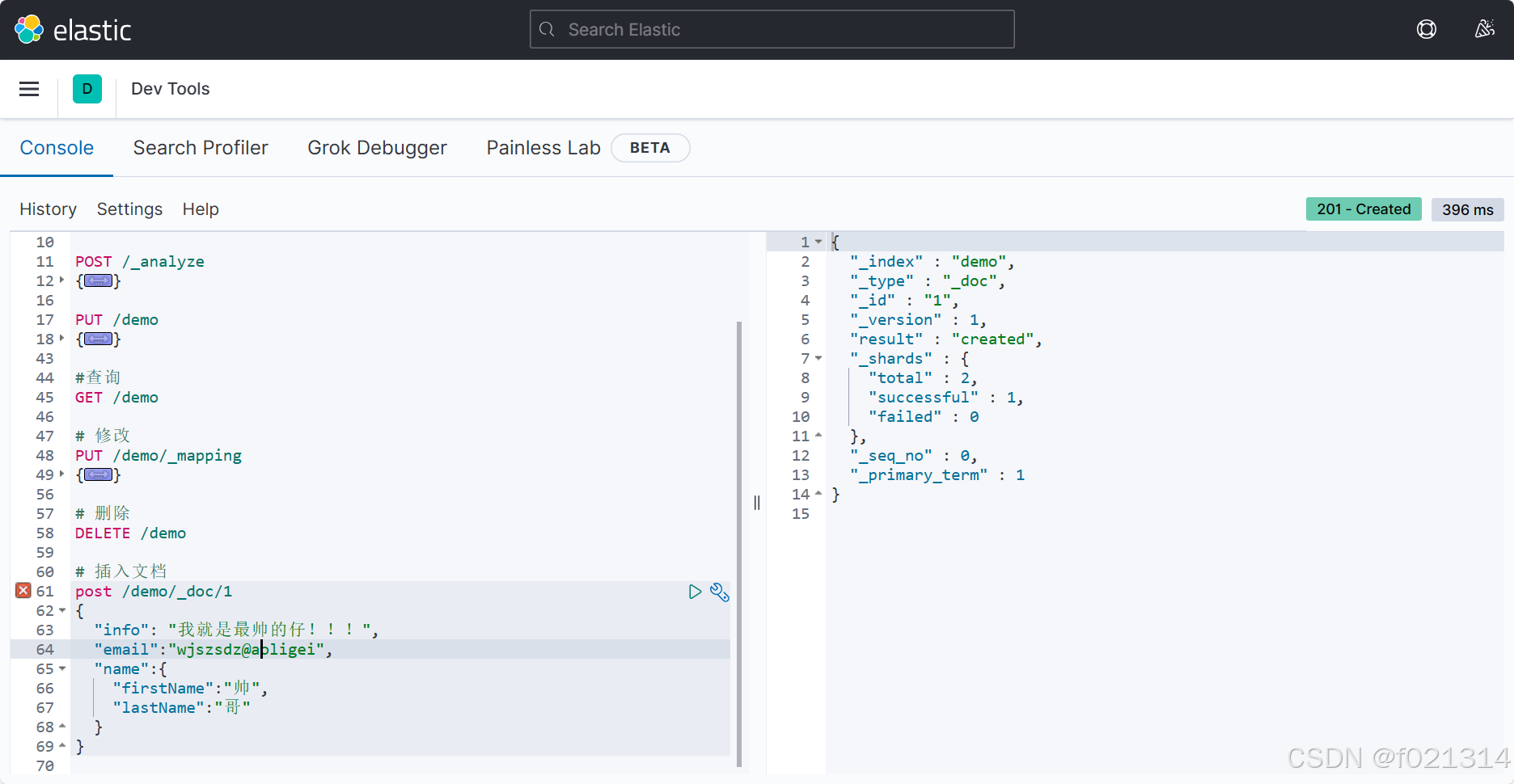
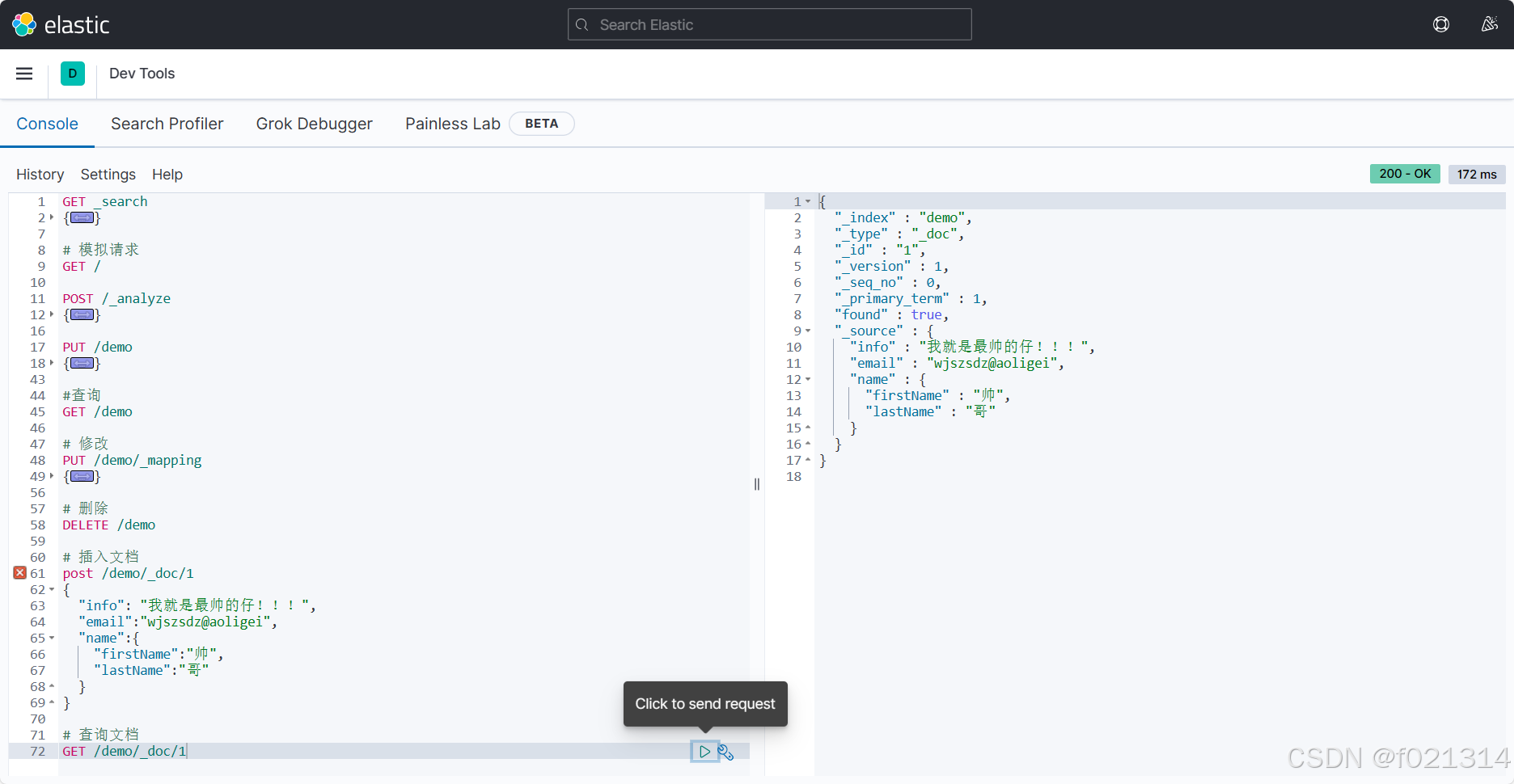
添加文档
修改文档
全量修改
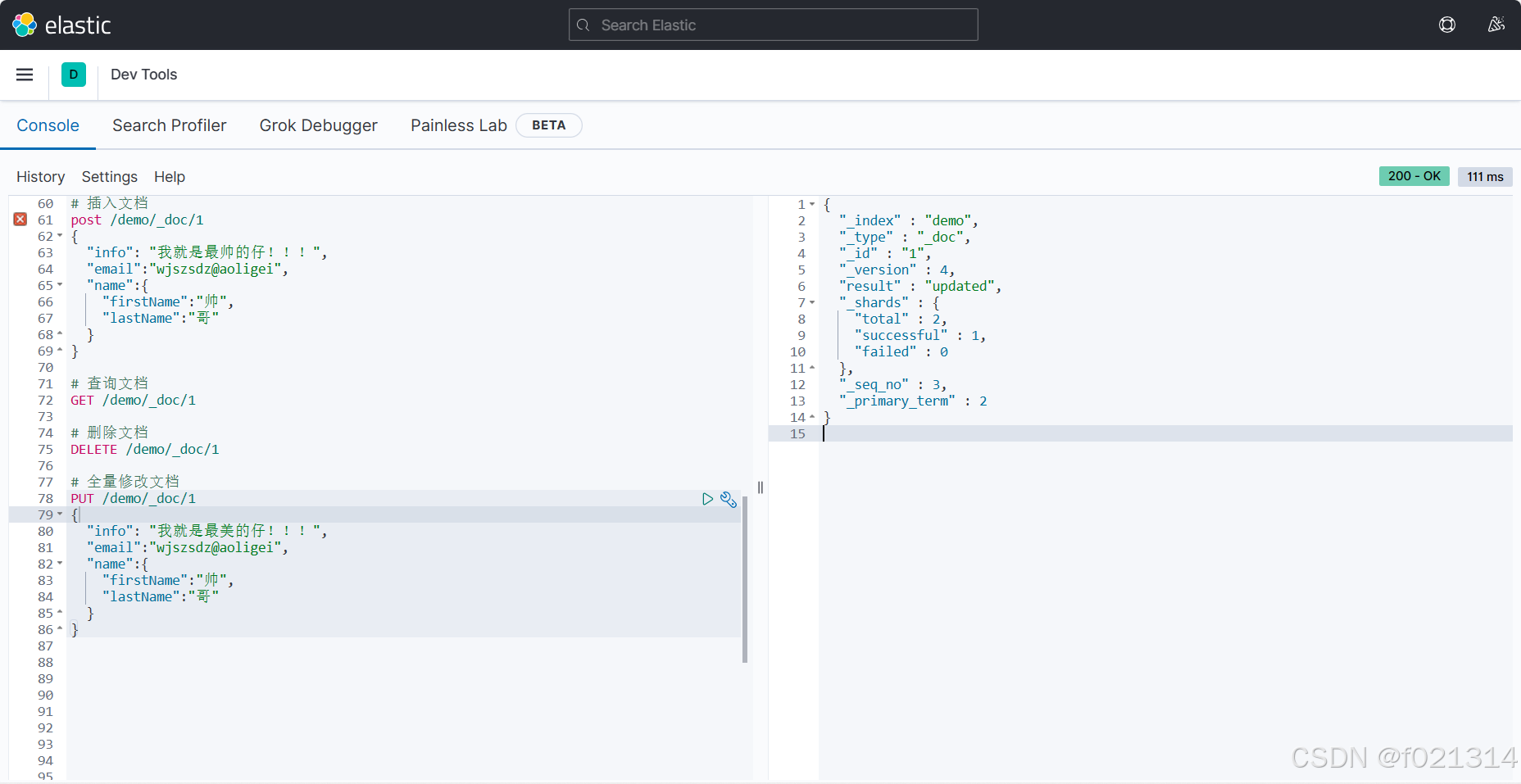
如果需要修改的id不存在,那么则变为添加文档。
局部修改
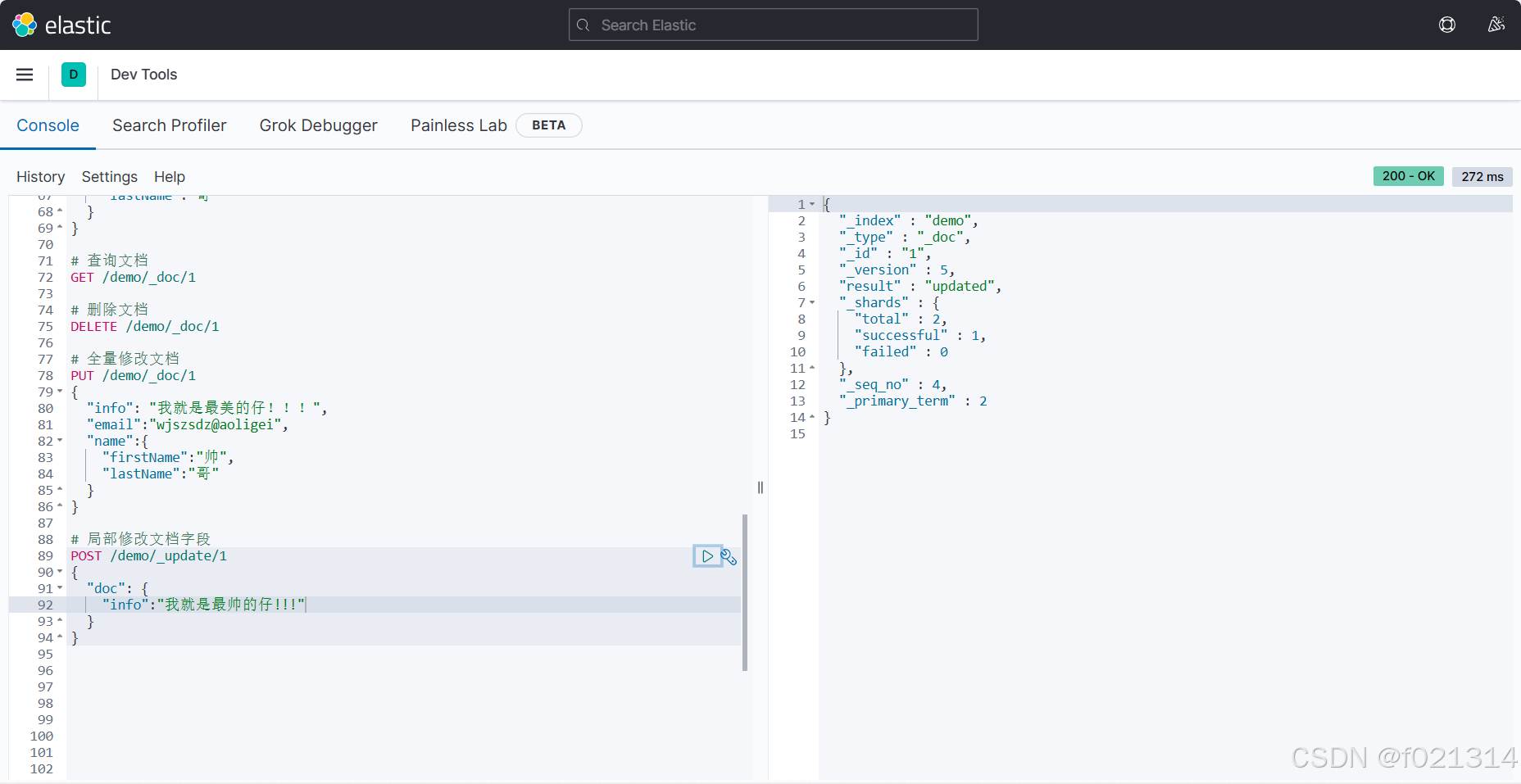
修改文档:
- 全量修改:PUT/索引库名/doc/文档id{json文档}
- 增量修改:POST/索引库名/update/文档id{"doc":{字段}}
RestClient操作索引库
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过htp请求发送给ES。官方文档地址:Elasticsearch Clients | Elastic
这部分内容可以看我的另外一篇文章,讲的是主要使用RestClient来进行项目的编写。
MinIo

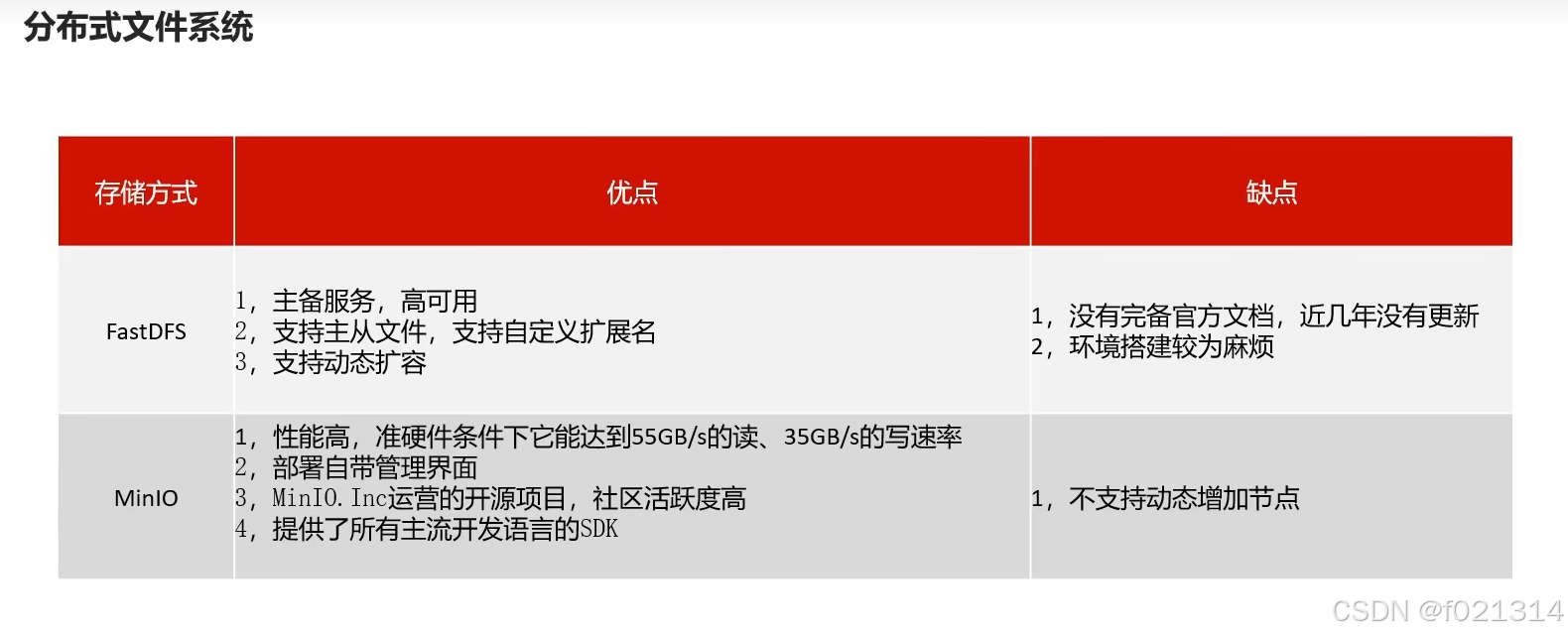
MinlO概述
Min10基于Apache License v2.0开源协议的对象存储服务,可以做为云存储的解决方案用来保存海量的图片,视频,文档。
- Golang语言实现,配置简单,单行命令可以运行起来。
- MinIO兼容亚马逊S3云存储服务接口,适合于存储大容量非结构化的数据,一个对象文件可以是任意大小,从几kb到最大5T不等。
- 官网文档:http://docs.minio.org.cn/docs/
查看密码:vim /etc/default/minio
后面需要使用java进行数据的配置,以便于我们在浏览器进行访问。
package com.heima.minio.test;
import com.heima.file.service.FileStorageService;
import io.minio.MinioClient;
import io.minio.PutObjectArgs;
import org.junit.Test;
import org.springframework.beans.factory.annotation.Autowired;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
public class MinIOTest {
public static void main(String[] args) {
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream("C:\\Users\\f1888\\Desktop\\badge_title.html");;
//1.创建minio链接客户端
MinioClient minioClient = MinioClient.builder().credentials("myminioadmin", "minio-secret-key-change-me").endpoint("http://192.168.112.140:9000").build();
//2.上传
PutObjectArgs putObjectArgs = PutObjectArgs.builder()
.object("badge_title.html")//文件名
.contentType("text/html")//文件类型
.bucket("news")//桶名词 与minio创建的名词一致
.stream(fileInputStream, fileInputStream.available(), -1) //文件流
.build();
minioClient.putObject(putObjectArgs);
System.out.println("http://192.168.112.140:9000/news/badge_title.html");
} catch (Exception ex) {
ex.printStackTrace();
}
}
@Autowired
private FileStorageService fileStorageService;
@Test
public void testUpdateImgFile() {
try {
FileInputStream fileInputStream = new FileInputStream("E:\\tmp\\ak47.jpg");
String filePath = fileStorageService.uploadImgFile("", "ak47.jpg", fileInputStream);
System.out.println(filePath);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
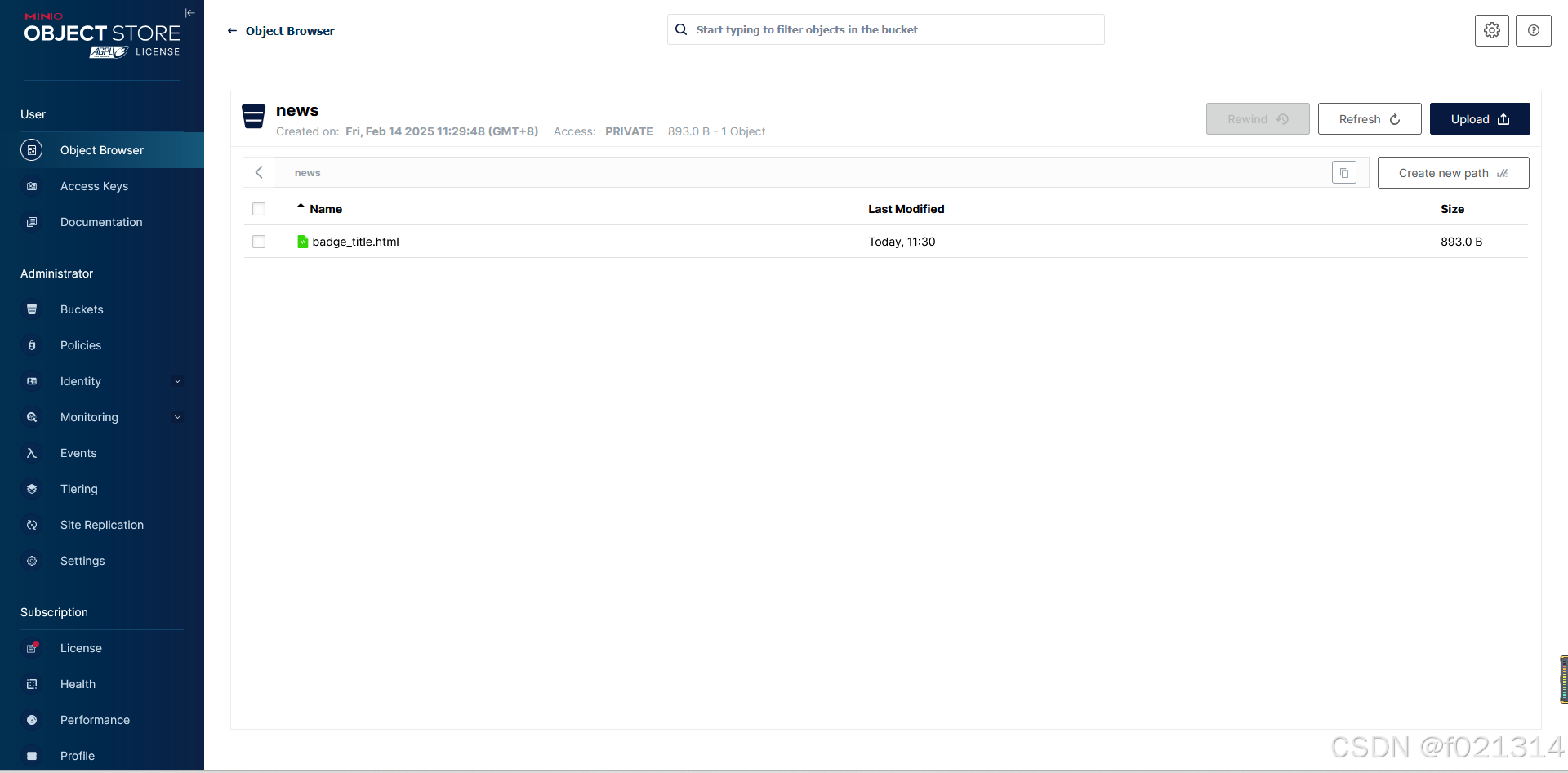
}上传完成后,MinIo中也会有相应的显示。
将MinIo封装为starter使用
先将配置文件写入application文件中
minio:
accessKey: myminioadmin
secretKey: minio123
bucket: news
endpoint: http://192.168.122.140:9000
readPath: http://192.168.122.140:9000包装完成后,便省去了每次配置文件的过程,下面就可以直接使用。
@Autowired
private FileStorageService fileStorageService;
@Test
public void testUpdateImgFile() {
try {
FileInputStream fileInputStream = new FileInputStream("C:\\Users\\f1888\\Desktop\\badge_title.html");
String filePath = fileStorageService.uploadImgFile("", "badge_title.html", fileInputStream);
System.out.println(filePath);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
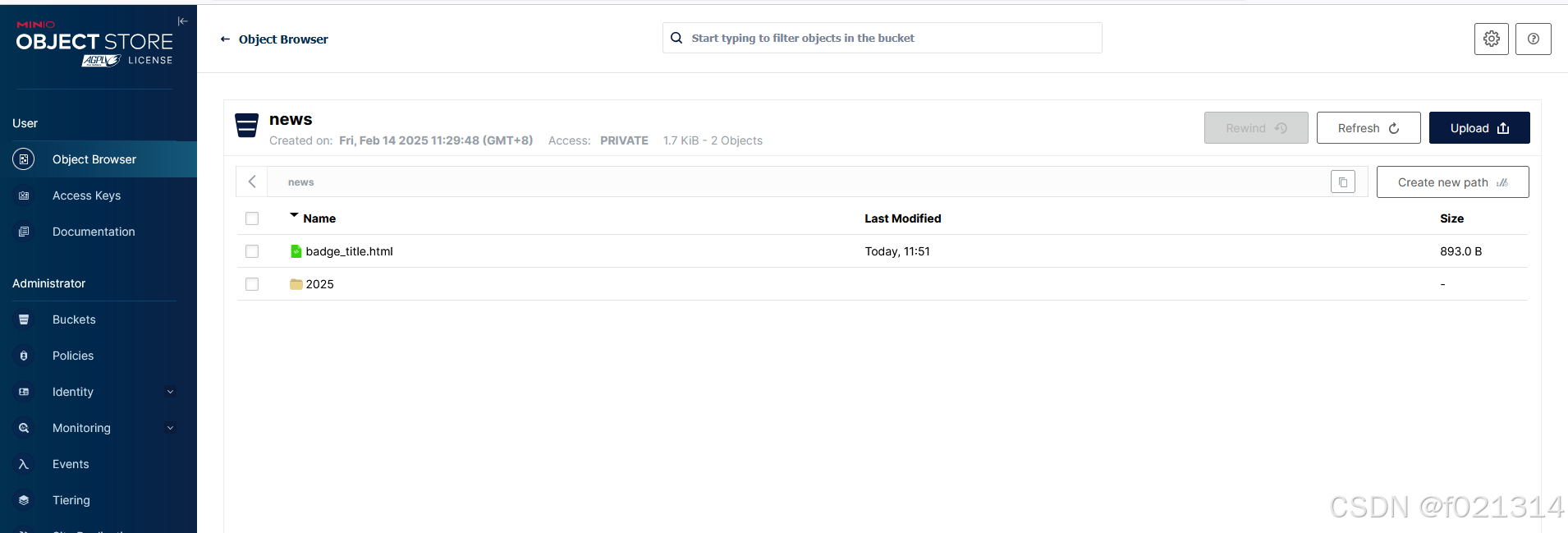
使用封装的MinIo成功也上传了数据。
MinIo的使用
在日常开发中,部分静态资源使用freemarker生成之后,可以存储在MinIo中,避免多次重复请求。
下面是一个具体到代码流程
@SpringBootTest(classes = ArticleApplication.class)
@RunWith(SpringRunner.class)
public class ArticleFreemarkerTest {
@Autowired
private Configuration configuration;
@Autowired
private FileStorageService fileStorageService;
@Autowired
private ApArticleMapper apArticleMapper;
@Autowired
private ApArticleContentMapper apArticleContentMapper;
@Test
public void createStaticUrlTest() throws Exception {
//1.获取文章内容
ApArticleContent apArticleContent = apArticleContentMapper.selectOne(Wrappers.<ApArticleContent>lambdaQuery().eq(ApArticleContent::getArticleId, 1404705243362627586L));
if (apArticleContent != null && StringUtils.isNotBlank(apArticleContent.getContent())) {
//2.文章内容通过freemarker生成html文件
StringWriter out = new StringWriter();
Template template = configuration.getTemplate("article.ftl");
Map<String, Object> params = new HashMap<>();
params.put("content", JSONArray.parseArray(apArticleContent.getContent()));
template.process(params, out);
InputStream is = new ByteArrayInputStream(out.toString().getBytes());
//3.把html文件上传到minio中
String path = fileStorageService.uploadHtmlFile("", apArticleContent.getArticleId() + ".html", is);
//4.修改ap_article表,保存static_url字段
ApArticle article = new ApArticle();
article.setId(apArticleContent.getArticleId());
article.setStaticUrl(path);
apArticleMapper.updateById(article);
}
}
}图片上传功能
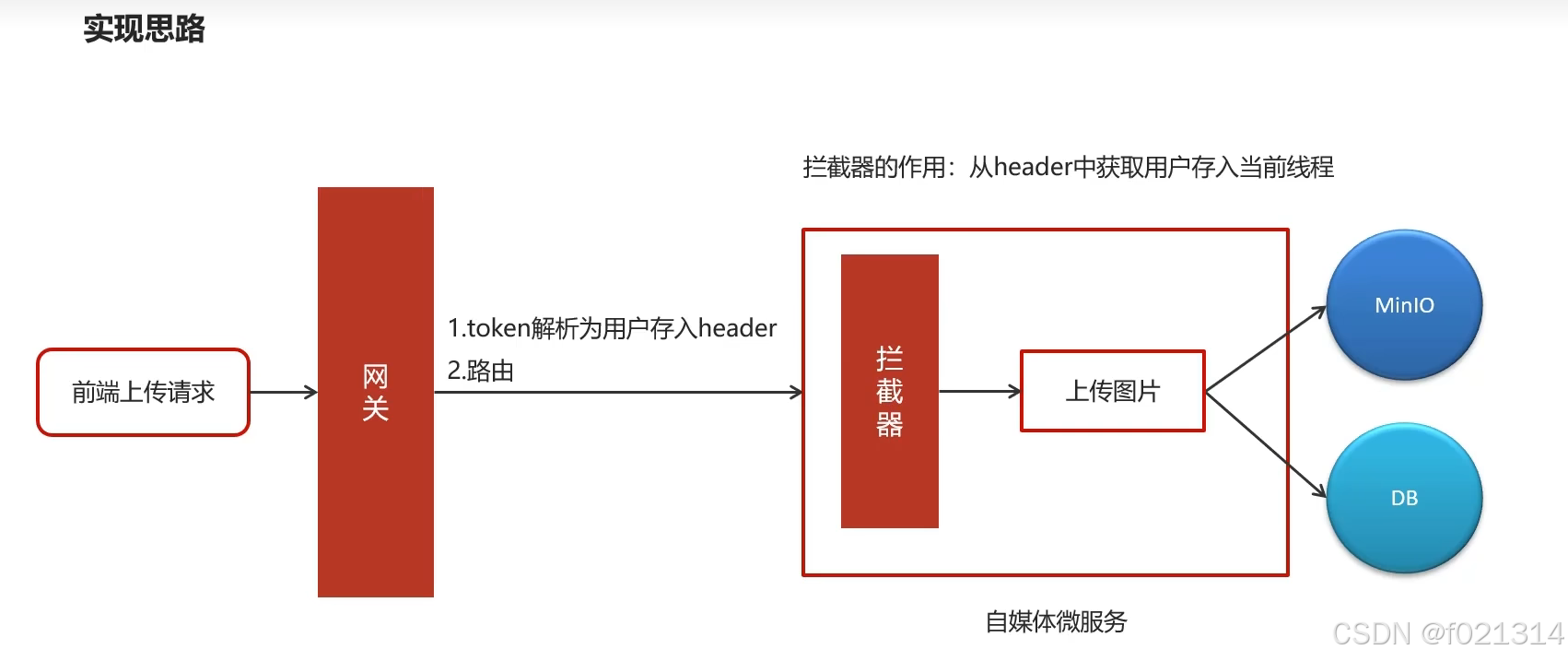
在存放用户上传的图片前,我们先对用户的身份进行一个校验,也就是对请求进行验权
@Component
@Slf4j
public class AuthorizeFilter implements Ordered, GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//1.获取request和response对象
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
//2.判断是否是登录
if(request.getURI().getPath().contains("/login")){
//放行
return chain.filter(exchange);
}
//3.获取token
String token = request.getHeaders().getFirst("token");
//4.判断token是否存在
if(StringUtils.isBlank(token)){
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
//5.判断token是否有效
try {
Claims claimsBody = AppJwtUtil.getClaimsBody(token);
//是否是过期
int result = AppJwtUtil.verifyToken(claimsBody);
if(result == 1 || result == 2){
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
//获取用户信息
Object userId = claimsBody.get("id");
//存储header中
ServerHttpRequest serverHttpRequest = request.mutate().headers(httpHeaders -> {
httpHeaders.add("userId", userId + "");
}).build();
//重置请求
exchange.mutate().request(serverHttpRequest);
} catch (Exception e) {
e.printStackTrace();
}
//6.放行
return chain.filter(exchange);
}
/**
* 优先级设置 值越小 优先级越高
* @return
*/
@Override
public int getOrder() {
return 0;
}
}然后设置拦截器
public class WmTokenInterceptor implements HandlerInterceptor {
/**
* 得到header中的用户信息,并且存入到当前线程中
* @param request
* @param response
* @param handler
* @return
* @throws Exception
*/
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String userId = request.getHeader("userId");
if(userId != null){
//存入到当前线程中
WmUser wmUser = new WmUser();
wmUser.setId(Integer.valueOf(userId));
WmThreadLocalUtil.setUser(wmUser);
}
return true;
}
/**
* 清理线程中的数据
* @param request
* @param response
* @param handler
* @param modelAndView
* @throws Exception
*/
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
WmThreadLocalUtil.clear();
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
}
}接着创建配置类,让我们的拦截器生效
@Configuration
public class WebMvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new WmTokenInterceptor()).addPathPatterns("/**");
}
}
最后是将图片上传至MinIo的具体逻辑代码
@Slf4j
@Service
@Transactional
public class WmMaterialServiceImpl extends ServiceImpl<WmMaterialMapper, WmMaterial> implements WmMaterialService {
@Autowired
private FileStorageService fileStorageService;
/**
* 图片上传
* @param multipartFile
* @return
*/
@Override
public ResponseResult uploadPicture(MultipartFile multipartFile) {
//1.检查参数
if(multipartFile == null || multipartFile.getSize() == 0){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
//2.上传图片到minIO中
String fileName = UUID.randomUUID().toString().replace("-", "");
//aa.jpg
String originalFilename = multipartFile.getOriginalFilename();
String postfix = originalFilename.substring(originalFilename.lastIndexOf("."));
String fileId = null;
try {
fileId = fileStorageService.uploadImgFile("", fileName + postfix, multipartFile.getInputStream());
log.info("上传图片到MinIO中,fileId:{}",fileId);
} catch (IOException e) {
e.printStackTrace();
log.error("WmMaterialServiceImpl-上传文件失败");
}
//3.保存到数据库中
WmMaterial wmMaterial = new WmMaterial();
wmMaterial.setUserId(WmThreadLocalUtil.getUser().getId());
wmMaterial.setUrl(fileId);
wmMaterial.setIsCollection((short)0);
wmMaterial.setType((short)0);
wmMaterial.setCreatedTime(new Date());
save(wmMaterial);
//4.返回结果
return ResponseResult.okResult(wmMaterial);
}
/**
* 素材列表查询
* @param dto
* @return
*/
@Override
public ResponseResult findList(WmMaterialDto dto) {
//1.检查参数
dto.checkParam();
//2.分页查询
IPage page = new Page(dto.getPage(),dto.getSize());
LambdaQueryWrapper<WmMaterial> lambdaQueryWrapper = new LambdaQueryWrapper<>();
//是否收藏
if(dto.getIsCollection() != null && dto.getIsCollection() == 1){
lambdaQueryWrapper.eq(WmMaterial::getIsCollection,dto.getIsCollection());
}
//按照用户查询
lambdaQueryWrapper.eq(WmMaterial::getUserId,WmThreadLocalUtil.getUser().getId());
//按照时间倒序
lambdaQueryWrapper.orderByDesc(WmMaterial::getCreatedTime);
page = page(page,lambdaQueryWrapper);
//3.结果返回
ResponseResult responseResult = new PageResponseResult(dto.getPage(),dto.getSize(),(int)page.getTotal());
responseResult.setData(page.getRecords());
return responseResult;
}
}
















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









