







人生的挫折感并不取决于境遇本身,而取决于境遇和自我期待之间的落差。
概述
对interface类型操作,如何对内部的值进行处理和分析。比如判断interface是否底层存储的是struct类型,以及该struct是否含有某个特定的Field值。
interface类型包含两部分内容:dynamic type和dynamic value。当转换为interface类型后(操作是默认的),原类型下声明的方法,interface类型就无法再调用了。
实际工作中,interface类型会接收任意类型的值,处理的过程很多都是通过reflect实现的。很多文章都有提到,反射会影响应用程序的性能,但很多框架都在使用反射,比如 fmt、json、xorm、rpc等。我们可以利用反射抽象一种处理模式,简化应用程序处理。
文章使用 go1.17 的源码,不同版本的代码可能会有变动。
reflect value
reflect里两个主要角色:Value和Type。Value用于处理值的操作,反射过程中处理的值是原始值的值拷贝,所以操作中要注意区分值传递和地址传递。
对于指针类型的值,只有获取其原始值,才可以达到修改的目的。如下所示,obj实际类型是一个struct的指针,想要将其转换成“值类型”,调用Elem方法来实现。
//获取指针的实际类型
v := reflect.ValueOf(obj) //Kind == Ptr
v = v.Elem()
if v.Kind() != reflect.Struct {
return NewError(http.ErrorInvalidParam, "interface类型必须是struct结构", nil)
}
一些其他的操作,比如通过reflect.Value获取reflect.Type类型,通过诸如Index、Elem、MapIndex、Field等来操作不同的数据类型,当然调用前最好结合Kind对实际类型进行判断,保证调用的安全性。
IsValid
IsValid 用来检测反射的结果是否是零值,这个和类型的默认零值是有区别的。字符串的默认零值是空字符串,int 的默认零值是 0。但如果用 IsValid 来验证这些类型的零值,IsValid 返回的是 true,而非 false。
// IsValid reports whether v represents a value.
// It returns false if v is the zero Value.
// If IsValid returns false, all other methods except String panic.
// Most functions and methods never return an invalid Value.
// If one does, its documentation states the conditions explicitly.
func (v Value) IsValid() bool {
return v.flag != 0
}
下面的两种情况,IsValid 都会返回 false。nil 值的反射可以检测到类型的零值。如果是非指针类型,调用 IsValid 有意义吗?关键还是我们是否能在值类型上判断 IsValid 为 false 的情况。
fmt.Println(reflect.Value{}.IsValid())
fmt.Println(reflect.ValueOf(nil).IsValid())
通过 nil 指针类型取 Elem 也可以模拟零值。那么,这零值和 0 为什么不一样呢?我的理解是:值没有被设置。如果是值类型,声明的时候是有默认值的。但如果是指针类型,声明的时候也有 nil 的默认值,但内部实际的值并没有被设置。

fmt.Println(reflect.ValueOf((*int)(nil)).Elem().IsValid())
基于上面的思考,我们对下面这几种 IsValid 的作用就会好理解些。判断结构体中某个字段是否存在,如果查找的是一个不存在的字段,IsValid 返回的就是 false,或者下面的几种情况:
// 查找结构体中不存在的字段
s := struct{}{}
fmt.Println(reflect.ValueOf(s).FieldByName("").IsValid())
// 查找结构体中不存在的方法
fmt.Println(reflect.ValueOf(s).MethodByName("").IsValid())
// 查找 map 中未设置的值
m := map[int]int{}
fmt.Println(reflect.ValueOf(m).MapIndex(reflect.ValueOf(3)).IsValid())
map 反射
反射后的 map 类型也应该具有反射前的特性,从 map 中读取特定的值,给特定的 key 赋值,以及遍历整个 map。当然,也应该包含创建一个 map 类型,只不过因为是反射类型的缘故,在操作上就会多出来一层反射的封装。
创建
下面的例子,我们通过 map 类型反射创建了一个新的 map 实例。但这种创建方式还是比较少见的,在生产过程中,我们往往是通过 key 的类型和 value 的类型来直接创建 map 类型的。
em := make(map[string]bool)
typ := reflect.TypeOf(em)
val := reflect.MakeMap(typ)
直接通过 type 类型和 value 类型来创建 map 类型,关键的方法是 MapOf 和 MakeMapWithSize 两个方法。通过 MapOf 的方法可以看出,map 中管理的是key 和 elem 的类型,而且 key 的类型必须是可以做等于比较的。
func main() {
var key = "6578476"
var value = true
var keyType = reflect.TypeOf(key)
var valueType = reflect.TypeOf(value)
var mapType = reflect.MapOf(keyType, valueType)
m := reflect.MakeMapWithSize(mapType, 0)
m.SetMapIndex(reflect.ValueOf(key), reflect.ValueOf(value))
}
遍历
如何读取 map 的 key 和 value 呢,一种是已知 key 直接读取,另一种是遍历。反射的 map 类型提供了两种遍历方式:第一种是获取到所有的 key 列表,通过遍历 key 间接实现遍历 map 的目的;第二种直接使用 map 迭代器来遍历。
// 通过key来间接遍历
keys := m.MapKeys()
for _, key := range keys {
v := m.MapIndex(key)
}
// 通过迭代器来遍历
it := m.MapRange()
for it.Next() {
fmt.Printf("m[%v] = %v\n", it.Key(), it.Value())
}
说到底就是熟练使用 reflect 包提供的能力,可以在反射层面轻松搞定 map,这也不存在什么门槛,“我亦无他,惟手熟尔”。
Slice
修改元素
下面演示通过反射给切片修改值,首先,什么场景下需要通过反射来修改切片的值呢?假设下面的结构体,Live 表示电影,Histroy 表示电影的历史,现在需要将 History 中所有电影的 Price 置为 0。如果 Histroy 结构体成员字段比较少,可以多写几次循环遍历来修改每个成员的 Price,但如果 History 的成员分类特别多呢?
“针对这个场景,我有个不成熟的想法”,作为程序开发,通过重复堆砌简单代码逻辑,解决不是特别复杂的问题,是体现不出自己价值的。既然要写,就要笔走龙蛇,不仅仅解决当下的问题,还要扩展性解决未来的问题。反射是解决重复劳动的工具之一,只要合理控制好反射的性能,恰当的缓存反射的结果、避免一些耗时的反射函数,反射对程序员还是非常友好的。
type Live struct {
Title string
Price uint32
Category uint32
}
type History struct {
Action []Live // 动作电影
Emotion []Live // 感情
Suspense []Live // 悬疑
}
下面代码修改切片 lives 中的元素,将第一个元素的 Price 设置为 3。注意,所修改的是 lives 第一个元素而非变量 earth,它们是两个独立的变量。其中,关键的反射函数 Index,用来返回切片索引位置的元素。FieldByName 获取结构体对应的值,最后,Set 用来做赋值。
func main() {
earth := Live{
Title: "流量地球",
Price: 1,
}
lives := []Live{earth}
rv := reflect.ValueOf(lives)
// fmt.Println(rv.CanSet())
rv.Index(0).FieldByName("Price").Set(reflect.ValueOf(uint32(3)))
fmt.Println(lives)
}
使用 Set 赋值的对象必须是 CanSet 的,因为切片的底层数组是引用传递的,所以,切片中的元素是 CanSet 的,而变量 rv 却不是 CanSet 的。
append元素
append属于切片的核心操作,在反射中也有对应的函数。下面的例子演示了 AppendSlice 方法的使用,对比 Go 非反射的场景,切片 a 和 b 的合并应该是这样的 append(a, b...)。这也可以理解,应为 bv 的类型其实是 reflect.Value,不能支持 … 的展开语法。
func main() {
a := []int{1, 2}
b := []int{3, 4}
av := reflect.ValueOf(a)
bv := reflect.ValueOf(b)
result := reflect.AppendSlice(av, bv)
fmt.Println(result.Interface())
}
除此之外,还提供了 Append 方法,也比非反射场景用起来更顺手。 Append 方法其实是支持 … 展开语法的,只不过需要构造 reflect.Value 类型的切片
func main() {
a := []int{1, 2}
av := reflect.ValueOf(a)
result := reflect.Append(av, reflect.ValueOf(3), reflect.ValueOf(4))
fmt.Println(result)
}
func
通过反射创建slice、map、func 等对象,业务代码中并不常见,主要在一些框架类的代码中会用到。但熟悉反射的创建,能让我们遇到这些反射的场景时,不会那么惶恐,尤其在我们一眼看明白框架实现的细节时,多多少少会感觉轻松自在。
对函数反射来说,我之前有用到的一个简单场景:客户端通过 curl 请求服务端的接口,参数指定方法名。服务端接受到请求后,查找对应的方法,执行并返回结果。具体实现的细节,本质上就是下面的代码。
type SceneProcess struct {
}
func (f SceneProcess) FixNameTask(ctx context.Context) {
fmt.Println("Do fix name scene")
}
func main() {
scene := &SceneProcess{}
reflect.ValueOf(scene).MethodByName("FixNameTask").Call([]reflect.Value{
reflect.ValueOf(context.TODO())})
}
通过参数 FixNameTask 查找对象 SceneProcess 中的方法,然后调用 Call 执行。如果结构体中没有实现 FixNameTask 方法, 上述代码会触发 panic,生产环境一定要做好边界处理。
事实上,func 的反射有很多更高级的用法,但也存在一些限制。如果我想在运行时重写 FixNameTask 的方法,能通过反射实现吗?我们知道反射中使用 Set 方法可以修改值,那么,是否可以将上述代码调用 Call 改为调用 Set 方法?事与愿违,程序会触发异常: reflect.Value.Set using unaddressable value 。
我们可以换个角度,虽然方法 FixNameTask 不能被修改,但 SceneProcess 结构体的成员却是可以被修改的,我们可以利用这个特性,在结构体中声明一个方法类型的字段,动态更改这个成员的实现。
我们在结构体中声明了 ReFixNameTask 成员,类型是函数。注意,我们要动态实现这个字段指向的函数,通过 Set 方法指定,通过反射创建方法,本质上也是 MakeFunc 函数的调用,MakeFunc 函数的第二个参数类型是 fn func(args []Value) (results []Value),是一个通用的兼容设计,需要结合它的第一个参数来确定。
type SceneProcess struct {
ReFixNameTask func(ctx context.Context)
}
func (f SceneProcess) FixNameTask(ctx context.Context) {
fmt.Println("Do fix name scene")
}
func main() {
scene := &SceneProcess{}
ft := reflect.ValueOf(scene).MethodByName("FixNameTask").Type()
reflect.ValueOf(scene).Elem().FieldByName("ReFixNameTask").Set(
reflect.MakeFunc(ft, func(args []reflect.Value) (results []reflect.Value) {
fmt.Println("re-implement do fix name scene")
return nil
}))
scene.ReFixNameTask(context.TODO())
}
在使用 MakeFunc 创建函数的时候,有一个特别重要的细节:如何返回 error。go 习惯将最后一个返回值指定为 error 类型,而我们要如何构造这个 nil 的 error 对应的 reflect.Value 类型呢?我们对上述代码做微调,ReFixNameTask 函数新增返回值 error。执行下面代码,程序触发了 panic: reflect: function created by MakeFunc using closure returned zero Value
type SceneProcess struct {
ReFixNameTask func(ctx context.Context) error
}
func main() {
scene := &SceneProcess{}
ft := reflect.ValueOf(scene).Elem().FieldByName("ReFixNameTask")
ft.Set(
reflect.MakeFunc(ft.Type(), func(args []reflect.Value) (results []reflect.Value) {
fmt.Println("re-implement do fix name scene")
return []reflect.Value{reflect.ValueOf(nil)}
}))
scene.ReFixNameTask(context.TODO())
}
函数返回了一个没有类型的零值,程序在执行完 Println 之后触发了 panic。正确返回零值 error 可以是下面这些形式。对于 nil 和这两种写法的不同,在 Zero 方法的注释中也给出了解释,Zero 返回的是类型的零值,而 zero Value 表示压根不存在。
var nilError reflect.Value = reflect.Zero(reflect.ValueOf((*error)(nil)).Type().Elem())
// 或者
var nilError reflect.Value = reflect.Zero(reflect.TypeOf((*error)(nil)).Elem())
// 或者
// Zero returns a Value representing the zero value for the specified type.
// The result is different from the zero value of the Value struct,
// which represents no value at all.
这种在运行时动态实现函数的方式,在 RPC 框架中比较常见。结构体中的函数类型声明,出参/入参一般都有固定的格式,这样可以走统一的解析方法。入参一般都是 []interface 切片的形式,兼容多参数的情况,出参是固定的两个返回值(最后一个返回值是error类型)。
Elem
在反射中,Elem函数算是使用频率很高的方法了。Elem 用来返回元素的类型,如果反射的对象的一个指针,在调用 Elem 就会返回指针下实际数据的类型。
查找指定的Field
我们假设struct中包含有某个特殊Field,那么在接口层面该如何进行判断呢?比如,查看结构体中是否含有Data的Field.
reflect本身提供了多种判断形式。以FieldByName为例,Type和Value都实现了该方法,但返回值不相同。reflect要求调用的值本身需要是struct类型才可以。
h := v.FieldByName(HeaderHField) //HeaderHField为自定义常亮
if h.IsValid() {
}
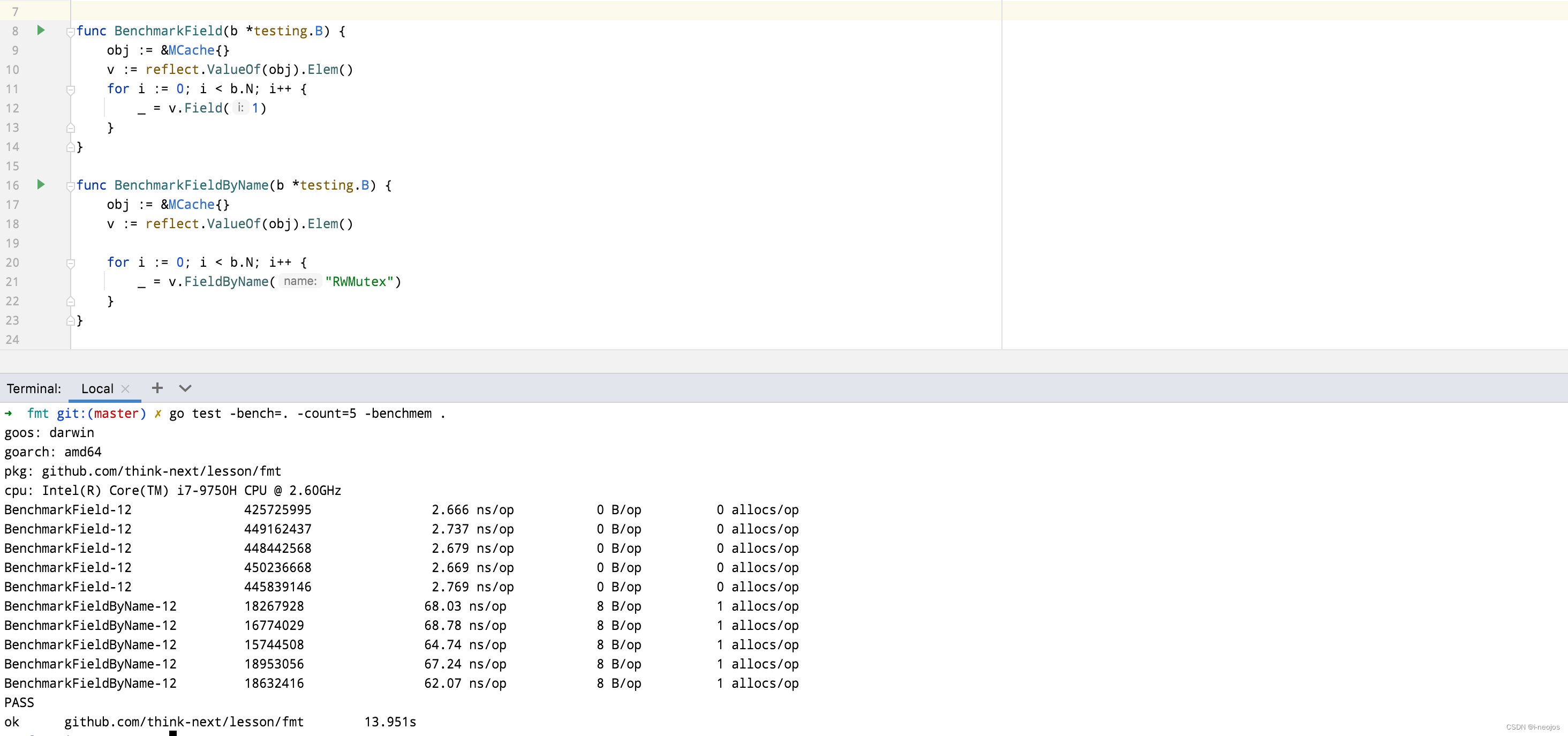
FieldByName 的性能
反射的性能经常被很多人恐惧,一听说使用到了反射,总觉得性能变差了,但不可否认,性能确实变差了,但具体变差了多少呢?假想有一个方法 SetName单次调用,没有使用反射前耗时 1ns,使用反射后耗时 8ns,不使用反射是使用反射性能的8倍,8倍,听起来很大的一个差距。但具体到我们的实际业务中,8ns 的影响究竟有多大呢?
很多框架都在使用反射,但也有很多高性能的包,之所以高性能,就是因为完全没有使用反射。我总觉得要正确地看待反射,不能一棒子把它打死,要学习如何更高效的使用反射,而不是不用反射。
FieldByName 其实就被认为是一个特别耗时的反射函数,我们获取结构体字段有两种方式,其中一种是通过 Field 方法来获取,这种模式经常见到。下面的例子中 field 就是通过这个函数获取的,另外一种方式就是 FieldByName,通过结构体字段的名称来获取。这个 MCache 结构体中有两个字段,还有一个是嵌套的匿名结构体。
type MCache struct {
cache *lru.Cache
sync.RWMutex
}
func main() {
obj := &MCache{}
v := reflect.ValueOf(obj).Elem()
number := v.NumField()
for i := 0; i < number; i++ {
field := v.Field(i)
}
}
具名的结构体字段获取比较常见,我们现在通过 FieldByName 来获取 sync.RWMutex 字段,并对它俩进行 benchmark 测试。在测试前,我们首先要验证通过这两种方式获取到的结果是相同的。下面的代码执行输出 equal ,表示获取到的结果是没有问题的,RWMutex 也确实是默认的字段名。
func main() {
obj := &MCache{}
obj.Lock()
defer obj.Unlock()
v := reflect.ValueOf(obj).Elem()
field := v.Field(1)
fieldByName := v.FieldByName("RWMutex")
if field == fieldByName {
fmt.Println("equal")
}
}
下面是性能测试的结果,Field 是 FieldByName 的性能的 34 倍,可能不同的机器会得出不同的结果,我用的是 go1.18 的版本。针对这种情况,我们会首先对结构体的 Field 做一个缓存,字段名称到 FieldIndex 的缓存映射,通过这个缓存层,将 FieldByName 的操作转换为 Field 的操作。
说到这里,其实很多场景都有这样的缓存层,比如,MySQL 中常见的一些关系表,我们通过关系表来过滤出想要的 id 列表,然后再去对应的表中获取 id 对应的数据。在 HBASE 的本地缓存中设计中,SlabCache 方案下的 LRUBlockCache 也是用来做这样的缓存层的。透过现象看本质,大思路都是想通的。
下面创建的就是结构体 MCache 的缓存,map 类型,key 为字段名,value 为 FidleIndex 。第一次程序启动的时候,就需要创建好这个缓存结构体,后续通过字段名直接获取 FieldIndex,然后通过 Field 方法取获取。
func main() {
obj := &MCache{}
cache := make(map[string]int)
typ := reflect.TypeOf(obj).Elem()
for i := 0; i < typ.NumField(); i++ {
cache[typ.Field(i).Name] = i
}
}















 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









