







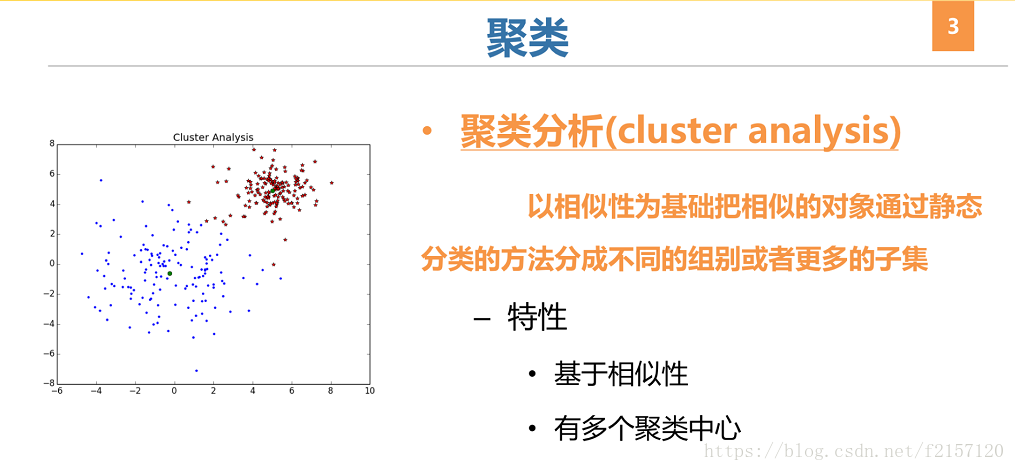
1 聚类分析
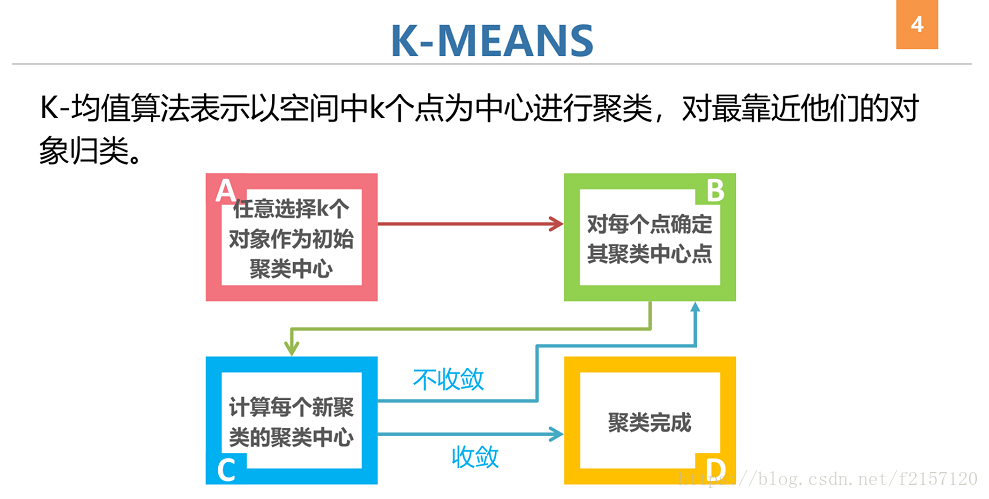
基于不同的距离,均方根/绝对值/n范数 等等
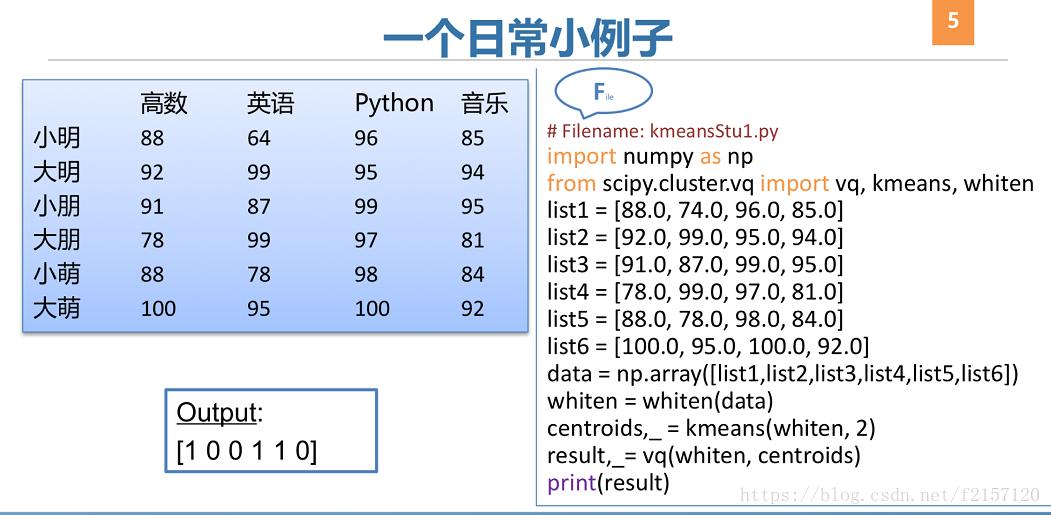
# Kmeans #1
import numpy as np
from scipy.cluster.vq import vq,kmeans,whiten
list1=[88.0,74.0,96.0,85.0]
list2=[92.0,99.0,95.0,94.0]
list3=[91.0,87.0,99.0,95.0]
list4=[78.0,99.0,97.0,81.0]
list5=[88.0,78.0,98.0,84.0]
list6=[100.0,95.0,100.0,92.0]
data=np.array([list1,list2,list3,list4,list5,list6])
whiten=whiten(data)
centroids,_=kmeans(whiten,2) #后面的下划线表示参数不要, kmeans 中的第2个参数,2,表示分为两类
result,_=vq(whiten,centroids) #后面的下划线表示参数不要
print(result)
# Kmeans
import numpy as np
from sklearn.cluster import KMeans
list1=[88.0,74.0,96.0,85.0]
list2=[92.0,99.0,95.0,94.0]
list3=[91.0,87.0,99.0,95.0]
list4=[78.0,99.0,97.0,81.0]
list5=[88.0,78.0,98.0,84.0]
list6=[100.0,95.0,100.0,92.0]
X=np.array([list1,list2,list3,list4,list5,list6])
kmeans=KMeans(n_clusters=2).fit(X)
pred=kmeans.predict(X)
print(pred)

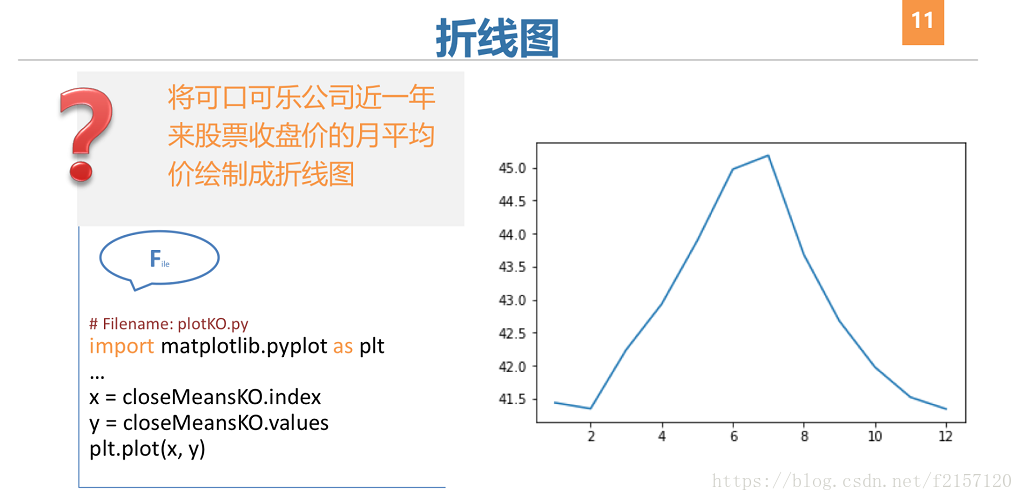
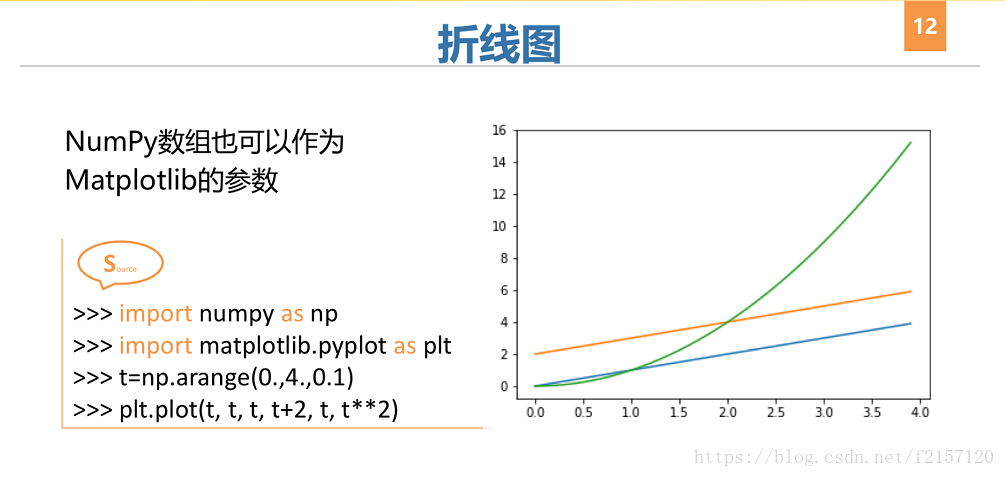
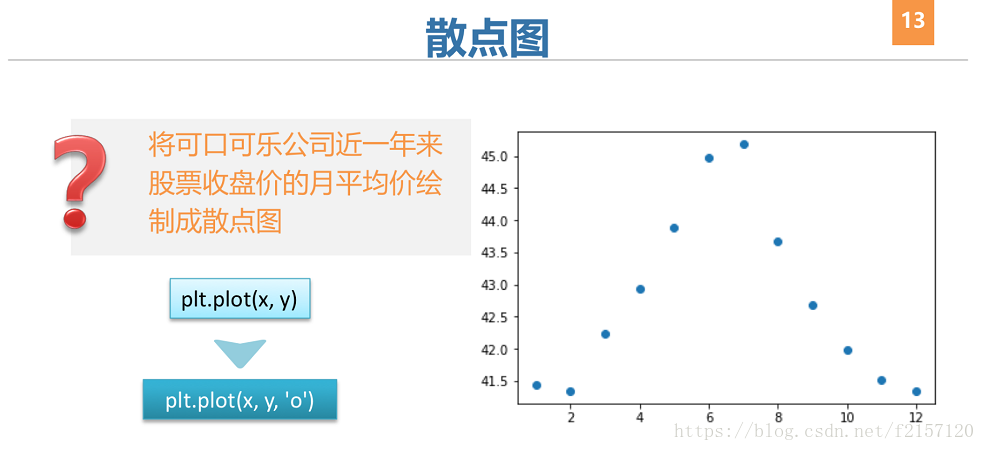
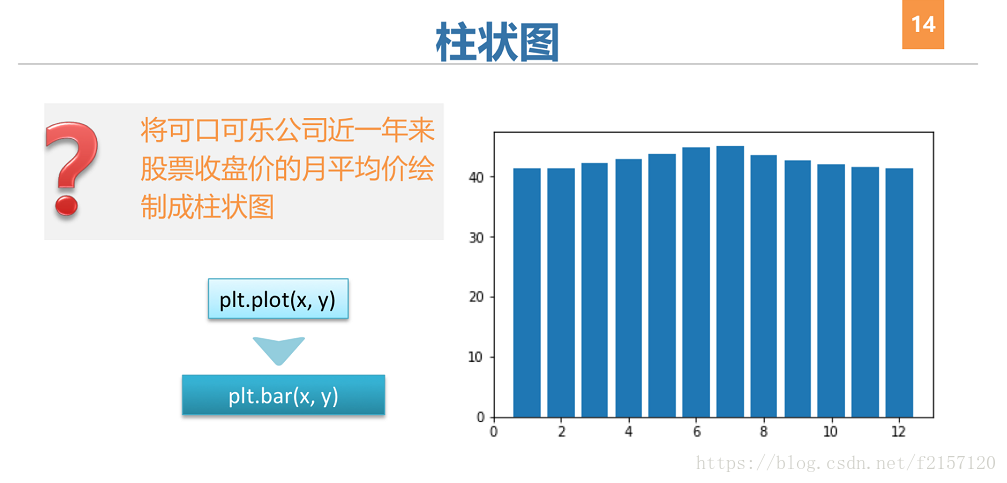
3 Matplotlib图像属性控制





































 6785
6785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









