







为什么引入非线性激励函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入。
为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
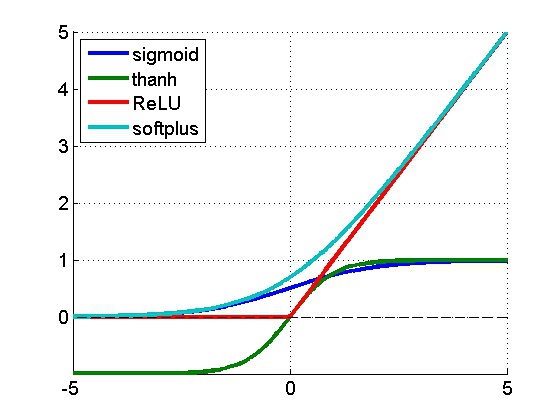
各种激活函数曲线:
caffe ReLU / Rectified-Linear and Leaky-ReLU 及参数设置
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}参考:
Begin Again https://www.zhihu.com/question/29021768/answer/43488153
Physcalの大魔導書 http://www.cnblogs.com/neopenx/p/4453161.html
denny402 http://www.cnblogs.com/denny402/p/5072507.html















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









