






点击上方“AI搞事情”关注我们
论文链接: http://openaccess.thecvf.com/content_CVPR_2019/papers/Wei_Inverse_Discriminative_Networks_for_Handwritten_Signature_Verification_CVPR_2019_paper.pdf
复现源码:https://github.com/jeason353/IDN

※ 前言
个人签名属于人们的生物识别特征之一,在财务、商业、司法文件得以广泛使用,签名的真实性鉴别(笔迹鉴定)成为了一个具有现实应用场景的任务。
本文针对离线手写签名问题,引入了Attention模块以及对图片进行黑白翻转搭建多路结构来训练网络,聚焦在笔划信息上从而提取出更加鲁棒的特征,以适应于签名认证任务。
签名图片数据是比较稀疏的,经过二值化处理以后大部分区域都是背景,如何从稀疏的笔划像素部分提取有效信息是签名认证任务的关键点。
1. 签字数据集
论文列出的图片数据集
CEDAR
MCYT-75
BHSig
GPDS数据类签名数据集
MCYT-100:该数据库是由马德里自治大学的BiDA实验室采集的签名数据库,通过电磁感应式手写板WACOM手写板采集到采样点的坐标、时刻和笔尖压力值,以及笔的水平偏角和垂直偏角等信息,该数据库包括100个签名,每个签名有25个真实样本和25个伪造样本,是目前数据量最大的常用数据库之一。
SVC2004:2004年由香港科技大学组织的第一届世界签名认证竞赛提供的比赛数据库,包含了中文和英文签名。任务1 仅提供签名的x、y 坐标轨迹特征,任务2提供了签名的轨迹、压力、签名时刻、提笔落笔标记以及笔的水平偏角和垂直偏角。该数据的数据量较少,每个任务仅有40个签名用户,每个包括20个真实签名和20个伪造签名。
SUSIG:数据库是由土耳其萨班哲大学生物特征识别研究组采集的签名数据库,数据包含智能笔采集的签名时笔的轨迹和压力感应屏记录的笔尖压力信息。该数据库包括了94个签名,每个签名有20个真实样本和10 个伪造样本,前十个真实签名和后十个真实签名的签名时间间隔为一周。
由于缺乏中文签名数据集,论文采集了包含749个用户约29,000张签字图片的中文签名数据集,每个姓名有20次不同时间点的真实签名(genuine signature)和20次冒写签名(forged signature),冒写包含10次志愿者简单冒写和10次书法家专业仿写。所有签名扫描成图片后,裁剪并缩放到同样大小,经OTSU算法和归一化处理,将签名统一为背景像素为255(白色),笔画为原始像素的图片数据,以此构建中文签名数据集,并将其作为对提出算法的评测数据集之一。

2. 相关方法
手工特征
图像几何特征:签字高度,宽度,面积
局部特征:LBP,SIFTNN特征
CNN网络:基于分类,融合两通道
孪生网络
GAN网络
※ 本文方法
1. 逆鉴别网络
解决问题:如何让模型在大量背景的稀疏签名图片中更关注签名笔画像素信息?
基本思想:网络识别源签字图片和逆签字图片应该得到同样的结果。
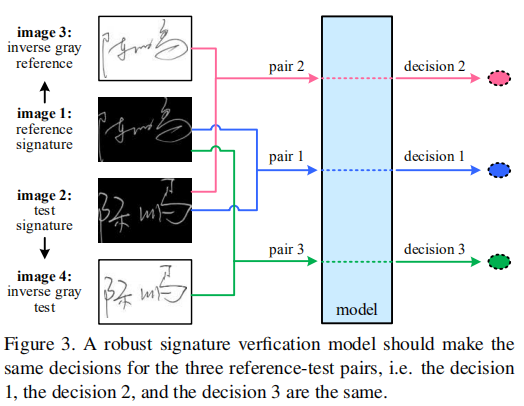
也就是说,网络只关注笔画信息,只要笔画像素一样,背景不同不会影响识别结果。按照上图来说,测试图片image2与参考图片image1的网络输出结果应该和image2与image1的逆图像image3相同,同理,和image1与与image4的结果也应该相同。
基于上述思想,本文提出的逆判别网络(inverse discriminative network ,IDN)网络结构如下:
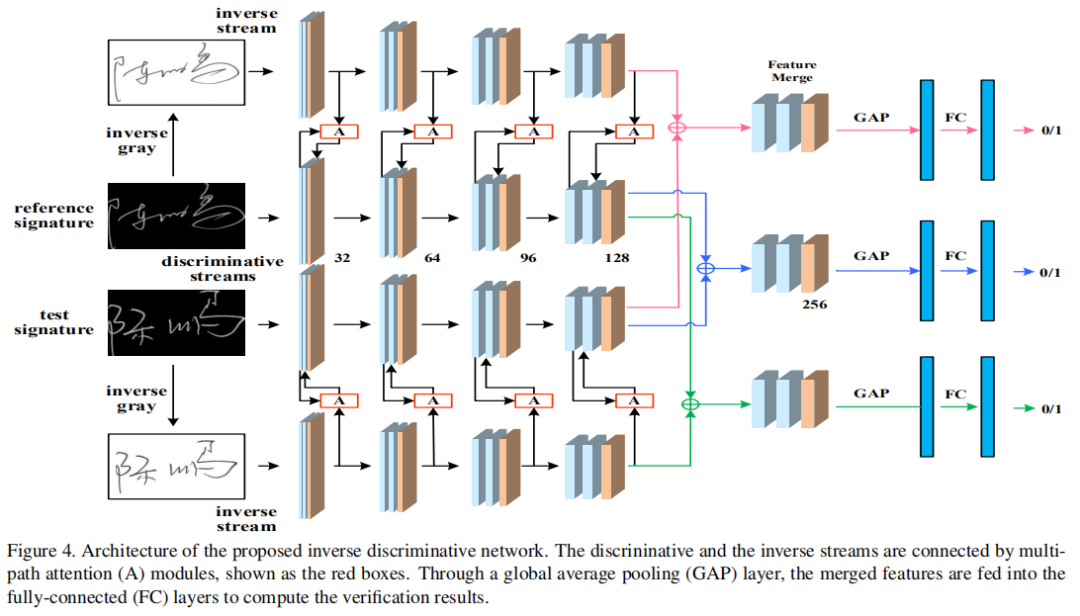
该网络可以看作是孪生网络的加强版(四胞胎网络????),包含四路共享权重的级联CNN模块,可以分为两路判别流,即以测试图片和参考图片作为输入的两路网络;和两路逆流(inverse streams:就是这么翻译的吧),以逆图片作为输入的两路网络。共享网络中,每个模块两个卷积层,卷积核3x3,步长为1,ReLu激活函数,一个2x2大小的池化层进行降维,每个模块的卷积核个数分别为: 32、64、96、128。
2. 多路Attention机制
在判别流和逆流之间有8路Attention连接对不同尺度的特征图进行处理,指导网络学习签字笔画的判别性信息,抑制干扰信息,增强签名验证的重要特征。如结构图红框所示,每个attention模块包含前向过程和反向过程。前向过程接收判别流每个卷积模块的第一层特征,反向过程主要是逆流输出特征向判别流第二层卷积层传递注意力信息。
attention模块内部结构示意图,包含了空间注意力机制和通道注意力机制。在两路网络之间建立attention机,将网络对原笔迹图片和逆笔迹图片提取的特征联系了起来。
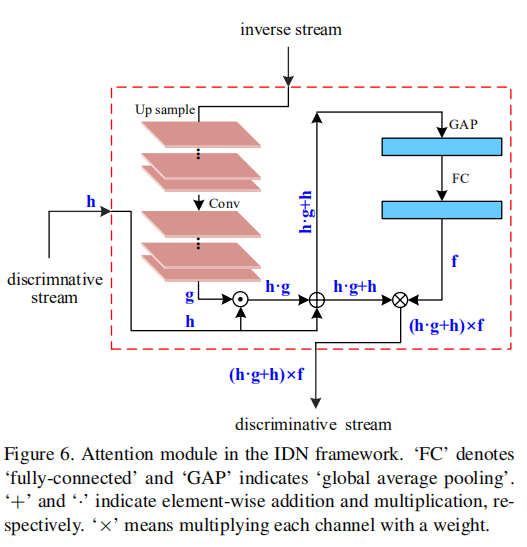
如上图所示,逆流网络各模块输出特征经过上采样后,特征图大小与判别流第一层输出特征一致,经过Sigmoid激活函数的卷积操作学习到特征调节因子g,与判别流卷积模块第一层输出h逐像素相乘后再逐像素加上第一层输出h,得到空间调整后的特征图:h · g + h;调节后的特征图通过全局平均池化和Sigmoid激活的全连接层,得到通道调节因子f,将f与调节后的特征图逐通道相乘后输出attention机制处理后的特征:(h · g + h) × f。
对相加后的特征,经过两个卷积层和一个池化层(256卷积核),不同输出流的特征被融合为三个256通道的特征图,融合特征经过全局平均池化(global average pooling ,GAP)处理输入到全连接层进行验证计算。
3. 损失函数
基于交叉熵,提出逆监督损失函数,实际就对真实标签为同一个值的三对输出做交叉熵损失的加权求和。
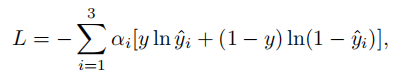
y表示真实二值标签,1表示真实(genuine)签名,0表示冒写(forged)签名,yi(i = 1, 2, 3)表示三对图片的预测结果。αi表示调整损失函数的权重。
※ 实验
1. 评价指标
FAR(错误识别率):
FRR(错误拒绝率):
EER(等误率):
AUC(ROC曲线面积)
ACC(准确度):
2. 数据集
● CSD:中文签名 749个人 20真实,20冒写
训练集:357 验证集:187 测试集:
● CEDAR:英文签名 55个人 24真实, 24 冒写
http://www.cedar.buffalo.edu/NIJ/data/signatures.rar
训练集:50 测试集:5

● BHSig260:包含两个子集
https://drive.google.com/file/d/0B29vNACcjvzVc1RfVkg5dUh2b1E
BHSig-B:孟加拉语签名 100个人,24真实,30冒写
训练集:50 测试集:50

BHSig-H:印地语签名 160个人,24真实,30冒写
训练集:100 测试集:60

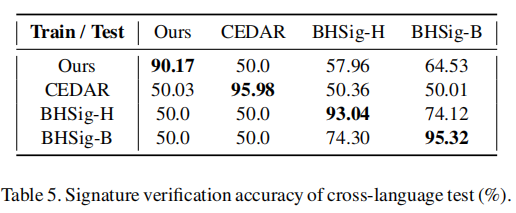
3. 跨语言测试
在一种语言的签名数据集上训练模型,在另一种语言签名数据进行测试,鉴别性能会剧烈下降,这可能是由于语言文字的不同会影响签名者的书写习惯和风格,所以导致了鉴别器在跨语种的任务上泛化性能较差。
※flask搭建一个签字程序
在做算法调研时,发现一个绘制平滑签名的JavaScript库,基于HTML5 canvas实现,它适用于所有现代桌面和移动浏览器,且不依赖于任何外部库的签字程序:signature_pad

Flask是python的轻量级Web应用框架,最大的特征是轻便,我们可以使用Python语言快速实现一个网站或Web服务。python环境下安装flask:
pip install flask
通过flask加载签字html页面,可参考signature_pad demo实现或者博客:https://blog.csdn.net/weixin_38362455/article/details/88171200
python代码
import json
import base64
from flask import Flask, render_template, request
app = Flask(__name__)
@app.route('/')
def hello_world():
return render_template('index.html')
@app.route('/image', methods=['POST'])
def get_image_data():
img_data = request.values.get('imgStr', 0)
sign_data = request.values.get('sign_data', 0)
# 保存图片
with open('test.png', 'wb') as f:
f.write(base64.b64decode(img_data))
return img_data
if __name__ == '__main__':
app.config["DEBUG"] = True
# 设置debug=True是为了让代码修改实时生效,而不用每次重启加载
app.run(host='0.0.0.0', port=500)

基于这样的签字服务和算法,后面的就可以实现很多的应用,如:手写字体识别、笔迹识别、笔迹比对等。



长按二维码关注我们
有趣的灵魂在等你



留言就摁吧


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









