









通过标准输入(stdin)和标准输出(stdout)来传递Map和Reduce过程之间的数据。
1、数据文件
zhangsan 15
lisi 15
zhangsan 16
lisi 16
wangwu 14
zhangsan 15
lisi 162 map程序——mapper.py
#!/usr/bin/env python2.6
import sys
for line in sys.stdin:
line=line.strip()
words=line.split()
for word in words:
print '%s\t%s' % (word,1)
确保该文件是可执行的:
chmod +x /TestData/mapper.py另外第一行记得添加:#!/usr/bin/env python2.6
3、reduce程序——reducer.py
#!/usr/bin/env python2.6
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)确保该文件是可执行的:
chmod +x /TestData/reducer.py5、单机测试
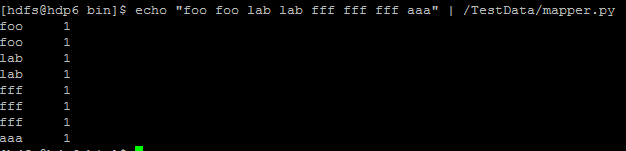
注:如果报错/usr/bin/env: python2.6: No such file or directory可能是从windows复制到linux上出问题了,在linux上重新写一份
6、hadoop上运行
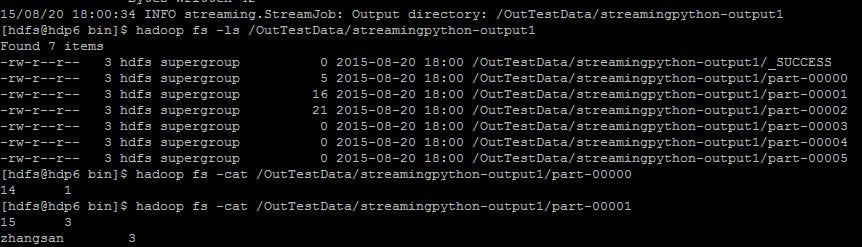
hadoop jar /opt/cloudera/parcels/CDH-5.4.0-1.cdh5.4.0.p0.27/jars/hadoop-streaming-2.6.0-mr1-cdh5.4.0.jar -file /TestData/mapper.py -mapper /TestData/mapper.py -file /TestData/reducer.py -reducer /TestData/reducer.py -input /OutTestData/streamingtestdata.txt -output /OutTestData/streamingpython-output运行如下:


运行结果:















 138
138

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









