







hive是一个基于hadoop的搜索与数据分析引擎,它提供了一种类sql的方式供用户使用.hive能够将本地文件映射到一个hive表中 ,同样hive也能直接将hdfs文件映射到hive中使用。hive自动将sql翻译成mapreduce
-
hive的安装
- hadoop的安装
- mysql的安装
- 下载hive
wget http://mirror.bit.edu.cn/apache/hive/hive-2.3.0/apache-hive-2.3.0-bin.tar.gz;tar -zxvf apache-hive-2.3.0-bin.tar.gzmv apache-hive-2.3.0-bin /usr/local/hive接下来就是配置环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_91
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/hadoop
export HIVE_HOME=/usr/local/hive
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin
tips:如果java hadoop安装目录请按自行情况更改
接下来就是配置hive的配置文件
source /etc/profilecd $HIVE_CONF_DIRcp hive-default.xml.template hive-site.xml ; cp hive-env.sh.template hive-env.sh ; 修改hive-env.sh如下:
修改HADOOP_HOME HIVE_CONF_DIR HIVE_AUX_JARS_PATH
# Set HADOOP_HOME to point to a specific hadoop install directory
HADOOP_HOME=/usr/local/hadoop
# Hive Configuration Directory can be controlled by:
export HIVE_CONF_DIR=/usr/local/hive/conf
# Folder containing extra libraries required for hive compilation/execution can be controlled by:
export HIVE_AUX_JARS_PATH=/usr/local/hive/lib
修改hive-site.xml
- 修改javax.jdo.option.ConnectionURL :master:3306为mysql数据库的host port
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive</value>
<description>
JDBC connect string for a JDBC metastore.
To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL.
For example, jdbc:postgresql://myhost/db?ssl=true for postgres database.
</description>
</property>- 修改javax.jdo.option.ConnectionDriverName
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>- 修改mysql数据库用户名,密码
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>- 修改hive.metastore.warehouse.dir ======> hive内部表的数据存储位置,可自行修改
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<description>location of default database for the warehouse</description>
</property>强烈建议将${system:java.io.tmpdir}等变量值修改为hive的安装路径
本人这台机器修改前后的文件差异 如下:
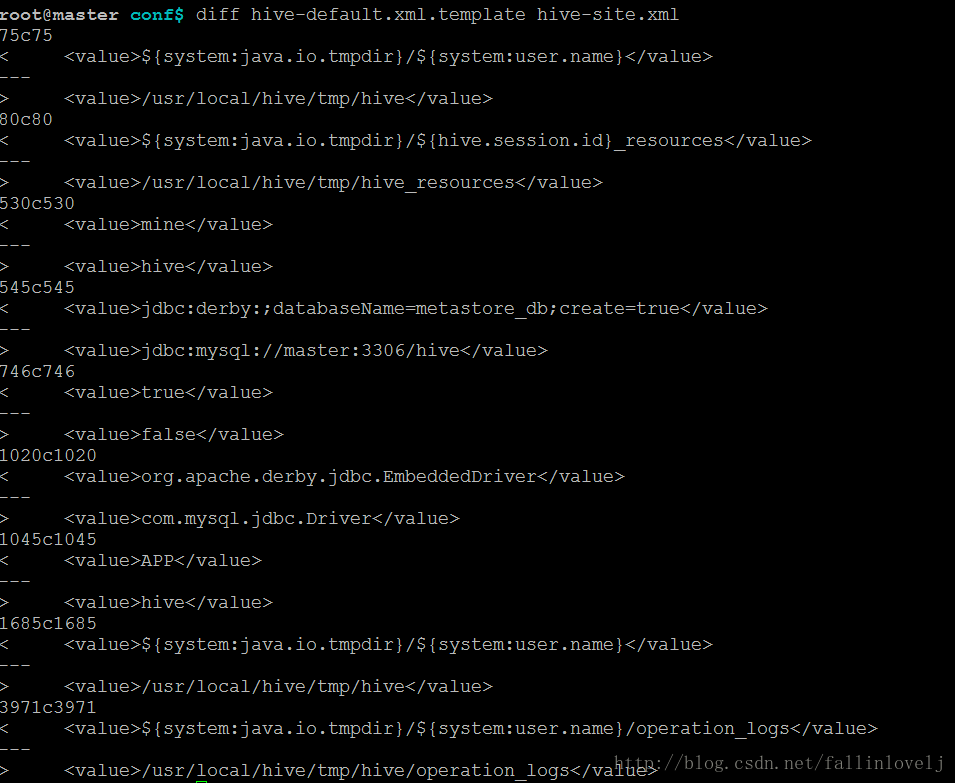
好了到这里,hive基本安装完成了.
运行/usr/local/hive/bin/schematool -initSchema -dbType mysql 初始化hive的metea数据库。在本文中就是hive ,参见上面的javax.jdo.option.ConnectionURL
mysql连接hive数据库,运行show tables :可以看到metea的数据库
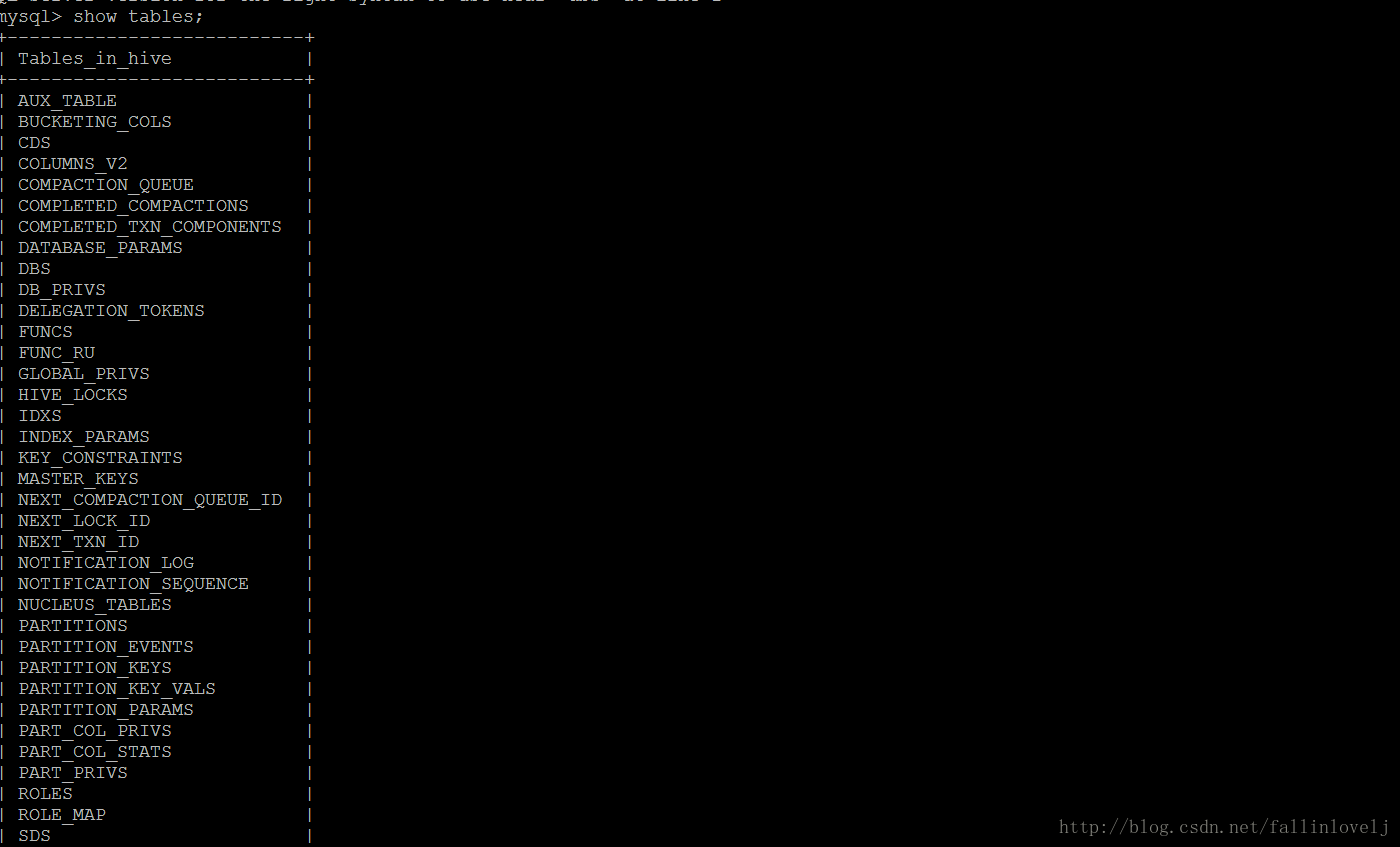
- ***metastore元数据库介绍
| 表名 | 用途 |
|---|---|
| BUCKETING_COLS | 存储bucket字段信息,通过SD_ID与其他表关联 |
| CDS | 一个字段CD_ID,与SDS表关联 |
| COLUMNS_V2 | 存储字段信息,通过CD_ID与其他表关联 |
| DATABASE_PARAMS | 空 |
| DBS | 存储hive的database信息 |
| DELETEME1410257703262 | 空 |
| FUNCS | 空 |
| FUNC_RU | 空 |
| GLOBAL_PRIVS | 全局变量,与表无关 |
| IDXS | 空 |
| INDEX_PARAMS | 空 |
| PARTITIONS | 分区记录,SD_ID, TBL_ID关联 |
| PARTITION_KEYS | 存储分区字段,TBL_ID关联 |
| PARTITION_KEY_VALS | 分区的值,通过PART_ID关联。与PARTITION_KEYS共用同一个字段INTEGER_IDX来标示不同的分区字段。 |
| PARTITION_PARAMS | 存储某分区相关信息,包括文件数,文件大小,记录条数等。通过PART_ID关联 |
| PART_COL_PRIVS | 空 |
| PART_COL_STATS | 空 |
| PART_PRIVS | 空 |
| ROLES | 角色表,和GLOBAL_PRIVS配合,与表无关 |
| SDS | 存储输入输出format等信息,包括表的format和分区的format。关联字段CD_ID,SERDE_ID |
| SD_PARAMS | 空 |
| SEQUENCE_TABLE | 存储sqeuence相关信息,与表无关 |
| SERDES | 存储序列化反序列化使用的类 |
| SERDE_PARAMS | 序列化反序列化相关信息,通过SERDE_ID关联 |
| SKEWED_COL_NAMES | 空 |
| SKEWED_COL_VALUE_LOC_MAP | 空 |
| SKEWED_STRING_LIST | 空 |
| SKEWED_STRING_LIST_VALUES | 空 |
| SKEWED_VALUES | 空 |
| SORT_COLS | 排序字段,通过SD_ID关联 |
| TABLE_PARAMS | 表相关信息,是否外部表,通过TBL_ID关联 |
| TAB_COL_STATS | 空 |
| TBLS | 存储表信息,关联字段DB_ID,SD_ID, |
| TBL_COL_PRIVS | 空 |
| TBL_PRIVS | 表赋权限相关信息,通过TBL_ID关联 |
| VERSION | 版本 |
| VERSION_copy | 版本,通过VER_ID关联 |
对于我们来说 ,一般先只关注SDS TBLS TABLE_PARAMS就OK了。具体下面再介绍
到这里,hive就全部安装配置完成.命令行运行hive

hive的使用
本文以linux 上一个文件 /etc/passwd来讲述
将本地文件上传到hive中去
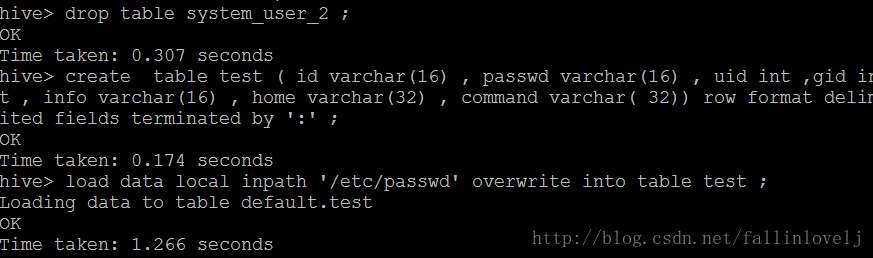
create table test ( id varchar(16) , passwd varchar(16) , uid int ,gid int , info varchar(16) , home varchar(32) , command varchar( 32)) row format delimited fields terminated by ‘:’ ;
之后我们可以用sql来操作test这个表了.
接下类我们看看hive的云数据库 meteastore都发生了什么,mysql进入hive数据库
select a.TBL_NAME as tablename , b.LOCATION as hdfs_uri ,a.CREATE_TIME as CREATE_TIME from TBLS a left join SDS b on a.SD_ID=b.SD_ID ;我们看到

也就说说我们的数据最后是直接存储到hdfs://master:9000/user/hive/warehouse/test,是不是呢?我们在hdfs中查看下
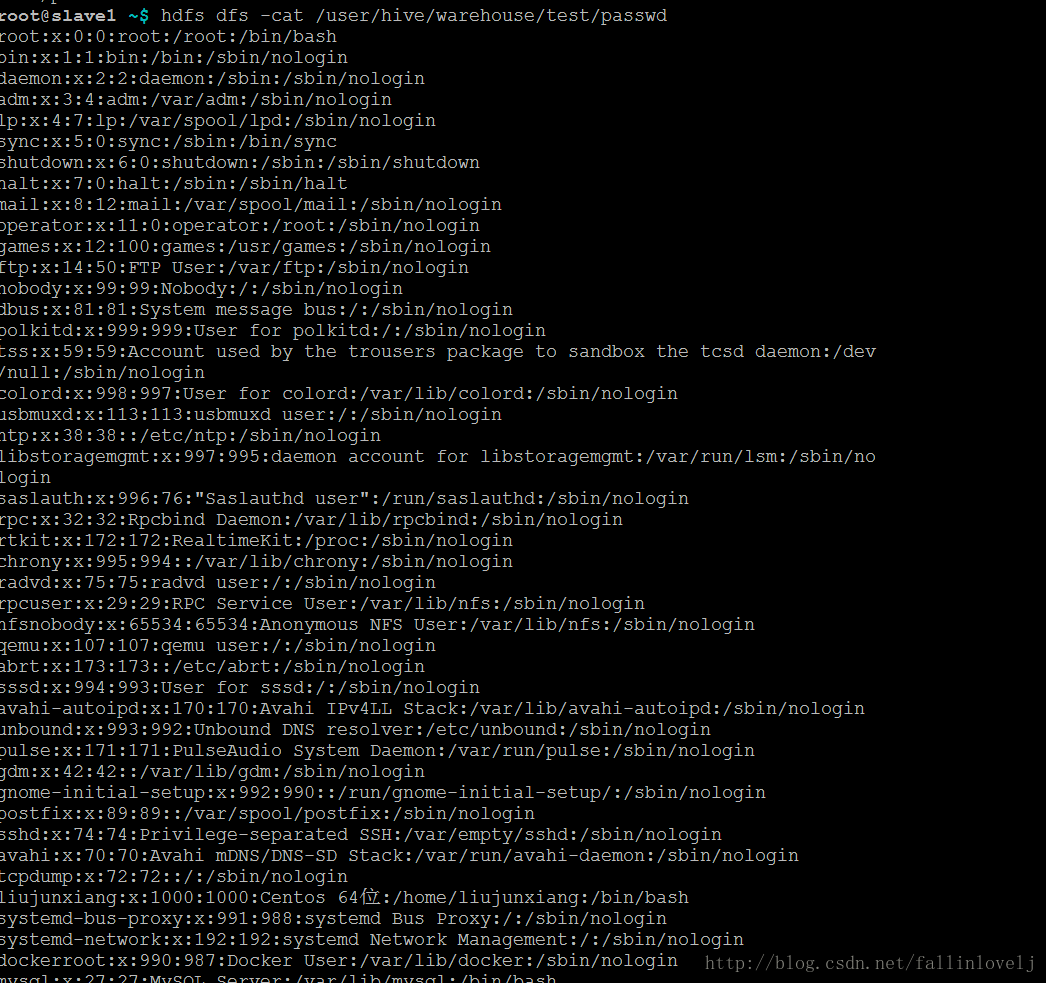
可以看到数据了.HEIHEI!!
- 从hdfs直接映射到hive中
很多时候,我们需要的不是从本地把数据文件导进入 我们需要的是把存在现有平台服务器上的HDFS文件直接映射到hive中,假定我们已经有了一个hdfs文件hdfs://master:9000//test/passwd
(也可以通过hdfs dfs -put /etc/passwd /test来制作这个hdfs文件 )
create table test1 ( id varchar(16) , passwd varchar(16) , uid int ,gid int , info varchar(16) , home varchar(32) , command varchar( 32)) row format delimited fields terminated by ':' location '/test';
按照前面的方法,我们从元数据库中查看

我们可以看到多了一条记录
test1 | hdfs://master:9000/test | 1503647126这样我们就把外部的hdfs中数据映射到hive中去了
hive中外部表与内部表
再说一个hive中十分重要的概念,外部表。默认情况下我们建的表是内部表。
那么什么是内部表呢?请看下图

’
’

看到了么 当test或者test1表删除后,它对应的数据也删除了。
在看换成是外部表呢?

可以看到删除test2后 /test1/passwd依然存在.
也是就说我们可以用外部表的方式来实现一份hdfs文件对多个hive表共享。
修改hive的location
两种方式:
- hive方式通过修改表DDL:
alter table tablename set location 'new location'- mysql方式 直接修改hive 的meteastore 元数据库
update `DBS` set `DB_LOCATION_URI` = replace(DB_LOCATION_URI,"oldpath","newpath")
update SDS set location =replace(location,'oldpath,'newpath')













 1363
1363











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









