






今天重新学习了Hadoop中MapReduce计算框架的相关内容,又有了一些新的体会,因此想将学习的一些心得记录下来。
首先,我们通过官方图解来了解一下MapReduce的整体流程:
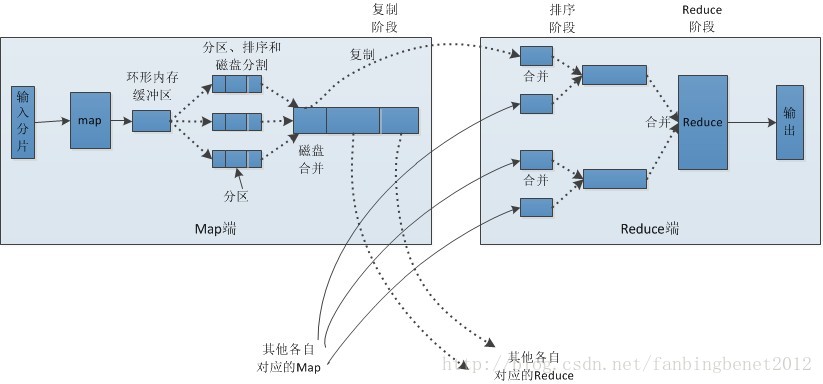
下面我们来了解一下MapReduce计算框架运行的几个阶段,总体来说可以分为四个基本阶段:
第一、原始数据的输入和切分(split)
在这个阶段我们需要明白数据是如何进行切分的,及其分片规则是什么,在MapReduce的执行过程当中,默认的数据分片大小为100M,但是这个大小可能会随着hdfs中block大小的设置而发生变化,具体的切分规则如下:
max.split(100M)
min.split(10M)
block(64M)==>大小可以自定义
max(min.split,min(max.split,block))
根据上述规则进行计算的话,上例上的分片大小为64M。
第二、是map阶段
在map阶段每一个split分片都会对应一个maptask任务,并且以key,value键值对的形式对数据进行处理,而且每一个map处理的数据首先会缓存到内存的缓冲区内(默认大小100M), 当内存中的数据达到整空间80%的时候会将数据溢写到磁盘上进行临时存储。
第三、是shuffle阶段
这是整个MapReduce过程中最复杂,也是最难理解的一个阶段,这个过程当中需要的需要对数据进行分区(partition)、排序(sort)和溢写(spill to disk)。
partition:就是对map输出的数据进行分区,为后续reduce做正准备,默认的分区算法是:通过数据上键的hash值与reduce数量进行模运算来为每一个数据进行分区,(但是partition规则可以根据具体的应用进行自定义)
sort:排序默认是按照对象所对应的ASCII码进行排序(也就是字典排序)。也可以根据具体的应用来进行自定义
最后是reduce阶段,在进行reduce计算之前,需要先将数据从磁盘上复制过来,并对每一个复制过来的数据进行合并。
下面我们来看一下,在进行MapReduce计算的时候如何解决数据倾斜的问题,在解决这个问题之前我们需要先知道数据倾斜是发生在计算过程的中的哪个阶段。
根据MapReduce的执行流程我们可以发现,在map端是不会产生数据倾斜的,因为它会根据分片规则将数据进行均匀的切分成一个个固定大小的数据片段,而且每一个数据片段都会有一个maptask去处理,因此,数据倾斜只会在reduce端产生,因为map程序会将数据处理成键值对的形式,这样就有可能出现有的键相同的数据多,有的键相同的数据少。因此在进行partition分区的时候会将键相同的数据分配到同一个reduce当中去,这样就会导致有的reduce要处理数据会很多,有的就会很少,从而导致数据倾斜问题的产生。所以我们需要根据实际数据的特点自定义partition分区的规则,这样就能很好的解决数据倾斜的问题。
MapReduce的分片规则及其数据倾斜的解决思路
最新推荐文章于 2023-04-02 10:19:55 发布















 2021
2021











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









