









Flink DataStream API 编程指南目录
1. 概览
-
DataStream基本转换
-
迭代:package com.xiaofan import org.apache.flink.streaming.api.scala._ /** * @author xiaofan */ object IterateDemo { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val someIntegers: DataStream[Long] = env.generateSequence(0, 10) // 返回11个结果 val iteratedStream: DataStream[Long] = someIntegers.iterate( iteration => { // 相当于循环体 val minusOne = iteration.map(v => v - 2) // 相当于if val stillGreaterThanZero = minusOne.filter(_ > 0) // 相当于else val lessThanZero = minusOne.filter(_ <= 0) // 返回的结果(固定写法) (stillGreaterThanZero, lessThanZero) } ) iteratedStream.print env.execute("DataStream API") } }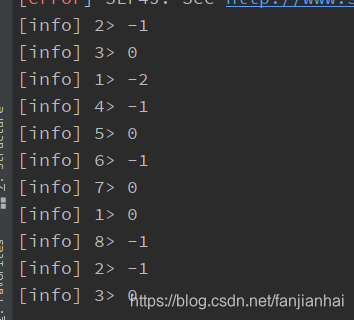
-
迭代器数据接收器-
Flink还提供了一个接收器来收集数据流结果,以便进行测试和调试`
package com.xiaofan import org.apache.flink.streaming.api.datastream.DataStreamUtils import org.apache.flink.streaming.api.scala._ /** * @author xiaofan */ object DataSinkTest{ def main(args: Array[String]): Unit = { import scala.collection.JavaConverters.asScalaIteratorConverter val env = StreamExecutionEnvironment.getExecutionEnvironment val value: DataStream[(String, Int)] = env.fromElements(("a", 1), ("b", 2), ("c", 3)) val result: Iterator[(String, Int)] = DataStreamUtils.collect(value.javaStream).asScala result.foreach(print) } }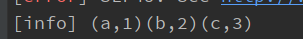
-
2. Event Time and Watermarks
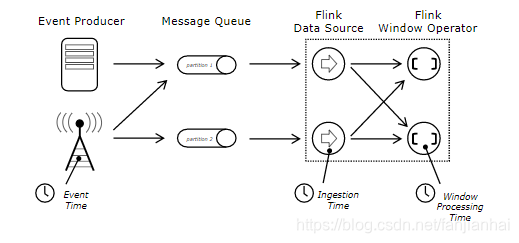
2.1. EventTime时间模型
2.2. 水印测试
-
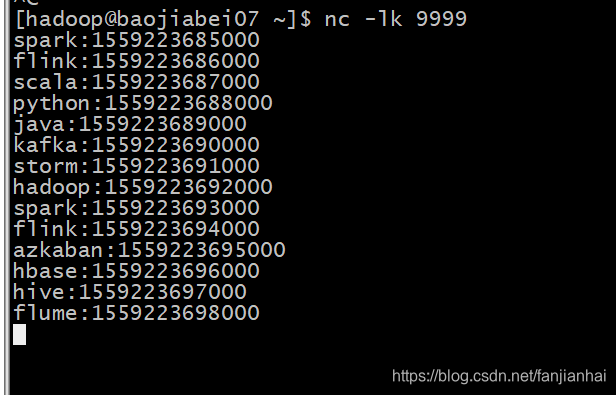
测试数据spark:1559223685000 flink:1559223686000 scala:1559223687000 python:1559223688000 java:1559223689000 kafka:1559223690000 storm:1559223691000 hadoop:1559223692000 spark:1559223693000 flink:1559223694000 azkaban:1559223695000 hbase:1559223696000 hive:1559223697000 flume:1559223698000 -
源代码package com.xiaofan import org.apache.commons.lang3.time.FastDateFormat import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector import scala.collection.mutable.ArrayBuffer /** * 水印测试 * 水印的目的: 处理乱序的数据问题 需要结合window来处理 * * window触发的条件: * 1.window中必须要有数据 * 2.eventTime = window结束时间 + waterMark (存在一条数据的事件时间大于等于 window结束时间 + waterMark) * * @author xiaofan */ object WaterMarkTest01 { // 线程安全的时间格式化对象 val sdf: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss:SSS") val hostName = "192.168.1.27" val port = 9999 def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment // 将EventTime设置为流数据时间类型 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val streams: DataStream[String] = env.socketTextStream(WaterMarkTest01.hostName, WaterMarkTest01.port) // 输入数据格式: name:时间戳 // spark:1559223685000 val data: DataStream[(String, Long)] = streams.map(data => { try { val items: Array[String] = data.split(":") (items(0), items(1).toLong) } catch { case _: Exception => println("Invalid Input:" + data) ("0", 0L) } }).filter(data => { !data._1.equals("0") && data._2 != 0L }) // 为数据流中的元素分配时间戳, 并定期创建watermark以监控事件时间的进度 val waterStream: DataStream[(String, Long)] = data.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] { // 事件时间 var currentMaxTimestamp = 0L var maxOutOfOrderDelay = 3000L var lastEmittedWatermark: Long = Long.MinValue override def getCurrentWatermark: Watermark = { // 允许延迟3秒 val potentialWatermark = currentMaxTimestamp - maxOutOfOrderDelay // 保证水印能依次递增 if (potentialWatermark >= lastEmittedWatermark) { lastEmittedWatermark = potentialWatermark } new Watermark(lastEmittedWatermark) } override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = { val time = element._2 if (time > currentMaxTimestamp) { currentMaxTimestamp = time } val outData: String = String.format("key: %s EventTime: %s waterMark: %s", element._1, sdf.format(time), sdf.format(getCurrentWatermark.getTimestamp)) println(outData) time } }) val result: DataStream[String] = waterStream .keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(5L))) .apply(new WindowFunction[(String, Long), String, Tuple, TimeWindow] { override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = { val timeArr = ArrayBuffer[String]() val iterator = input.iterator while (iterator.hasNext) { val tup2 = iterator.next() timeArr.append(sdf.format(tup2._2)) } val outData: String = String.format("key: %s data: %s startTime: %s endTime: %s", key.toString, timeArr.mkString("---"), sdf.format(window.getStart), sdf.format(window.getEnd)) out.collect(outData) } }) result.print("window compute result: ") env.execute(this.getClass.getName) } } -
数据有序到达的运行效果
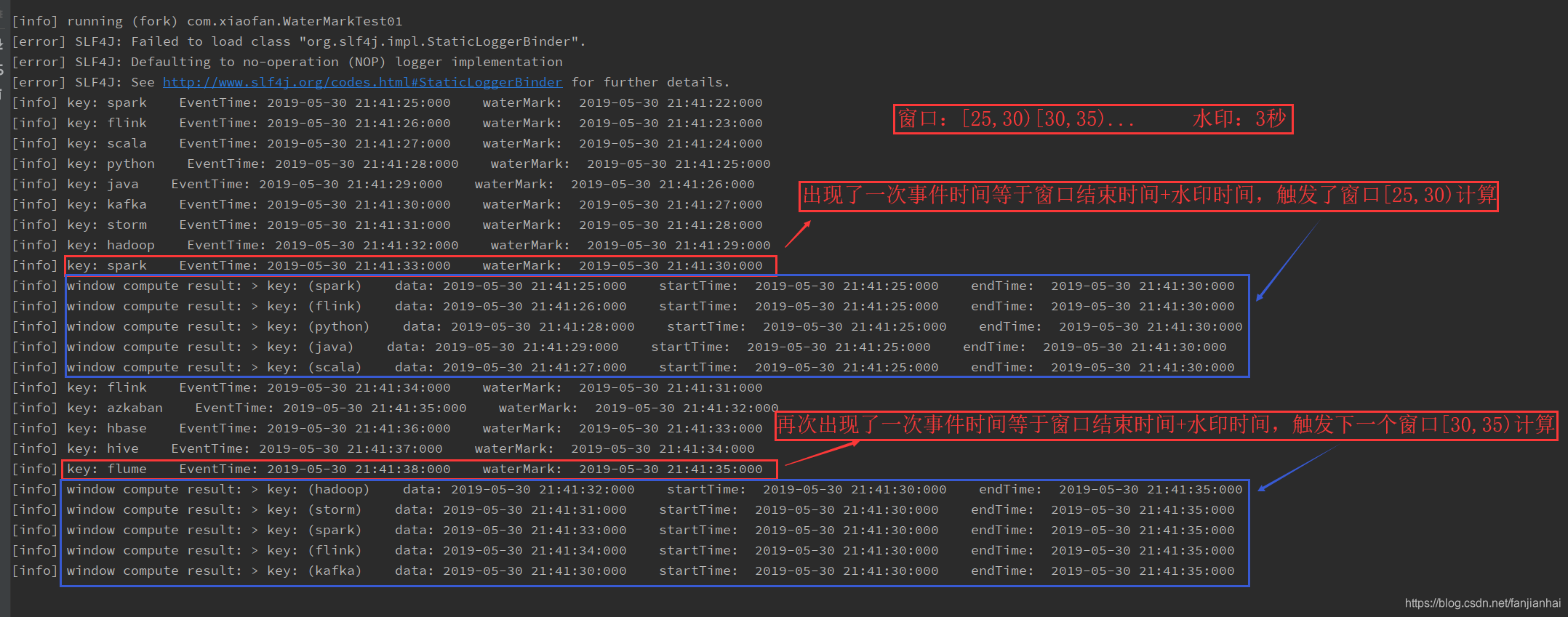
-
·模拟数据迟到的运行效果·
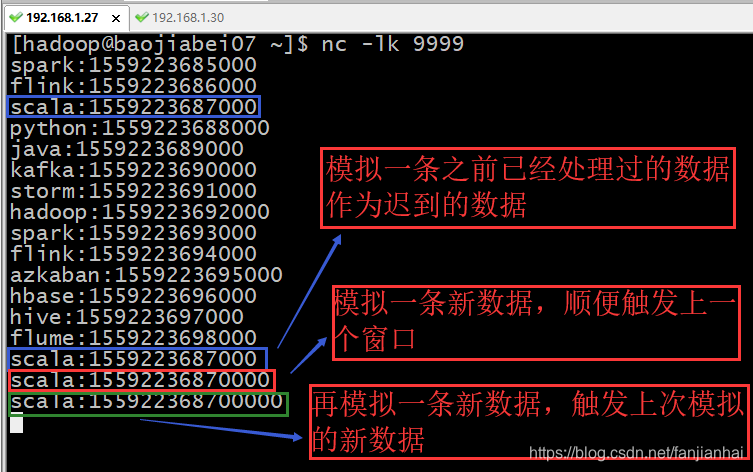
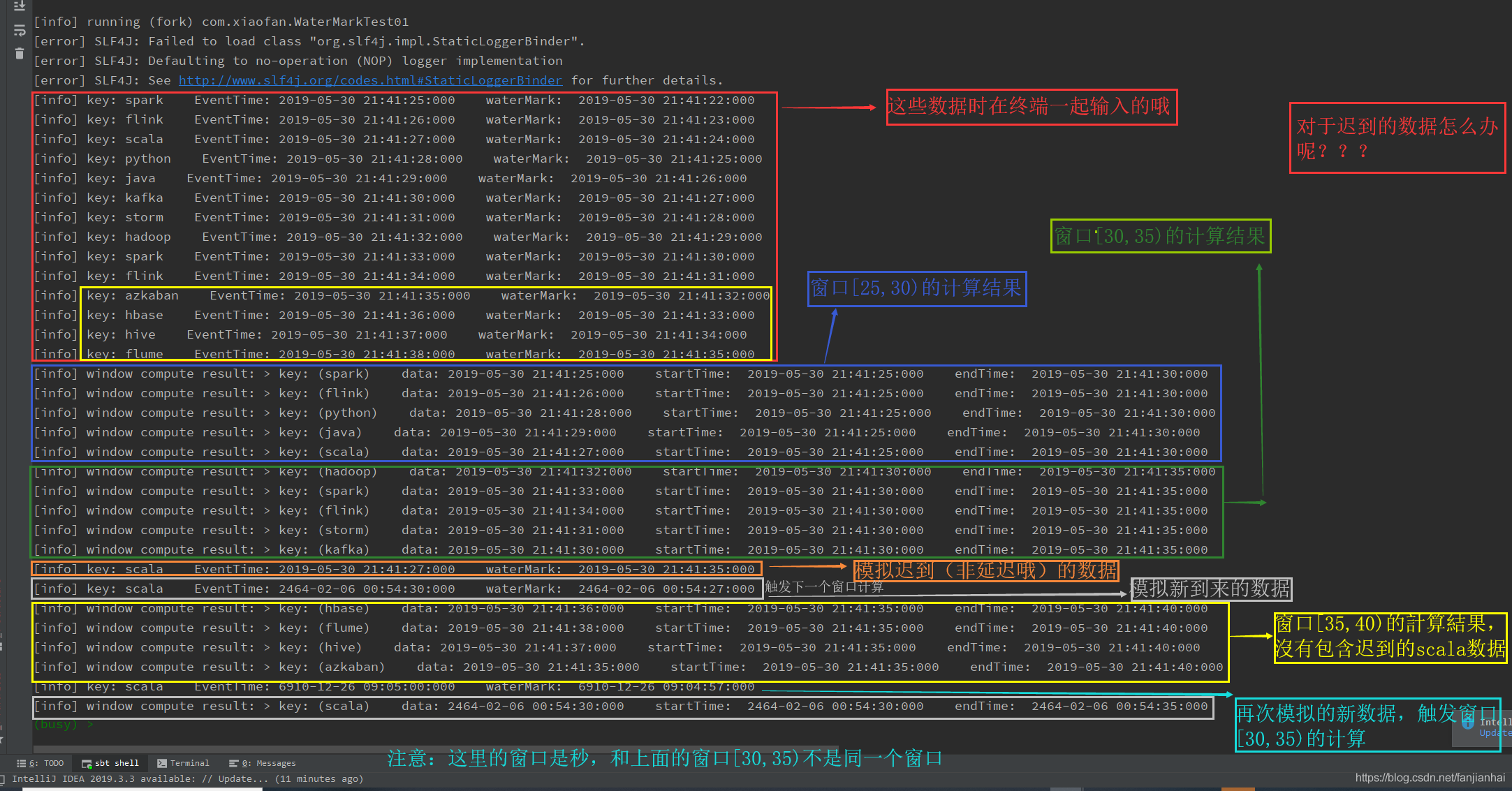
-
注意
处理乱序的数据问题 需要结合window来处理window触发的条件window中必须要有数据eventTime = window结束时间 + waterMark (存在一条数据的事件时间大于等于 window结束时间 + waterMark)
当时间戳为T的水印出现时,表示事件时间t <= T的数据都已经到达,即水印后面应该只能流入事件时间t > T的数据。也就是说,水印是Flink判断迟到数据的标准,同时也是窗口触发的标记。随着新数据的到来,waterMark的值会更新为最新数据事件时间-允许乱序时间值,但是如果这时候来了一条历史数据,waterMark值则不会更新。总的来说,waterMark是为了能接收到尽可能多的乱序数据。
2.3. 延迟测试
-
flink对于迟到数据的处理:
- 如果业务上对迟到的数据有需求,则可以设置允许迟到的时间,那么每个窗口可以在允许等待范围内继续等待迟到的数据
只要当前的watermark时间 < window结束时间+allowedLateness那么就算该窗口已经进行过计算,再次接收到属于该窗口的数据,仍会继续参与窗口计算。
-
源代码package com.xiaofan import org.apache.commons.lang3.time.FastDateFormat import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector import scala.collection.mutable.ArrayBuffer /** * 延迟测试 * flink对于迟到数据的处理: * 如果业务上对迟到的数据有需求,则可以设置允许迟到的时间,那么每个窗口可以在允许等待范围内继续等待迟到的数据 * 只要当前的 watermark时间 < window结束时间 + allowedLateness * 那么就算该窗口已经进行过计算,再次接收到属于该窗口的数据,仍会继续参与窗口计算。 * * @author xiaofan */ object WaterMarkTest02 { // 线程安全的时间格式化对象 val sdf: FastDateFormat = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss:SSS") val hostName = "192.168.1.27" val port = 9999 def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment // 将EventTime设置为流数据时间类型 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val streams: DataStream[String] = env.socketTextStream(WaterMarkTest01.hostName, WaterMarkTest01.port) // 输入数据格式: name:时间戳 // spark:1559223685000 val data: DataStream[(String, Long)] = streams.map(data => { try { val items: Array[String] = data.split(":") (items(0), items(1).toLong) } catch { case _: Exception => println("Invalid Input:" + data) ("0", 0L) } }).filter(data => { !data._1.equals("0") && data._2 != 0L }) // 为数据流中的元素分配时间戳, 并定期创建watermark以监控事件时间的进度 val waterStream: DataStream[(String, Long)] = data.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] { // 事件时间 var currentMaxTimestamp = 0L var maxOutOfOrderDelay = 3000L var lastEmittedWatermark: Long = Long.MinValue override def getCurrentWatermark: Watermark = { // 允许延迟3秒 val potentialWatermark = currentMaxTimestamp - maxOutOfOrderDelay // 保证水印能依次递增 if (potentialWatermark >= lastEmittedWatermark) { lastEmittedWatermark = potentialWatermark } new Watermark(lastEmittedWatermark) } override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = { val time = element._2 if (time > currentMaxTimestamp) { currentMaxTimestamp = time } val outData: String = String.format("key: %s EventTime: %s waterMark: %s", element._1, sdf.format(time), sdf.format(getCurrentWatermark.getTimestamp)) println(outData) time } }) // 迟到的数据 val lateData = new OutputTag[(String, Long)]("late") val result: DataStream[String] = waterStream .keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(5L))) .allowedLateness(Time.seconds(2L)) // 允许数据迟到的时间 (注意:该方法只针对于基于event-time的窗口,如果是基于processing-time,并且指定了非零的time值则会抛出异常) .sideOutputLateData(lateData) // 将迟来的数据保存至给定的outputTag参数,而OutputTag则是用来标记延迟数据的一个对象 .apply(new WindowFunction[(String, Long), String, Tuple, TimeWindow] { override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = { val timeArr = ArrayBuffer[String]() val iterator = input.iterator while (iterator.hasNext) { val tup2 = iterator.next() timeArr.append(sdf.format(tup2._2)) } val outData: String = String.format("key: %s data: %s startTime: %s endTime: %s", key.toString, timeArr.mkString("---"), sdf.format(window.getStart), sdf.format(window.getEnd)) out.collect(outData) } }) result.print("window compute result: ") val late: DataStream[(String, Long)] = result.getSideOutput(lateData) // 通过window等操作返回的DataStream调用该方法,传入标记延迟数据的对象来获取延迟的数据 late.print("late data: ") env.execute(this.getClass.getName) } } -
运行效果
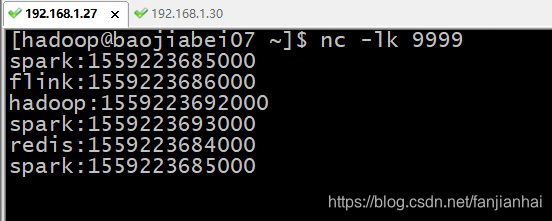
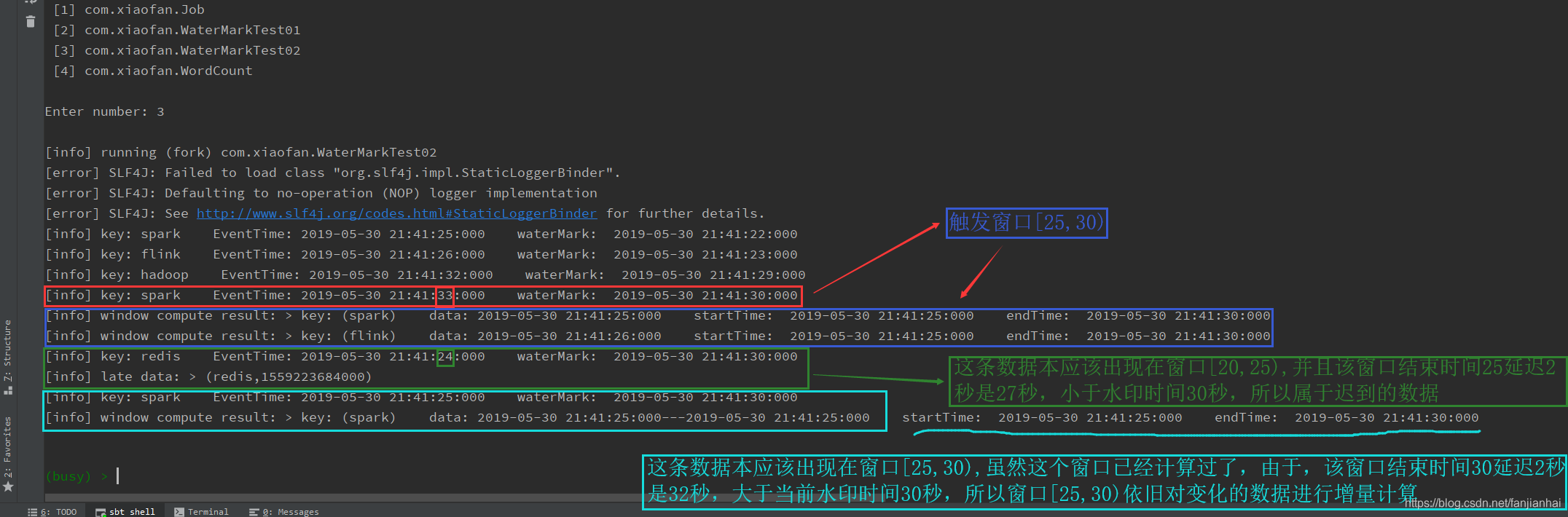
-
总结
如果延迟的数据有业务需要,则设置好允许延迟的时间,每个窗口都有属于自己的最大等待延迟数据的时间限制窗口结束时间+延迟时间=最大waterMark值即当waterMark值大于的上述计算出的最大waterMark值,该窗口内的数据就属于迟到的数据,无法参与window计算
2.4. 再谈Flink事件时间、水印和迟到数据处理
2.5. Generating Timestamps / Watermarks
- 有两种方法可以
分配时间戳和生成水印-
直接在数据流源中
-
sources流可以直接为它们生成的元素分配时间戳,还可以发出水印,这种应用场景下的程序是不需要时间戳分配器的。
注意,如果使用时间戳分配器,则会覆盖sources提供的时间戳和水印。 -
要直接为源source中的元素
分配时间戳,source必须使用SourceContext类中collectWithTimestamp(...)方法。要生成水印,Source必须调用emitWatermark(Watermark)函数。
-
-
时间戳赋值器/水印生成器:在Flink中,时间戳赋值器还定义要发出的水印
- With Periodic Watermarks(周期水印)
AssignerWithPeriodicWatermarks分配时间戳并且周期性的生成水印(可能取决于流元素,或者纯粹基于处理时间)。 - With Punctuated Watermarks(打点水印)
当使用一个特定的事件指出需要生成一个新的水印时,可以通过使用AssignerWithPunctuatedWatermarks类来实现。在这种情况下,Flink首先会调用extractTimestamp(…)方法来给元素分配一个时间戳,然后立即在该元素上执行checkAndGetNextWatermark(…)方法生产水印。
- With Periodic Watermarks(周期水印)
-
常用的两种自定义事件时间戳分配器和水印发射器的对比
AssignerWithPeriodicWatermarks更常用,而且当数据量很大时,效率更高AssignerWithPunctuatedWatermarks一般适合TPS小于100的场景。
-
Timestamps per Kafka Partition

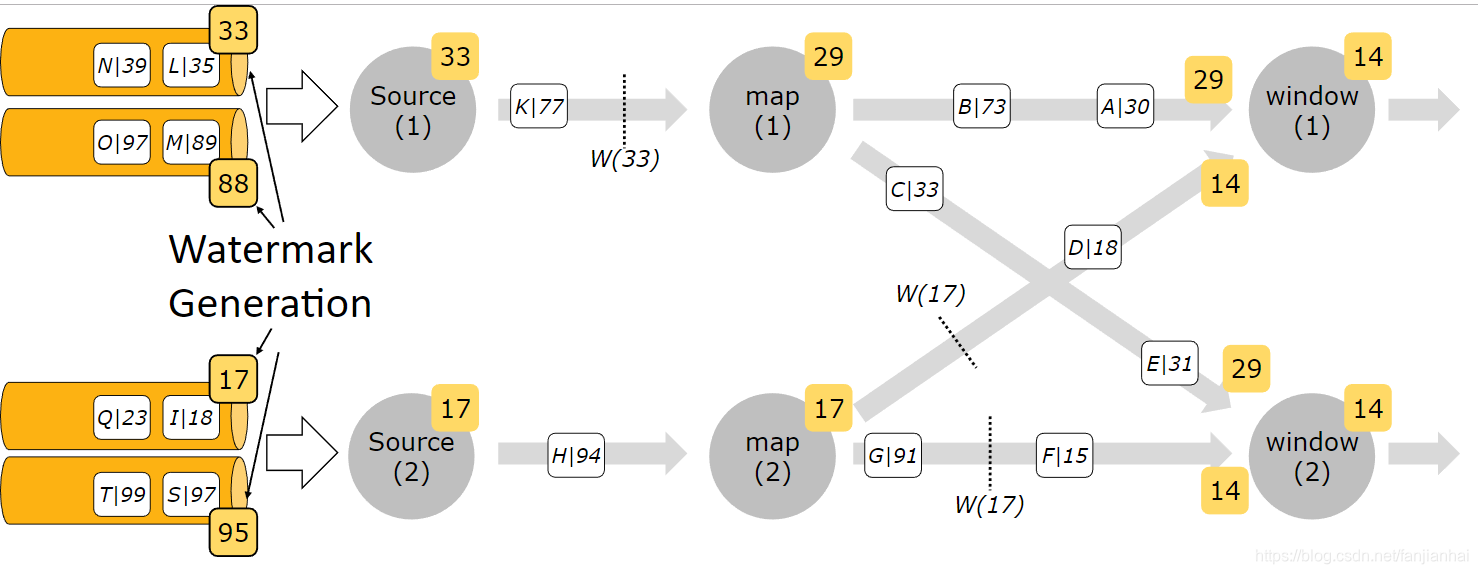
-
总结- 如果使用了时间戳分配器,则数据源中的任何时间戳和水印都将被覆盖
- 时间戳必须在第一个窗口算子之前指定
- 作为一种特殊情况,当使用Kafka作为数据源时,Flink允许在kafka源(或消费者)内部指定一个时间戳分配器/水印发射器
- 详细内容
3. 状态与容错
3.1. Working with State
-
Keyed State 与 Operator State
-
Raw State 与 Managed State
-
Raw State 则保存在算子自己的数据结构中
package com.xiaofan.state import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} /** * mapWithState 方法的传参形式 * * func: (T, Option[S]) => (R, Option[S]) * func: (输入类型, Option[状态类型]) => (返回类型, Option[状态类型]) * * @author xiaofan */ object State { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment val dataStream = env.fromElements(("one", 1), ("two", 2), ("one", 1), ("two", 3), ("three", 2)) dataStream.keyBy(_._1).mapWithState(func).print() env.execute(this.getClass.getName) // 根据输入,将第二个字段进行累加求和(区分第一次求和与非第一次求和) def func(in: (String, Int), count: Option[Int]): ((String, Int), Option[Int]) = count match { case Some(c) => ((in._1, c + in._2), Some(c + in._2)) case None => ((in._1, in._2), Some(in._2)) } } } -
Managed State 由 Flink 运行时控制的数据结构表示,比如内部的 hash table 或者 RocksDB。 比如 “ValueState”, “ListState” 等
-
-
使用 Managed Keyed State
package com.xiaofan.state import org.apache.flink.api.common.functions.RichFlatMapFunction import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor} import org.apache.flink.configuration.Configuration import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} import org.apache.flink.util.Collector class CountWindowAverage extends RichFlatMapFunction[(Long, Long), (Long, Long)] { private var sum: ValueState[(Long, Long)] = _ override def flatMap(input: (Long, Long), out: Collector[(Long, Long)]): Unit = { // access the state value val tmpCurrentSum = sum.value println("tmpCurrentSum: " + tmpCurrentSum + "\tinput: " + input) // If it hasn't been used before, it will be null val currentSum = if (tmpCurrentSum != null) { tmpCurrentSum } else { (0L, 0L) } // update the count val newSum = (currentSum._1 + 1, currentSum._2 + input._2) // update the state sum.update(newSum) // if the count reaches 2, emit the average and clear the state if (newSum._1 >= 2) { out.collect((input._1, newSum._2 / newSum._1)) sum.clear() } } override def open(parameters: Configuration): Unit = { sum = getRuntimeContext.getState( new ValueStateDescriptor[(Long, Long)]("average", createTypeInformation[(Long, Long)]) ) } } object ExampleCountWindowAverage extends App { val env = StreamExecutionEnvironment.getExecutionEnvironment env.fromCollection(List( (1L, 3L), (1L, 5L), (2L, 7L), (2L, 4L), (1L, 2L) )).keyBy(_._1) .flatMap(new CountWindowAverage()) .print() // the printed output will be (1,4) and (1,5) env.execute("ExampleManagedState") } -
状态有效期TTL
package com.xiaofan.state import org.apache.flink.api.common.state.{StateTtlConfig, ValueStateDescriptor} import org.apache.flink.streaming.api.windowing.time.Time /** * 状态有效期 * @author xiaofan */ object TtlFunc { def main(args: Array[String]): Unit = { val ttlConfig: StateTtlConfig = StateTtlConfig // 生存时间 .newBuilder(Time.seconds(1)) .setUpdateType(StateTtlConfig.StateVisibility.NeverReturnExpired) .build() val stateDescriptor = new ValueStateDescriptor[String]("text state", classOf[String]) stateDescriptor.enableTimeToLive(ttlConfig) } } -
使用 Managed Operator State
4. 算子
4.1. 窗口
基于时间的窗口有一个开始时间戳(包含)和一个结束时间戳(排除),它们一起描述窗口的大小。
- 翻转窗口 (
Tumbling Windows) - 滑动窗口 (
Sliding Windows) - 会话窗口 (
Session Windows) 由于会话窗口没有固定的开始和结束,因此它们的计算方式与翻滚和滑动窗口不同。在内部,会话窗口操作符为每个到达的记录创建一个新窗口,如果窗口之间的距离比定义的间隔更近,则将它们合并在一起。- 为了可以合并,会话窗口操作符需要一个合并触发器和一个合并窗口函数,例如
ReduceFunction、AggregateFunction或ProcessWindowFunction(FoldFunction不能合并) - 全局窗口 (
Global Windows)
4.2. Joining
- Tumbling Window Join
- Sliding Window Join
- Session Window Join
- Interval Join














 2194
2194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









