









首先说下,为什么题目后面会有个“无语篇”,因为我觉得今晚这几个钟头太坑爹了。为什么,且听我慢慢道来:
按照昨天的计划,我应该把代码仿造成单机可运行的代码。但是首先我要有输入数据不是?所以我最开始做的就是仿造clusterIn的数据,即中心向量的文件。昨天也说过中心向量文件应该就是把一组(key,value)对(要求value的格式为ClusterWritable,key格式任意)写入一个序列文件即可,然后使用
KMeansUtil.configureWithClusterInfo(conf, clustersIn, clusters);
这个就可以玩儿了,所以我编写了下面的代码:
package mahout.fansy.test.kmeans;
import java.io.IOException;
import java.net.URI;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.SequenceFile;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.mahout.clustering.Cluster;
import org.apache.mahout.clustering.canopy.Canopy;
import org.apache.mahout.clustering.iterator.ClusterWritable;
import org.apache.mahout.clustering.kmeans.Kluster;
import org.apache.mahout.common.distance.ManhattanDistanceMeasure;
import org.apache.mahout.common.iterator.sequencefile.PathFilters;
import org.apache.mahout.common.iterator.sequencefile.PathType;
import org.apache.mahout.common.iterator.sequencefile.SequenceFileDirValueIterable;
import org.apache.mahout.math.RandomAccessSparseVector;
import org.apache.mahout.math.Vector;
public class TestConfigureWithClusterInfo {
public static void main(String[] args) throws IOException {
// testWrClWr(); // 测试函数
testConfig();
System.out.println("done...");
}
/**
* 把一个double数组写入sequence file,格式为 ClusterWritable
* @param center double数组
* @param output 输出路径
* @throws IOException
*/
public static void writeClusterWritable(String output,double[][] center) throws IOException{
Configuration conf =new Configuration();
conf.set("mapred.job.tracker", "hadoop:9001");
FileSystem fs=FileSystem.get(URI.create(output),conf);
Path path=new Path(output);
Text key =new Text();
ClusterWritable value=new ClusterWritable();
SequenceFile.Writer writer = null;
try {
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass(),SequenceFile.CompressionType.NONE); // here change
for (int i = 0; i < center.length; i++) {
key.set("C-"+String.valueOf(i));
Vector v=new RandomAccessSparseVector(center[0].length);
for(int j=0;j<center[0].length;j++){
v.set(j, i*4+Math.random());
}
Canopy canopy=new Canopy(v,i,new ManhattanDistanceMeasure());
value.setValue(canopy);
// System.out.printf("[%s]\t%s\t%s\n", writer.getLength(), key, value);
writer.append(key, value);
}
} finally {
IOUtils.closeStream(writer);
}
}
/**
* 测试writeClusterWritable() 是否ok
* @throws IOException
*/
public static void testWrClWr() throws IOException{
double[][] center=new double[][]{
{0.1,0.2,0.3},
{10,12,13}
};
// String path="hdfs://hadoop:9000/user/hadoop/output/test-configureCluster";
// String path="hdfs://hadoop:9000/user/hadoop/output/test-configureCluster1";
String path="hdfs://hadoop:9000/user/hadoop/output/test-configureCluster2";
writeClusterWritable(path,center);
}
/**
* 把序列文件读入到一个变量中;
* @param clusterPath 序列文件
* @param conf Configuration
* @return 序列文件读取的变量
*/
public static List<Cluster> testConfigureWith(Path clusterPath,Configuration conf){
List<Cluster> clusters = new ArrayList<Cluster>();
for (Writable value : new SequenceFileDirValueIterable<Writable>(clusterPath, PathType.LIST,
PathFilters.partFilter(), conf)) {
Class<? extends Writable> valueClass = value.getClass();
if (valueClass.equals(ClusterWritable.class)) {
ClusterWritable clusterWritable = (ClusterWritable) value;
value = clusterWritable.getValue();
valueClass = value.getClass();
}
// log.debug("Read 1 Cluster from {}", clusterPath);
if (valueClass.equals(Kluster.class)) {
// get the cluster info
clusters.add((Kluster) value);
} else if (valueClass.equals(Canopy.class)) {
// get the cluster info
Canopy canopy = (Canopy) value;
clusters.add(new Kluster(canopy.getCenter(), canopy.getId(), canopy.getMeasure()));
} else {
throw new IllegalStateException("Bad value class: " + valueClass);
}
}
return clusters;
}
/**
* testConfigureWith() 的测试程序
*/
public static void testConfig(){
// Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/test-conf");
// Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/output/test-configureCluster");
// Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/output/test-configureCluster1");
Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/output/part-test-configureCluster1");
// Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/output/test-configureCluster2");
// Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/output/part-test-configureCluster2");
// Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/output/test_canopy1/clusters-0-final/part-r-00000");// test ok
// Path clusterPath=new Path("hdfs://hadoop:9000/user/hadoop/output/test_canopy1/clusters-0-final"); // test ok;
Configuration conf=new Configuration();
conf.set("mapred.job.tracker", "hadoop:9001");
testConfigureWith(clusterPath, conf);
}
}
一看,感觉ok哦应该可以的吧,所以我就又写了上面的testConfigureWith()方法,即把含有中心点的向量文件按照mahout里面的方法读入一个变量中,然后使用testConfig()方法进行测试,直接在testConfigureWith()的return一行设置断点,直接运行,我X,clusters居然是空的?神马情况?然后我就感觉不会是我猜错了吧,这么命苦?
然后怎么办,继续想办法呗,我们对待bug就要有越战越勇的精神,不然我这么晚了还在这里写blog?好吧,我有点无聊了。
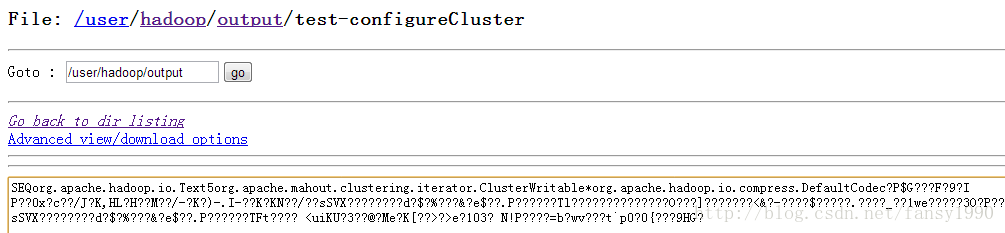
对了,那么直接使用canopy最后产生的文件是否可以读的出来呢?我就又改了之前分析canopy的代码了,之前是把txt直接读入,然后生成的中心点文件也是txt类型的,如下所示:
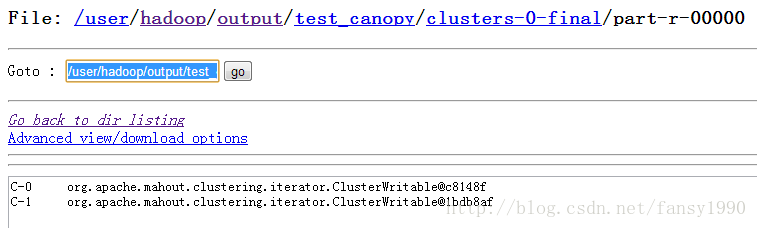
然后这次只是把CanopyDriver的输出类型改为sequence的了,直接加上一句:
job.setOutputFormatClass(SequenceFileOutputFormat.class);然后可以查看新的文件是:
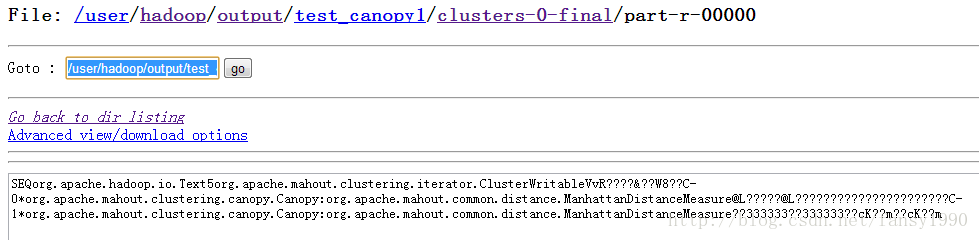
感觉这个和刚才的差别多嘛,不管了,试试吧。直接改路径为这个,然后跑testConfig()方法,嗨呀,居然clusters有值了。oh,my god。我说原来确实这个文件可以作为中心点文件呀,和我猜的差不多嘛。哎,不过怎么我自己写的不行呢?对照两个文件的显示,我看到了一点,好像我写入的有压缩?
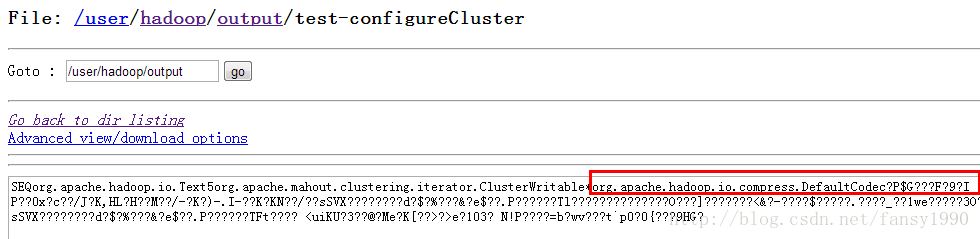
writer = SequenceFile.createWriter(fs, conf, path,
key.getClass(), value.getClass(),SequenceFile.CompressionType.NONE); // here change
哈哈,这次没有了吧,我再运行testConfig()方法,断点调试,我艹,我都不想说粗口了,还不行,现在时间已经去到了1点了亲,还不行?我还睡不睡啦。为什么clusters还是空?没理由吧,都是一样的啦。怎么会这样?这个时候我就会想,原来奋斗是这么苦逼的一件事。。。
对了,调试。既然两个文件都是一样的,那我一步步调试不就可以发现他们的不同了么?好吧,开始调试
。。。
居然是.class文件?好吧,我把hadoop的源码也拷贝过来吧。继续调试。。。
然后发现在类SequenceFileDirValueIterator的70行两个文件得到的status是不一样的,我产生的是空,而canopy的是有值的。所以进一步,然后我就发现了惊人的一幕,在FileSystem中的一个方法:
private void listStatus(ArrayList<FileStatus> results, Path f,
PathFilter filter) throws IOException {
FileStatus listing[] = listStatus(f);
if (listing != null) {
for (int i = 0; i < listing.length; i++) {
if (filter.accept(listing[i].getPath())) {
results.add(listing[i]);
}
}
}
}
private static final PathFilter PART_FILE_INSTANCE = new PathFilter() {
@Override
public boolean accept(Path path) {
String name = path.getName();
return name.startsWith("part-") && !name.endsWith(".crc");
}
};然后我把我的文件改名为part-开头,然后可以读取我产生的文件了。还有一点,这个和是否压缩没有关系,不压缩,只要你的文件是以part-开头也是可以读取的。好吧,睡了,明天还要上班。。。














 6611
6611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









