






后缀数组是字符串处理的重要工具,它是由原字符串的所有后缀的字典排序的结果,具有较高的检索效率.
基本概念
- 字符串的大小比较:关于所说的字符串的大小比较,是指通常所说的字典顺序比较,也就是对于两个字符串u、v,从i从0开始顺次比较u[i]和v[i],若u[i] = v[i],令i加1;若v[i] < v[i],则u < v;u[i] > v[i] 则认为u > v,比较结束. 若i大于len(u)或len(v),字符串的大小与其长度相关.
- 后缀树组sa:将字符串s的n个后缀排序后,将后缀的起始下标依次放入数组sa,即sa[i]表示第i大的后缀的开始位置.
- 名次数组rank:rank[i]保存的是suffix(i)在所有后缀中的排序名次,若rank[i] = j,则sa[j] = i,即后缀数组sa与名次数组rank构成互逆关系,sa[rank[i]] = i.
倍增算法
倍增算法的主要思路是 s[i...i+2k−1] 的排名可以通过 s[i...i+2k−1−1] 和 s[i+2k−1...i+2k−1] 的排名得到. 已知长度为 2k−1 字符串的排名,则可作为每个长度为 2k 的字符串求排名的关键字xy, s[i...i+2k−1] 第一关键字x为 s[i...i+2k−1−1] 的排名,第二关键字y为 s[i+2k−1...i+2k−1] 的排名.
倍增算法的计算过程如下图所示
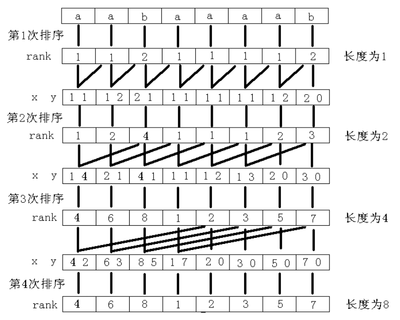
倍增算法的代码如下
const int maxn = 1024;
int wa[maxn], wb[maxn], ws[maxn], wv[maxn], sa[maxn];
int cmp(int* r, int a, int b, int j){
return r[a]==r[b] && r[a+j]==r[b+j];
}
/*
参数r为字符串数组,sa为后缀数组,约定除r[n-1]外的字符r[i]都大于0,r[n-1]=0,通过在原字符串末尾补零实现,并且字符的最大值小于m
*/
void da(int* r, int* sa, int n, int m){
int i, j, p, *x=wa, *y=wb, *t;
//以下四行代码是对每个字符(即长度为1的字符串)进行基数排序
for(i=0; i<m; i++) ws[i] = 0;
//x[]的本意保存各个后缀的rank值,因为后续操作只涉及x[]的比较,所以不必存储真实的rank值,能够反映相对大小即可
for(i=0; i<n; i++) ws[x[i]=r[i]]++;
for(i=1; i<m; i++) ws[i] += ws[i-1];
//i之所以从n-1开始循环,保证当出现相等字符串时,靠前的字符串更小些
for(i=n-1; i>=0; i--) sa[--ws[x[i]]] = i;
/*
多次基数排序,先按第二关键字排序,再按第一关键字排序
参数j表示当前要合并的字符串的长度,p表示不同字符串的数量,若p=n说明各个后缀字符串的大小关系已经确定,循环结束,m同样表示基数排序元素的范围
*/
for(j=1,p=1; p<n; j*=2,m=p){
//对第二关键字进行排序,因为从n-j至j的元素第二关键字都是0,这些元素理所当前排在前面
for(p=0,i=n-j; i<n; i++) y[p++] = i;
//处理第二关键字不为0的部分,这里只有sa[i]>=j的以sa[i]开始的字符串的rank值才会作为以sa[i]-j开始的字符串的第二关键字,这里利用前面得到排序结果做些优化,因为rank[sa[i]]是递增的,所以这里实现对第二关键字的排序
for(i=0; i<n; i++) if(sa[i]>=j) y[p++] = sa[i]-j;
//下面对第一关键字进行排序
for(i=0; i<n; i++) wv[i] = x[y[i]];
for(i=0; i<m; i++) ws[i] = 0;
for(i=0; i<n; i++) ws[wv[i]]++;
for(i=1; i<n; i++) ws[i] += ws[i-1];
//其中y[i]表示第二关键字的下标,若k=y[i],相当于
//sa[--ws[x[k]]] = k
for(i=n-1; i>=0; i--) sa[--ws[wv[i]]] = y[i];
//计算合并之后的rank数组,因为这里需要利用x[]值计算并保存回x[],而且y[]以后不再使用,所以利用指针交换实现优化
for(t=x,x=y,y=t,p=1,r[sa[0]]=0,i=1; i<n; i++)
//判断是否存在相同的字符串,相同的字符串rank值相同
x[sa[i]] = cmp(y,sa[i-1],sa[i],j)?p-1:p++;
}
}最长公共前缀
计算出后缀数组sa和名次数组rank还不够,通常我们需要利用后缀数组和名次数组计算出辅助数组height—-最长公共前缀
height数组:定义height[i] = suffix(sa[i-1])和suffix(sa[i])的最长公共前缀,也即排名相邻的两个后缀的最长公共前缀.
由height数组可知,对于任意的j和k,我们不妨假设rank[j] < rank[k],则有以下性质:suffix(j) 和 suffix(k) 的最长公共前缀为height[rank[j]+1],height[rank[j]+2], height[rank[j]+3], … ,height[rank[k]]中的最小值
如何高效的计算height数组
定义h[i] = height[rank[i]],即h[i]表示 suffix(i) 和排在前一名的后缀suffix(sa[rank[i]-1]) 的最长公共前缀,由性质可知
h[i]>=h[i−1]−1
简单的证明如下:设 suffix(k) 是排在 suffix(i-1) 前一位的后缀,则它们的最长公共前缀显然是 h[i-1],现在考虑 suffix(k+1) 和 suffix(i) 的关系.
第一种情况,第k个字符串和第i-1个字符串的首字符不同,即h[i-1] = 0,显然原式成立.
第二种情况,第k个字符串和第i-1个字符串的首字符相同,因为suffix(k) 是排在suffix(i-1)前一位的后缀,显然第k+1个字符串排在第i个字符串的前面,即suffix(k+1)肯定排在suffix(i)的前面,因为suffix(k+1)&suffix(i)相对于suffix(k)&suffix(i-1)只是去掉相同的第一个字符,所以suffix(i)和排在前一位的后缀的最长公共前缀至少为h[i-1]-1.
所以我们可以按h[1],h[2],…,h[n]的顺序来求height数组
算法代码如下
void getheight(int* r, int *sa, int n){
int i, j, k=0;
for(i=1; i<=n; i++) rank[sa[i]] = i;
for(i=0; i<n; height[rank[i++]]=k)
for(k?k--:0,j=sa[rank[i]-1]; r[i+k]==r[j+k]; k++)
}
//最后还要注意函数的调用问题,从这我们可以清晰地认识到函数da和getheight中的参数n是不同的,同时height[]的有效范围是height[1]...height[n],其中height[1]=0,因为sa[0]实际就是之前补的0,自然sa[0]与sa[1]的最长公共前缀为0
da(r,sa,n+1,128);
getheight(r,sa,n);














 451
451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









