







真实内存指的是ByteBuf底层的array和DirectByteBuffer,真实内存池化的好处如下:
- 降低真实内存的分配开销。因为DirectByteBuffer的分配很抵效(创建堆外内存的速度比堆内存慢了10到20倍),特别的对于DirectByteBuffer的分配开销降低尤为明显。
- 因为真实内存可以复用,避免了大量对象的回收,降低了GC频率。
怎么降低线程竞争的
- 默认有核数*2个PoolArea,每个线程初始绑定一个最少线程使用的PoolArea,线程一旦绑定了对应的PoolArea,不能再改变PoolArea。
- 本地线程也有cache。
1. 总体结构
1.1 整体结构
首先介绍些netty内存池的层级结构,主要分为Arena、ChunkList、Chunk、Page、Subpage这5个层级,这几个层级的关系由大到小,如下图所示:
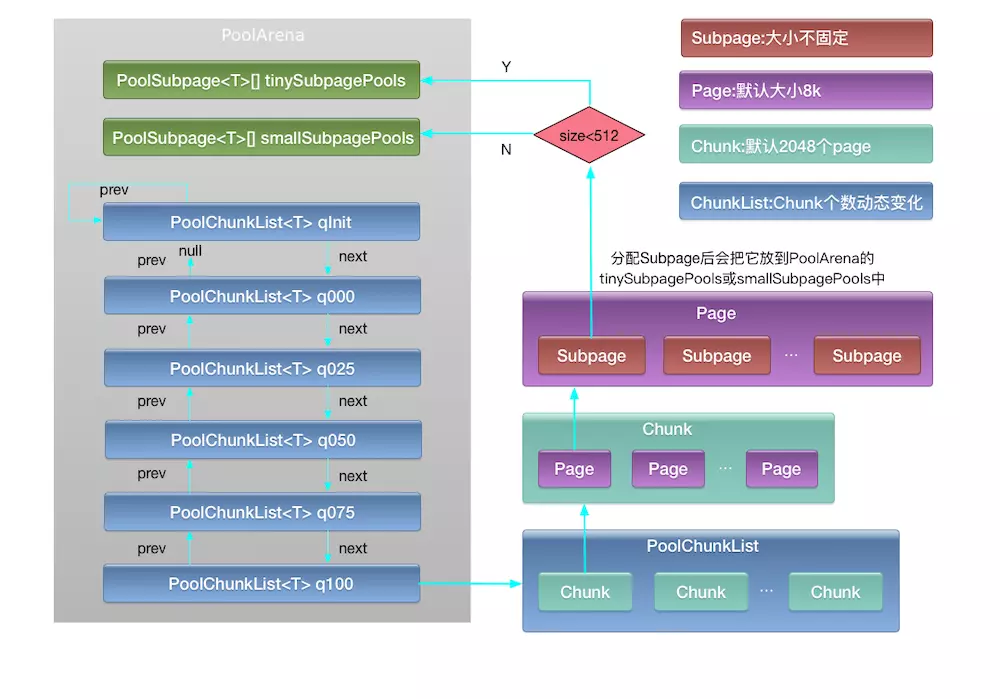
Arena代表1个内存区域,为了优化内存区域的并发访问,netty中内存池是由多个Arena组成的数组,分配时会每个线程按照轮询策略选择1个Arena进行内存分配。
1个Arena由两个PoolSubpage数组和多个ChunkList组成。两个PoolSubpage数组分别为tinySubpagePools和smallSubpagePools。多个ChunkList按照双向链表排列,每个ChunkList里包含多个Chunk,每个Chunk里包含多个Page(默认2048个),每个Page(默认大小为8k字节)由多个Subpage组成。
每个Arena由如下几个ChunkList构成:
- PoolChunkList<T> qInit:存储内存利用率0-25%的chunk
- PoolChunkList<T> q000:存储内存利用率1-50%的chunk
- PoolChunkList<T> q025:存储内存利用率25-75%的chunk
- PoolChunkList<T> q050:存储内存利用率50-100%的chunk
- PoolChunkList<T> q075:存储内存利用率75-100%的chunk
- PoolChunkList<T> q100:存储内存利用率100%的chunk
每个ChunkList里包含的Chunk数量会动态变化,比如当该chunk的内存利用率变化时会向其它ChunkList里移动。
每个Chunk里默认包含2048个Page。
每个Page包含的Subpage的大小和个数由首次从该Page分配的内存大小决定,1个page默认大小为8k,如果首次在该page中需要分配1k字节,那么该page就被分为8个Subpage,每个Subpage大小为1k。
1.2 PoolArea申请流程
在PoolArea中申请内存的流程图如下:
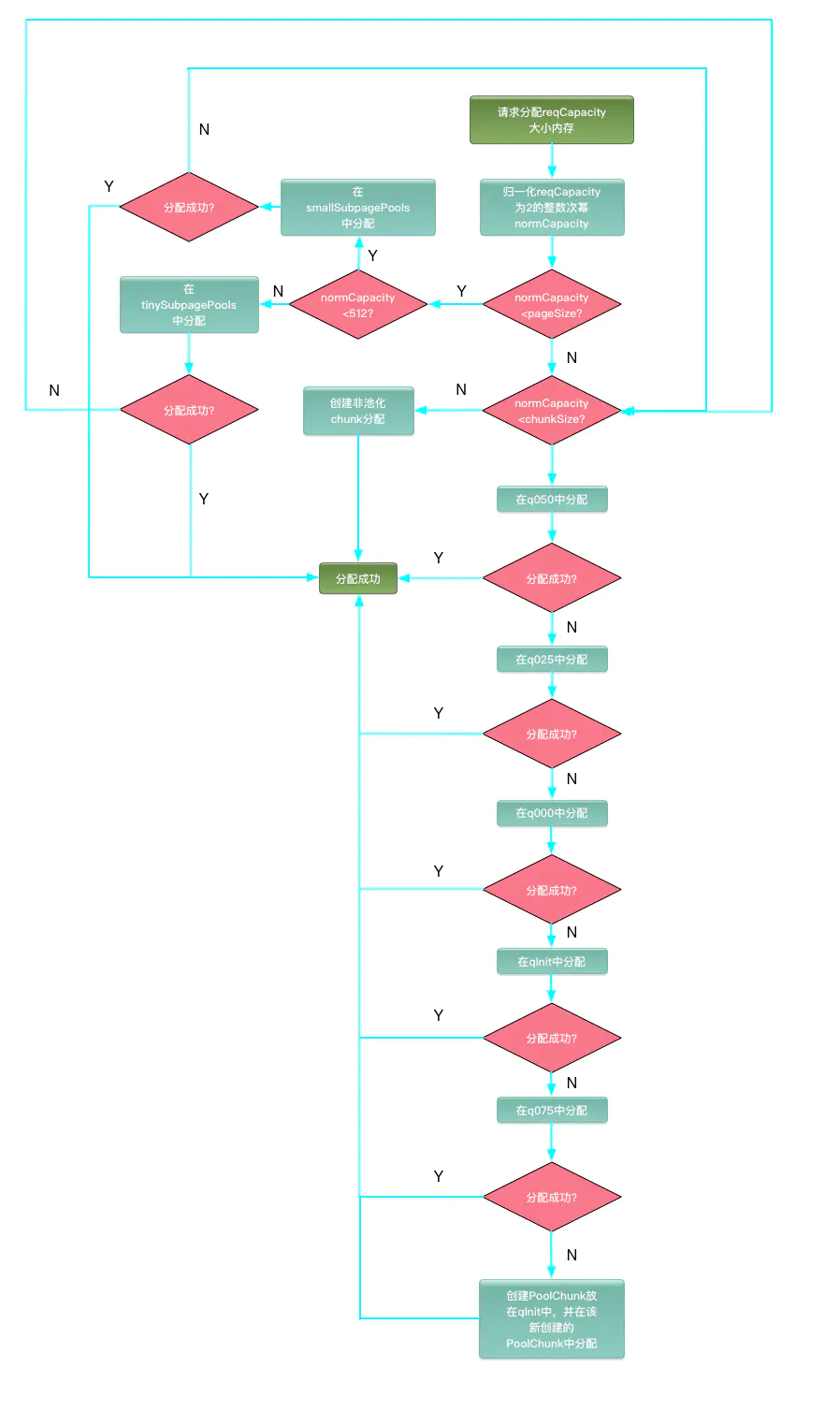
- 对于小于pageSize大小的内存,会在tinySubpagePools或smallSubpagePools中分配,tinySubpagePools用于分配小于512字节的内存,smallSubpagePools用于分配大于512小于pageSize的内存。
- 对于大于pageSize小于chunkSize大小的内存,会在PoolChunkList的Chunk中分配。
- 对于大于chunkSize大小的内存,直接创建非池化Chunk来分配内存,并且该Chunk不会放在内存池中重用。
1.3 PoolChunkList申请流程
对于在q050、q025、q000、qInit、q075这些PoolChunkList里申请内存的流程图如下:
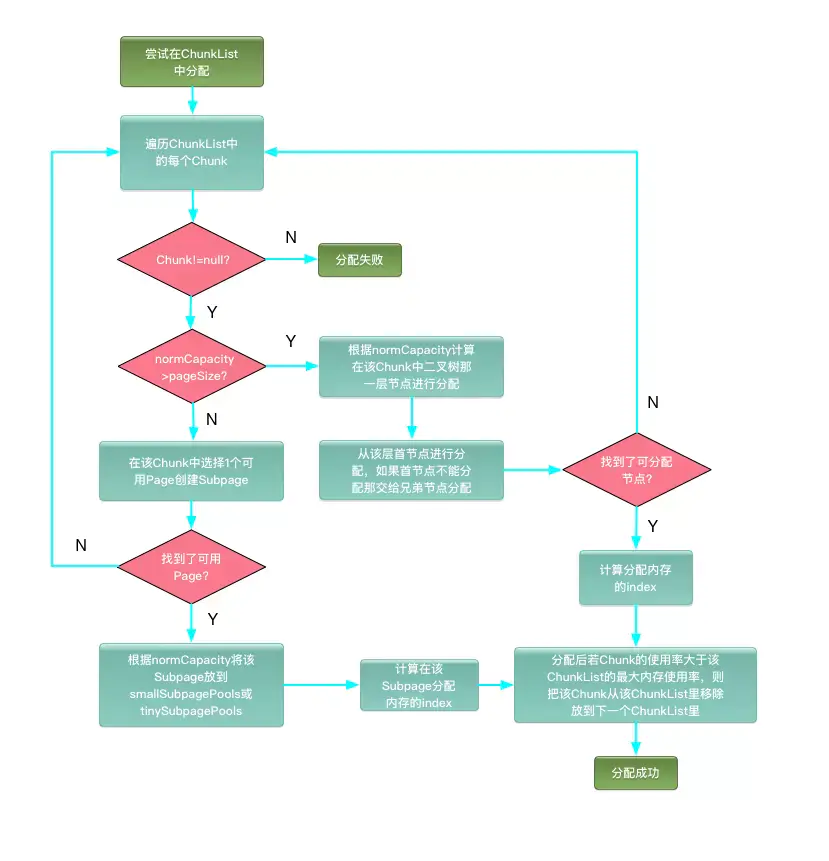
- 在PoolChunk中,数组组织呈完美二叉树数据结构。二叉树叶子节点为2048个Page,每个Page的父节点用于分配pageSize
*2大小内存,同理,对于Page叶子节点的父节点的父节点,用于分配pageSize*4大小的内存,后面以此类推。 - 在初始状态时,tinySubpagePools和smallSubpagePools为空,因此最初分配小于pageSize的内存时,需要新建1个PoolChunk来分配这块小内存,PoolChunk会对Page分类成若干Subpage,然后用Subpage分配这块小内存,最后会把该Subpage放在tinySubpagePools或smallSubpagePools中。
2. 具体细节
2.1 PoolChunk
Netty一次向系统申请16M的连续内存空间,这块内存通过PoolChunk对象包装,为了更细粒度的管理它,进一步的把这16M内存分成了2048个页(pageSize=8k)。页作为Netty内存管理的最基本的单位 ,所有的内存分配首先必须申请一块空闲页。(Ps: 这里可能有一个疑问,如果申请1Byte的空间就分配一个页是不是太浪费空间,在Netty中Page还会被细化用于专门处理小于4096Byte的空间申请 )那么这些Page需要通过某种数据结构跟算法管理起来。最简单的是采用数组或位图管理
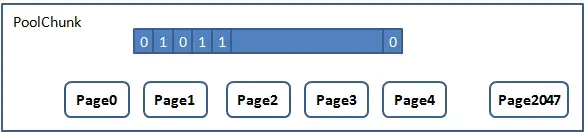
如上图1表示已申请,0表示空闲。这样申请一个Page的复杂度为O(n),但是申请k个连续Page,就立马退化为O(kn)。
Netty采用完全二叉树进行管理,树中每个叶子节点表示一个Page,即树高为12,中间节点表示页节点的持有者。
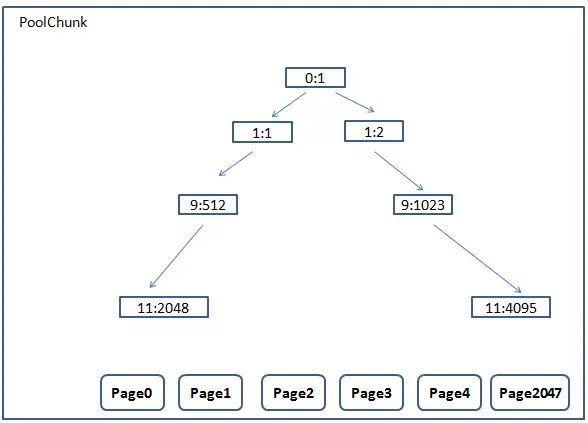
这样的一个完全二叉树可以用大小为4096的数组表示,数组元素的值含义为:
private final byte[] memoryMap; //表示完全二叉树,共有4096个
private final byte[] depthMap; //表示节点的层高,共有4096个
- memoryMap[i] = depthMap[i]:表示该节点下面的所有叶子节点都可用,这是初始状态
- memoryMap[i] = depthMap[i] + 1:表示该节点下面有一部分叶子节点被使用,但还有一部分叶子节点可用
- memoryMap[i] = maxOrder + 1 = 12:表示该节点下面的所有叶子节点不可用
有了上面的数据结构,那么页的申请跟释放就非常简单了,只需要从根节点一路遍历找到可用的节点即可,复杂度为O(lgn)。代码为:
#PoolChunk
//根据申请空间大小,选择申请方法
long allocate(int normCapacity) {
if ((normCapacity & subpageOverflowMask) != 0) { // >= pageSize
return allocateRun(normCapacity); //大于1页
} else {
return allocateSubpage(normCapacity);
}
}
//按页申请
private long allocateRun(int normCapacity) {
//计算需要在哪一层开始
int d = maxOrder - (log2(normCapacity) - pageShifts);
int id = allocateNode(d);
if (id < 0) {
return id;
}
freeBytes -= runLength(id);
return id;
}
/ /申请空间,即节点编号
private int allocateNode(int d) {
int id = 1; //从根节点开始
int initial = - (1 << d); // has last d bits = 0 and rest all = 1
byte val = value(id);
if (val > d) { // unusable
return -1;
}
while (val < d || (id & initial) == 0) { // id & initial == 1 << d for all ids at depth d, for < d it is 0
id <<= 1; //左节点
val = value(id);
if (val > d) {
id ^= 1; //右节点
val = value(id);
}
}
byte value = value(id);
assert value == d && (id & initial) == 1 << d : String.format("val = %d, id & initial = %d, d = %d",
value, id & initial, d);
//更新当前申请到的节点的状态信息
setValue(id, unusable); // mark as unusable
//级联更新父节点的状态信息
updateParentsAlloc(id);
return id;
}
//级联更新父节点的状态信息
private void updateParentsAlloc(int id) {
while (id > 1) {
int parentId = id >>> 1;
byte val1 = value(id);
byte val2 = value(id ^ 1);
byte val = val1 < val2 ? val1 : val2;
setValue(parentId, val);
id = parentId;
}
}
2.2 PoolSubpage
对于小内存(小于4096)的分配还会将Page细化成更小的单位Subpage。Subpage按大小分有两大类,36种情况:
- Tiny:小于512的情况,最小空间为16,对齐大小为16,区间为[16,512),所以共有32种情况。
- Small:大于等于512的情况,总共有四种,512,1024,2048,4096。
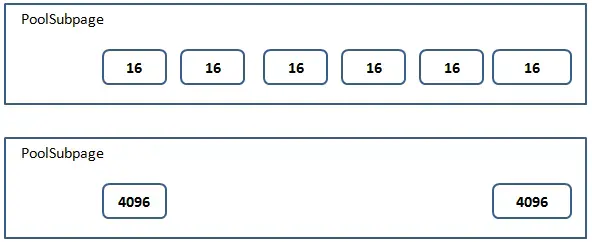
PoolSubpage中直接采用位图管理空闲空间(因为不存在申请k个连续的空间),所以申请释放非常简单。
代码:#PoolSubpage(数据结构)
final PoolChunk<T> chunk; //对应的chunk
private final int memoryMapIdx; //chunk中那一页,肯定大于等于2048
private final int pageSize; //页大小
private final long[] bitmap; //位图
int elemSize; //单位大小
private int maxNumElems; //总共有多少个单位
private int bitmapLength; //位图大小,maxNumElems >>> 6,一个long有64bit
private int nextAvail; //下一个可用的单位
private int numAvail; //还有多少个可用单位;
这里bitmap是个位图,0表示可用,1表示不可用. nextAvail表示下一个可用单位的位图索引,初始状态为0,申请之后设置为-1. 只有在free后再次设置为可用的单元索引。在PoolSubpage整个空间申请的逻辑就是在找这个单元索引,只要理解了bitmap数组是个位图,每个数组元素表示64个单元代码的逻辑就比较清晰了
#PoolSubpage
long allocate() {
if (elemSize == 0) {
return toHandle(0);
}
if (numAvail == 0 || !doNotDestroy) {
return -1;
}
final int bitmapIdx = getNextAvail(); //查找下一个单元索引
int q = bitmapIdx >>> 6; //转为位图数组索引
int r = bitmapIdx & 63; //保留最低的8位
assert (bitmap[q] >>> r & 1) == 0;
bitmap[q] |= 1L << r; //设置为1
if (-- numAvail == 0) {
removeFromPool();
}
return toHandle(bitmapIdx); //对索引进行特化处理,防止与页索引冲突
}
private int getNextAvail() {
int nextAvail = this.nextAvail;
if (nextAvail >= 0) { //大于等于0直接可用
this.nextAvail = -1;
return nextAvail;
}
return findNextAvail(); //通常走一步逻辑,只有第一次跟free后nextAvail才可用
}
//找到位图数组可用单元,是一个long类型,有[1,64]单元可用
private int findNextAvail() {
final long[] bitmap = this.bitmap;
final int bitmapLength = this.bitmapLength;
for (int i = 0; i < bitmapLength; i ++) {
long bits = bitmap[i];
if (~bits != 0) {
return findNextAvail0(i, bits);
}
}
return -1;
}
//在64的bit中找到一个可用的
private int findNextAvail0(int i, long bits) {
final int maxNumElems = this.maxNumElems;
final int baseVal = i << 6;
for (int j = 0; j < 64; j ++) {
if ((bits & 1) == 0) {
int val = baseVal | j;
if (val < maxNumElems) {
return val;
} else {
break;
}
}
bits >>>= 1;
}
return -1;
}
2.3 PoolSubpage池
第一次申请小内存空间的时候,需要先申请一个空闲页,然后将该页转成PoolSubpage,再将该页设为已被占用,最后再把这个PoolSubpage存到PoolSubpage池中。这样下次就不需要再去申请空闲页了,直接去池中找就好了。Netty中有36种PoolSubpage,所以用36个PoolSubpage链表表示PoolSubpage池。
#PoolArena
private final PoolSubpage<T>[] tinySubpagePools;
private final PoolSubpage<T>[] smallSubpagePools;
#PoolSubpage
PoolSubpage<T> prev;
PoolSubpage<T> next;

#PoolArena
allocate(...reqCapacity...){
final int normCapacity = normalizeCapacity(reqCapacity);
//找到池的类型跟下标
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
final PoolSubpage<T> head = table[tableIdx];
synchronized (head) {
final PoolSubpage<T> s = head.next;
if (s != head) {
//通过PoolSubpage申请
long handle = s.allocate();
...
}
}
}
2.4 PoolChunkList
上面讨论了PoolChunk的内存分配算法,但是PoolChunk只有16M,这远远不够用,所以会很很多很多PoolChunk,这些PoolChunk组成一个链表,然后用PoolChunkList持有这个链表
#PoolChunkList
private PoolChunk<T> head;
#PoolChunk
PoolChunk<T> prev;
PoolChunk<T> next;

这里还没这么简单,它有6个PoolChunkList,所以将PoolChunk按内存使用率分类组成6个PoolChunkList,同时每个PoolChunkList还把各自串起来,形成一个PoolChunkList链表。
#PoolChunkList
private final int minUsage; //最小使用率
private final int maxUsage; //最大使用率
private final int maxCapacity;
private PoolChunkList<T> prevList;
private final PoolChunkList<T> nextList;
#PoolArena
//[100,) 每个PoolChunk使用率100%
q100 = new PoolChunkList<T>(this, null, 100, Integer.MAX_VALUE, chunkSize);
//[75,100) 每个PoolChunk使用率75-100%
q075 = new PoolChunkList<T>(this, q100, 75, 100, chunkSize);
//[50,100)
q050 = new PoolChunkList<T>(this, q075, 50, 100, chunkSize);
//[25,75)
q025 = new PoolChunkList<T>(this, q050, 25, 75, chunkSize);
//[1,50)
q000 = new PoolChunkList<T>(this, q025, 1, 50, chunkSize);
qInit = new PoolChunkList<T>(this, q000, Integer.MIN_VALUE, 25, chunkSize);

既然按使用率分配,那么PoolChunk在使用过程中是会动态变化的,所以PoolChunk会在不同PoolChunkList中变化。同时申请空间,使用哪一个PoolChunkList也是有先后顺序的
#PoolChunkList
boolean allocate(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
if (head == null || normCapacity > maxCapacity) {
return false;
}
for (PoolChunk<T> cur = head;;) {
long handle = cur.allocate(normCapacity);
if (handle < 0) {
cur = cur.next;
if (cur == null) {
return false;
}
} else {
cur.initBuf(buf, handle, reqCapacity);
if (cur.usage() >= maxUsage) {
remove(cur);
nextList.add(cur); //移到下一个PoolChunkList中
}
return true;
}
}
}
#PoolArena
allocateNormal(...){
if (q050.allocate(...) || q025.allocate(...) ||
q000.allocate(...) || qInit.allocate(...) ||
q075.allocate(...)) {
return;
}
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
...
qInit.add(c);
}
这样设计的目的是考虑到随着内存的申请与释放,PoolChunk的内存碎片也会相应的升高,使用率越高的PoolChunk其申请一块连续空间的失败的概率也会大大的提高。
- qInit前置节点为自己,且minUsage=Integer.MIN_VALUE,意味着一个初分配的chunk,在最开始的内存分配过程中(内存使用率<25%),即使完全释放也不会被回收,会始终保留在内存中。
- q000没有前置节点,当一个chunk进入到q000列表,如果其内存被完全释放,则不再保留在内存中,其分配的内存被完全回收。
- 各个PoolChunkList的区间是交叉的,这是故意的,因为如果介于一个临界值的话,PoolChunk会在前后PoolChunkList不停的来回移动。
- 为什么area中ChunkList的分配顺序如下面代码所示,要从q050开始?
4.1 为什么不从q0000开始?
因为永远从空闲率很高的chunk分配,那么chunk的空闲率就不太可能降为0,chunk自然不会被回收,造成内存得到释放。当负载很大申请了很多的chunk,但是负载降低时chunk又不能及时回收。
4.2 为什么不从qinit开始?
因为qinit得不到释放。(为什么?????)
4.3 为什么不从q075和q100开始?
q075和q100由于内存利用率太高,导致内存分配的成功率大大降低,因此放到最后;
if (q050.allocate(...) || q025.allocate(...) ||
q000.allocate(...) || qInit.allocate(...) ||
q075.allocate(...)) {
return;
}
2.5 PoolArena
PoolArena是上述功能的门面,通过PoolArena提供接口供上层使用,屏蔽底层实现细节。为了减少线程成间的竞争,很自然会提供多个PoolArena。Netty默认会生成2×CPU个PoolArena跟IO线程数一致。然后第一次使用的时候会找一个使用线程最少的PoolArena
private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas) {
if (arenas == null || arenas.length == 0) {
return null;
}
PoolArena<T> minArena = arenas[0];
for (int i = 1; i < arenas.length; i++) {
PoolArena<T> arena = arenas[i];
if (arena.numThreadCaches.get() < minArena.numThreadCaches.get()) {
minArena = arena;
}
}
return minArena;
}
2.6 本地线程存储
虽然提供了多个PoolArena减少线程间的竞争,但是难免还是会存在锁竞争,所以需要利用ThreaLocal进一步优化,把已申请的内存放入到ThreaLocal自然就没有竞争了。大体思路是在ThreadLocal里面放一个PoolThreadCache对象,然后释放的内存都放入到PoolThreadCache里面,下次申请先从PoolThreadCache获取。
但是,如果thread1申请了一块内存,然后传到thread2在线程释放,这个Netty在内存holder对象里面会引用PoolThreadCache,所以还是会释放到thread1里
3. 性能测试
可以写两个简单的测试用例,感受一下Netty内存池带来的效果。
- 申请10000000个HeapBuffer,DirectBuffer,池化的DirectBuffer花的时间, 可以看出池化效果非常明显,而且十分平和
| capacity | HeapBuffer | DirectBuffer | 池化的DirectBuffer |
|---|---|---|---|
| 64Byte | 465 | 13211 | 2059 |
| 256Byte | 946 | 15074 | 2309 |
| 512Byte | 2528 | 19516 | 2188 |
| 1024Byte | 4393 | 21928 | 2044 |
- 启一个DiscardServer,然后发送80G的数据,看下GC次数,效果感人
| 非池化 | 池化 | 池化+COMPOSITE_CUMULATOR |
|---|---|---|
| 208 | 27 | 0 |
















 525
525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









