







1. 缓冲IO
在介绍缓冲IO之前需要先了解一下常用的机械硬盘的原理与特点:
一个机械硬盘中装有多个盘片,每个盘片上有多个同心圆(磁道),每个同心圆又由多个弧(扇区)组成,每个弧上都记录了等量的数据(比方说512byte)
如果发起一个随机读写请求,磁头需要先找到对应的磁道,然后等待对应的扇区旋转到磁头正下方才能开始读取数据(民用机械硬盘的转速一般在5400或者7200RPM,工业界倒是经常使用10000RPM的机械硬盘。但是它们的寻道时间大概都在几ms到十几ms左右)
机械硬盘的顺序读写很快(一般在100-200MB/s),但是随机读写很慢(寻道时间在十几ms,导致随机读写的iops只有几十)
假定我们不做任何额外的优化处理,在用户发起读数据请求的时候,直接调用硬盘驱动读取磁盘数据并返回
设想一个场景:循环调用read方法读取文件,但是每次只读取较少的数据(比方说每次只读一个byte)。那么每次read请求都对应于一次对磁盘的随机读写(两次读请求之前需要重新寻道),也就是说read操作的tps只有几十。
也就是说此时磁盘占用率为100%,但是只能提供不到100byte/s的数据读取率,这显然是不可接受的。
Linux对此有个很简单的优化,就是在内核中维护一块缓冲区(buffer cache),在用户第一次调用read读取数据的时候,无论用户想要读取的数据有多小,都会一次性从磁盘中加载一段数据放到缓冲区中,这样用户下一次调用read方法的时候可以直接从缓冲区中返回数据,不用再次访问磁盘了。
write方法也是同理,用户写入的数据不是直接落盘,而是先写到kernel中的缓冲区里,按照一定的策略批量刷盘。当然也可以调用flush方法强制将缓存区的数据落盘。
这个优化极大的提高了顺序读写的效率。由于直接读写的是kernel中的缓冲区而不是磁盘,这种IO被称为缓冲IO。
2. 直接IO
一般来说,上面介绍的缓冲IO已经足够应付日常需求了。但是像数据库这种极度依赖IO的应用程序,为了追求极致的性能,往往更加愿意自己直接操作磁盘。
直接IO可以直接将数据从磁盘复制到用户空间,或者将数据从用户空间写到磁盘,减少了kernel中的缓冲区这一环节,这是直接IO可以提高性能的原理。
但是如果用得不好就悲剧了,所以直接IO只在少数场景下使用。
3. 内存映射mmap
前提概念
虚拟内存系统通过将虚拟内存分割为称作虚拟页(Virtual Page,VP)大小固定的块,一般情况下,每个虚拟页的大小默认是4096字节。同样的,物理内存也被分割为物理页(Physical Page,PP),也为4096字节。
3.1 基本概念
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。如下图所示:
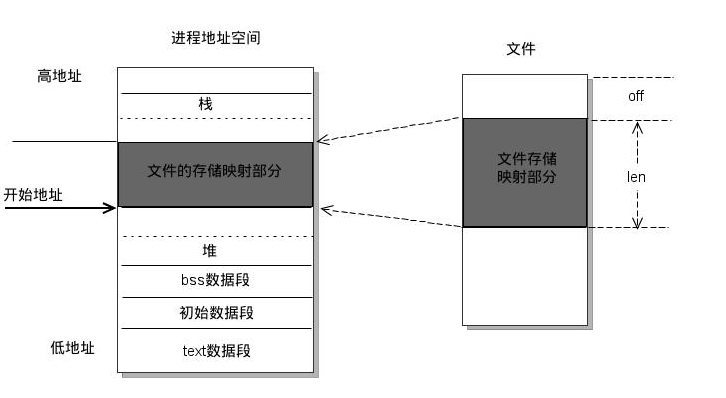
由上图可以看出,进程的虚拟地址空间,由多个虚拟内存区域构成。虚拟内存区域是进程的虚拟地址空间中的一个同质区间,即具有同样特性的连续地址范围。上图中所示的text数据段(代码段)、初始数据段、BSS数据段、堆、栈和内存映射,都是一个独立的虚拟内存区域。而为内存映射服务的地址空间处在堆栈之间的空余部分。
linux内核使用vm_area_struct结构来表示一个独立的虚拟内存区域,由于每个不同质的虚拟内存区域功能和内部机制都不同,因此一个进程使用多个vm_area_struct结构来分别表示不同类型的虚拟内存区域。各个vm_area_struct结构使用链表或者树形结构链接,方便进程快速访问,如下图所示:
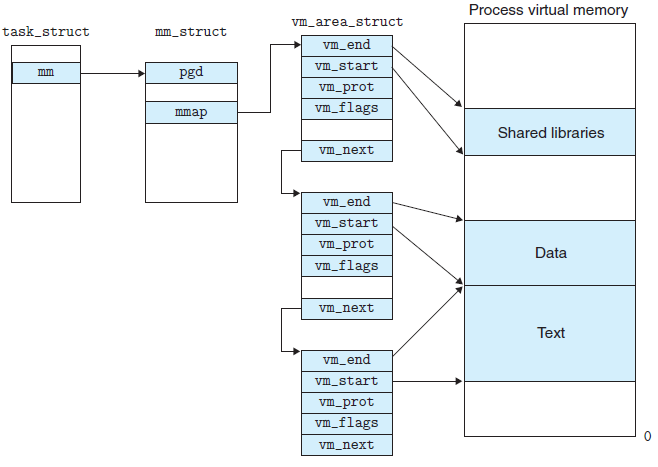
vm_area_struct结构中包含区域起始和终止地址以及其他相关信息,同时也包含一个vm_ops指针,其内部可引出所有针对这个区域可以使用的系统调用函数。这样,进程对某一虚拟内存区域的任何操作需要用要的信息,都可以从vm_area_struct中获得。mmap函数就是要创建一个新的vm_area_struct结构,并将其与文件的物理磁盘地址相连。具体步骤请看下一节。
3.2 mmap内存映射原理
mmap内存映射的实现过程,总的来说可以分为三个阶段:
(一)进程启动映射过程,并在虚拟地址空间中为映射创建虚拟映射区域
- 进程在用户空间调用库函数mmap,原型:void *mmap(void *start, size_t length, int prot, int flags, int fd, off_t offset);
- 在当前进程的虚拟地址空间中,寻找一段空闲的满足要求的连续的虚拟地址
- 为此虚拟区分配一个vm_area_struct结构,接着对这个结构的各个域进行了初始化
- 将新建的虚拟区结构(vm_area_struct)插入进程的虚拟地址区域链表或树中
(二)调用内核空间的系统调用函数mmap(不同于用户空间函数),实现文件物理地址和进程虚拟地址的一一映射关系
- 为映射分配了新的虚拟地址区域后,通过待映射的文件指针,在文件描述符表中找到对应的文件描述符,通过文件描述符,链接到内核“已打开文件集”中该文件的文件结构体(struct file),每个文件结构体维护着和这个已打开文件相关各项信息。
- 通过该文件的文件结构体,链接到file_operations模块,调用内核函数mmap,其原型为:int mmap(struct file *filp, struct vm_area_struct *vma),不同于用户空间库函数。
- 内核mmap函数通过虚拟文件系统inode模块定位到文件磁盘物理地址。
- 通过remap_pfn_range函数建立页表,即实现了文件地址和虚拟地址区域的映射关系。此时,这片虚拟地址并没有任何数据关联到主存中。
(三)进程发起对这片映射空间的访问,引发缺页异常,实现文件内容到物理内存(主存)的拷贝
注:前两个阶段仅在于创建虚拟区间并完成地址映射,但是并没有将任何文件数据的拷贝至主存。真正的文件读取是当进程发起读或写操作时。
- 进程的读或写操作访问虚拟地址空间这一段映射地址,通过查询页表,发现这一段地址并不在物理页面上。因为目前只建立了地址映射,真正的硬盘数据还没有拷贝到内存中,因此引发缺页异常。
- 缺页异常进行一系列判断,确定无非法操作后,内核发起请求调页过程。
- 调页过程先在交换缓存空间(swap cache)中寻找需要访问的内存页,如果没有则调用nopage函数把所缺的页从磁盘装入到主存中。
- 之后进程即可对这片主存进行读或者写的操作,如果写操作改变了其内容,一定时间后系统会自动回写脏页面到对应磁盘地址,也即完成了写入到文件的过程。
注:修改过的脏页面并不会立即更新回文件中,而是有一段时间的延迟,可以调用msync()来强制同步, 这样所写的内容就能立即保存到文件里了。
3.3 mmap映射关系
映射关系可以分为两种
- 文件映射:磁盘文件映射进程的虚拟地址空间,使用文件内容初始化物理内存。
- 匿名映射:初始化全为0的内存空间。
而对于映射关系是否共享又分为
- 私有映射(MAP_PRIVATE):多进程间数据共享,修改不反应到磁盘实际文件,是一个copy-on-write(写时复制)的映射方式。
- 共享映射(MAP_SHARED):多进程间数据共享,修改反应到磁盘实际文件中。
因此总结起来有4种组合
- 私有文件映射:多个进程使用同样的物理内存页进行初始化,但是各个进程对内存文件的修改不会共享,也不会反应到物理文件中
- 私有匿名映射:mmap会创建一个新的映射,各个进程不共享,这种使用主要用于分配内存(malloc分配大内存会调用mmap)。例如开辟新进程时,会为每个进程分配虚拟的地址空间,这些虚拟地址映射的物理内存空间各个进程间读的时候共享,写的时候会copy-on-write。
- 共享文件映射:多个进程通过虚拟内存技术共享同样的物理内存空间,对内存文件 的修改会反应到实际物理文件中,他也是进程间通信(IPC)的一种机制。
- 共享匿名映射:这种机制在进行fork的时候不会采用写时复制,父子进程完全共享同样的物理内存页,这也就实现了父子进程通信(IPC).
这里值得注意的是,mmap只是在虚拟内存分配了地址空间,只有在第一次访问虚拟内存的时候才分配物理内存。
在mmap之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时,通过查找页表,发现虚拟内存对应的页没有在物理内存中缓存,则产生"缺页",由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多。
3.4 mmap在write和read时会发生什么
1.write
- 1.进程(用户态)将需要写入的数据直接copy到对应的mmap地址(内存copy)
- 2.若mmap地址未对应物理内存,则产生缺页异常,由内核处理
- 3.若已对应,则直接copy到对应的物理内存
- 4.由操作系统调用,将脏页回写到磁盘(通常是异步的)
因为物理内存是有限的,mmap在写入数据超过物理内存时,操作系统会进行页置换,根据淘汰算法,将需要淘汰的页置换成所需的新页,所以mmap对应的内存是可以被淘汰的(若内存页是"脏"的,则操作系统会先将数据回写磁盘再淘汰)。这样,就算mmap的数据远大于物理内存,操作系统也能很好地处理,不会产生功能上的问题。
2.read
读的过程对比

从图中可以看出,mmap要比普通的read系统调用少了一次copy的过程。因为read调用,进程是无法直接访问kernel space的,所以在read系统调用返回前,内核需要将数据从内核复制到进程指定的buffer。但mmap之后,进程可以直接访问mmap的数据(page cache)。
3.5 性能优势
为什么说内存映射效率比缓冲IO要高?
我们回忆一下缓冲IO的工作流程:
- 用户调用read方法
- 调用系统调用,触发中断,进程从用户态进入内核态
- 从硬盘中读取数据并复制到kernel缓冲区
- 将数据从kernel缓存区复制到用户提供的byte数组中
- 进程从内核态返回到用户态
从上面的流程中我们可以看到,调用一次read方法,最多可能会引起两次用户态与内核态之间的切换,以及两次数据复制
而内存映射呢?
- 用户试图访问ptr指向的数据
- MMU解析失败,触发缺页中断,程序从用户态进入到内核态
- 从硬盘中读取数据并复制到进程空间中ptr指向的逻辑空间里
- 进程从内核态返回到用户态
可以看出,试图访问内存映射文件,最多可能会引起两次用户态与内核态之间的切换,以及一次数据复制。也就是说,内存映射与缓冲IO相比,可以节省数据复制带来的开销,因此效率较高。
优点如下:
- 对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,用内存读写取代I/O读写,提高了文件读取效率。
- 实现了用户空间和内核空间的高效交互方式。两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
- 提供进程间共享内存及相互通信的方式。不管是父子进程还是无亲缘关系的进程,都可以将自身用户空间映射到同一个文件或匿名映射到同一片区域。从而通过各自对映射区域的改动,达到进程间通信和进程间共享的目的。同时,如果进程A和进程B都映射了区域C,当A第一次读取C时通过缺页从磁盘复制文件页到内存中;但当B再读C的相同页面时,虽然也会产生缺页异常,但是不再需要从磁盘中复制文件过来,而可直接使用已经保存在内存中的文件数据。
- 可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助硬盘空间协助操作,补充内存的不足。但是进一步会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
缺点如下:
- 文件如果很小,是小于4096字节的,比如10字节,由于内存的最小粒度是页,而进程虚拟地址空间和内存的映射也是以页为单位。虽然被映射的文件只有10字节,但是对应到进程虚拟地址区域的大小需要满足整页大小,因此mmap函数执行后,实际映射到虚拟内存区域的是4096个字节,11~4096的字节部分用零填充。因此如果连续mmap小文件,会浪费内存空间。
- 对变长文件不适合,文件无法完成拓展,因为mmap到内存的时候,你所能够操作的范围就确定了。
- 如果更新文件的操作很多,会触发大量的脏页回写及由此引发的随机IO上。所以在随机写很多的情况下,mmap方式在效率上不一定会比带缓冲区的一般写快。
















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









