






项目源码地址:
https://gitee.com/feiniao33/esp32_-ai_-talk
一、百度语音api使用
创建语音服务应用这里不多赘述,网络资源丰富一搜就有。
语音api使用参考官方文档:
https://ai.baidu.com/ai-doc/SPEECH/Tl9mh38eu
重点参考语音合成,识别。
二、ESP32S3分区表自定义
为何需要?音频文件空间开销极大,再算上base64编码,难以malloc如此大的空间。
所以在分区表自定义一块空间,存储音频文件。ESPIDF提供了便捷的分区表创建方法,可参考:
我的分区表:
# Name, Type, SubType, Offset, Size, Flags
# Note: if you have increased the bootloader size, make sure to update the offsets to avoid overlap
nvs, data, nvs, , 0x6000,
phy_init, data, phy, , 0x1000,
factory, app, factory, , 2M,
storage, data, spiffs, , 1M,注意最后一行,将是录音存储的关键。涉及使用SPI Flash File System。
三、PSRAM启用
为何启用?包括cJSON在内,在高强度的语音任务下,malloc大空间百分之百会失败,因为系统剩的堆空间就那点,8000hz下,2s的语音就占九十多k, 加上内存碎片化,你根本malloc不到如此大的空间做编码,做cJSON, 更何况你还有其他众多变量用了空间。所以,
PSRAM是一个极好的选择。
它是什么:
PSRAM(伪静态随机存储器)是一种结合了 DRAM(动态RAM)和 SRAM(静态RAM)特性的混合型存储器。
ESPIDF框架下,通过heap_caps_malloc就可分配超大内存空间。
具体配置参考:
关于esp32在espidf的psram启用_esp32 psram-CSDN博客
四、STT
一)录音
创建/打开文件->写入音频数据->关闭文件
创建/打开文件:
显然创建的文件应该位于我们分区表的storage区,Subtype是spiffs, 所以文件路径可以是:
/spiffs/audio.pcmaudio.pcm是该音频文件,百度语音支持pcm, wav等类型,时间关系,首选pcm, 因为方便,只需将音频数据写入就行。
为何不是:
storage/spiffs/audio.pcm因为在ESPIDF, 初始化spiffs, 过程如下:
void Recorder::format_spiffs() {
// 卸载 SPIFFS(必须先卸载才能格式化)
esp_vfs_spiffs_unregister("storage");
// 格式化 SPIFFS 分区
esp_err_t ret = esp_spiffs_format("storage");
if (ret != ESP_OK) {
ESP_LOGE(TAG, "SPIFFS 格式化失败: %s", esp_err_to_name(ret));
return;
}
ESP_LOGI(TAG, "SPIFFS 格式化完成,所有数据已清空");
// 挂载 SPIFFS
init_spiffs(); // 调用你原来的挂载函数
}所以在初始化的时候,已经选择了storage分区,无需再加storage/。
现在就能用C语言标准输入输出库创建打开文件:
char full_path[64];
snprintf(full_path, sizeof(full_path), "%s", PCM_FILE_NAME);
FILE* f = fopen(full_path, "wb");
if (!f) {
ESP_LOGE(TAG, "[FILE] PCM文件打开失败!");
return 0;
}所以文件的创建,前提是要初始化SPIFFS。
音频数据写入:
打开文件后,调用fwrite函数就可以将音频写入文件了。
所以接下来要做的是将音频数据get到:
本案例使用INMP441麦克风,采用I2S协议传输数据。利用ESPIDF的I2S接口可快速配置音频接收模式:(示例)
BSP_I2S::BSP_I2S(int bck_io_num, int ws_io_num, int data_in_num, int data_out_num, uint32_t sample_rate, i2s_port_t i2s_port, i2s_mode_t i2s_mode, i2s_bits_per_sample_t bits_per_sample)
: bck_io_num(bck_io_num), ws_io_num(ws_io_num), data_in_num(data_in_num), data_out_num(data_out_num), sample_rate(sample_rate), i2s_port(i2s_port), i2s_mode(i2s_mode), bits_per_sample(bits_per_sample)
{
i2s_config_t i2s_config = {
.mode = i2s_mode,
.sample_rate = sample_rate,
.bits_per_sample = bits_per_sample,
.channel_format = I2S_CHANNEL_FMT_ONLY_LEFT,
.communication_format = I2S_COMM_FORMAT_STAND_I2S,
.intr_alloc_flags = ESP_INTR_FLAG_LEVEL1, // default interrupt priority
.dma_buf_count = 4, // number of buffers
.dma_buf_len = 1024, // size of each buffer in bytes
.use_apll = false
};
i2s_pin_config_t pin_config = {
.bck_io_num = bck_io_num,
.ws_io_num = ws_io_num,
.data_out_num = data_out_num,
.data_in_num = data_in_num
};
i2s_driver_install(i2s_port, &i2s_config, 0, NULL);
i2s_set_pin(i2s_port, &pin_config);
}INMP441输出的是24位音频数据,容易想到存储用u32类型,再通过右移,然后修正符号位得到正确数据,实际上,本案例直接读取16位数据,并用int16类型接收,也能正常使用(包括后续stt),这是一个秘点。
int16_t BSP_I2S::int16t_read() {
int16_t data;
size_t bytes_read;
i2s_read(i2s_port, &data, sizeof(int16_t), &bytes_read, portMAX_DELAY);
return data;
}案例配置:
Recorder::Recorder(): recorder(INMP441_BCLK_PIN, INMP441_WS_PIN, INMP441_SD_PIN, -1, SAMPLE_RATE, Microphone_I2S_Port, (i2s_mode_t)(I2S_MODE_MASTER | I2S_MODE_RX), I2S_BITS_PER_SAMPLE_16BIT)
{
}其次是决定录音时长,时长定了,文件写什么时候停才定:
假设录音x秒, 那么要写进去的数据总大小是:
x * 采样率 * 数据类型大小,所以数据写入过程如下:
const size_t target_size = seconds * SAMPLE_RATE * sizeof(int16_t);
size_t bytes_written = 0;
ESP_LOGI(TAG, "开始录音");
while (bytes_written < target_size) {
int16_t sample = recorder.int16t_read();
size_t written = fwrite(&sample, sizeof(int16_t), 1, f);
if (written != 1) {
ESP_LOGE(TAG, "写入文件失败");
break;
}
bytes_written += written * sizeof(int16_t);
}
ESP_LOGI(TAG, "录音完成,写入数据: %zu 字节", bytes_written);最后关闭文件即可,不多演示。
二)STT
即语音转文字。
这是一个繁琐的步骤,但依然可以拆分成多个阶段,逐步实现:
读取音频文件->进行base64编码->json请求构造->发送请求->结果处理
为何需要base64?百度语音平台要求:

读取音频文件:
int16_t* buffer = (int16_t*)heap_caps_malloc(sample_num * sizeof(int16_t),
MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT); // 在PSRAM中分配内存
if (!buffer) {
ESP_LOGE(TAG, "读取音频文件内存分配失败!");
return;
}
ESP_LOGI(TAG, "读取音频文件内存分配成功!");
recorder.read_pcm_file_int16t(buffer); // 读取PCM文件sample_num是采样数,即 bytes_written / sizeof(int16_t); 即音频录制过程最终可返回一个采样数,或者更简单,直接返回bytes_written。
MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT 表示 从外部PSRAM分配8位对齐的内存
8位对齐是最宽松的对齐方式,适用于通用数据缓冲区。
若未明确对齐要求,某些操作(如直接内存访问DMA)可能失败。
base64编码:
首先需要知道base64编码我们音频数据之后的长度,
size_t base64_len = 0;
int ret = mbedtls_base64_encode(NULL, 0, &base64_len, (const unsigned char*)buffer, sample_num * sizeof(int16_t));
if (ret != 0 && ret != MBEDTLS_ERR_BASE64_BUFFER_TOO_SMALL) {
ESP_LOGE(TAG, "Base64长度计算失败: 错误码 %d", ret);
return;
}
ESP_LOGI(TAG, "Base64编码长度: %d", base64_len);通过ESPIDF提供的"mbedtls/base64.h",可调用mbedtls_base64_encode进行base64编码,并且有长度输出,所以这是计算长度的一种方法。
另外一种是公式法:

根据公式,实际代码应为:
size_t input_len = sample_num * sizeof(int16_t); // 原始数据长度(字节)
size_t base64_len = 4 * ((input_len + 2) / 3); // Base64编码后长度为何:input_len + 2?

对比示例:

所以+2是为了使/3的结果向上取整,确保计算正确。
有了长度,可以进行实际编码了:
先分配计算出的编码后长度大小的空间,再使用mbedtls_base64_encode进行base64编码,最后加上终止符。
// 分配内存以存储base64编码
unsigned char* base64_buffer = (unsigned char*)heap_caps_malloc(base64_len, MALLOC_CAP_SPIRAM | MALLOC_CAP_8BIT);
if (!base64_buffer) {
ESP_LOGE(TAG, "Base64内存分配失败!");
heap_caps_free(buffer);
return;
}
ESP_LOGI(TAG, "Base64内存分配成功!");
// 执行base64编码
ret = mbedtls_base64_encode(base64_buffer, base64_len, &base64_len, (const unsigned char*)buffer, sample_num * sizeof(int16_t));
if (ret != 0) {
ESP_LOGE(TAG, "Base64编码失败: 错误码 %d", ret);
heap_caps_free(buffer);
heap_caps_free(base64_buffer);
return;
}
// 添加终止符
base64_buffer[base64_len] = '\0'; // 添加终止符
// 打印base64编码长度
ESP_LOGI(TAG, "Base64编码长度: %d", base64_len + 1); // 包含终止符json请求构造:
根据官方文档:
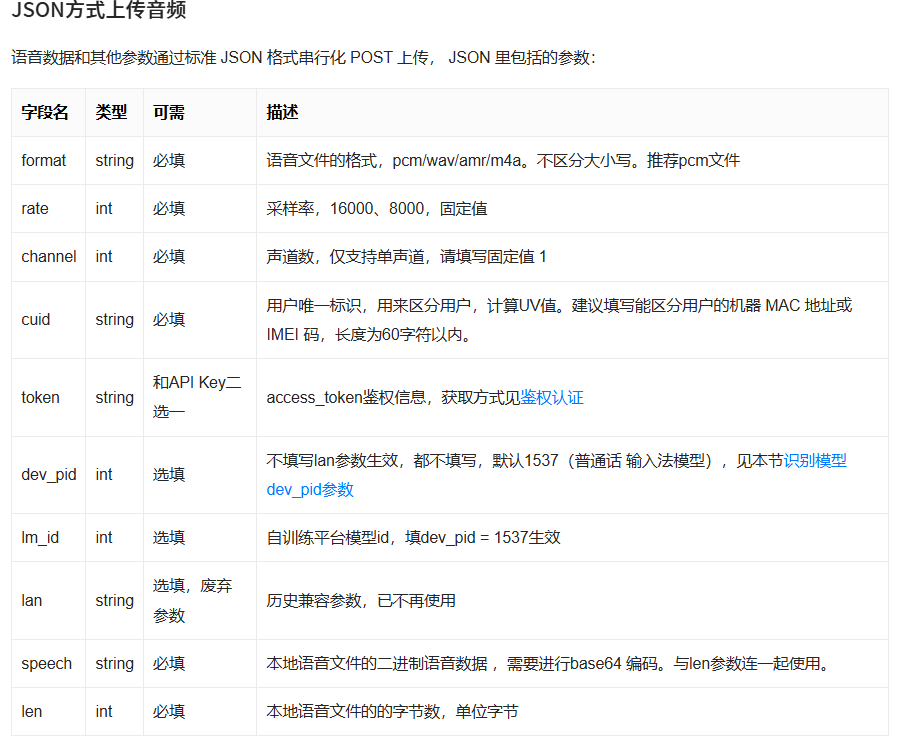
官方示例:
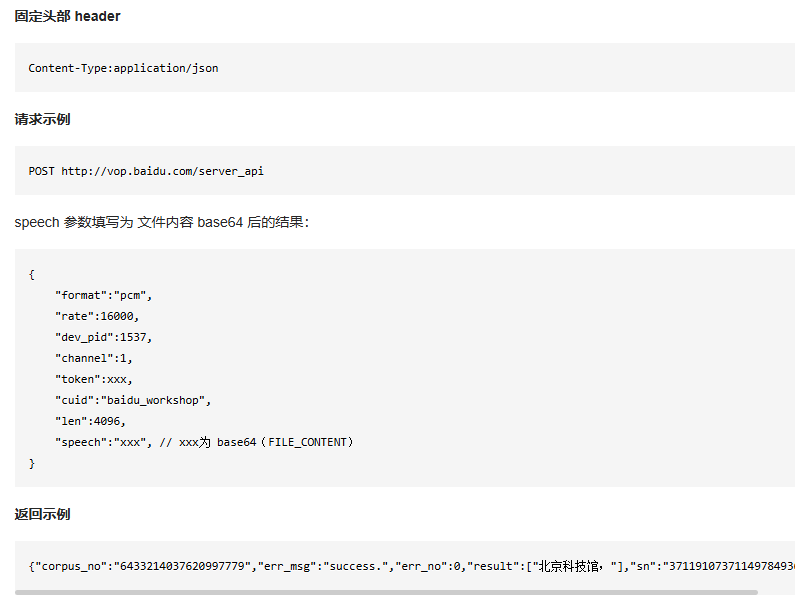
所以利用cJSON, 如下构造请求:
// JSON请求构造
cJSON* json = cJSON_CreateObject();
if (!json) {
ESP_LOGE(TAG, "创建JSON对象失败!");
heap_caps_free(base64_buffer);
return;
}
fetch_token_stt(); // 获取token
cJSON_AddStringToObject(json, "dev_pid", "1537"); // 普通话输入模型
cJSON_AddStringToObject(json, "format", "pcm");
cJSON_AddNumberToObject(json, "rate", SAMPLE_RATE);
cJSON_AddNumberToObject(json, "channel", 1);
cJSON_AddStringToObject(json, "token", token); // 使用 token
cJSON_AddStringToObject(json, "cuid", CUID);
cJSON_AddNumberToObject(json, "len", sample_num * sizeof(int16_t)); // pcm文件的字节数
if (cJSON_AddStringToObject(json, "speech", (const char*)base64_buffer) == NULL) {
ESP_LOGE(TAG, "添加音频数据失败!");
cJSON_Delete(json);
heap_caps_free(base64_buffer);
return;
}
char* json_str = cJSON_PrintUnformatted(json);
if (!json_str) {
ESP_LOGE(TAG, "生成JSON字符串失败!");
} else {
ESP_LOGI(TAG, "生成的JSON字符串(前200): %.200s", json_str);
}CUID在百度智能云,自己创建的应用处获取,不多赘述。值得注意的是,len是pcm文件的大小,而非base64编码后大小
也注意到,需要获取token,阅读官方的文档:
https://ai.baidu.com/ai-doc/SPEECH/cm8sn2bii
所以就是使用POST方式向token获取地址发送请求即可,并包含API_KEY和SECRET_KEY,
具体到代码,就是:
void STT::fetch_token_stt() {
ESP_LOGI(TAG, "开始获取token...");
esp_http_client_config_t config = {
.url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" STT_API_KEY "&client_secret=" STT_SECRET_KEY,
.cert_pem = my_stt_cert_pem_start,
.method = HTTP_METHOD_POST,
.timeout_ms = 10000,
.event_handler = fetch_token_event_handler,
};
esp_http_client_handle_t client = esp_http_client_init(&config);
esp_http_client_set_header(client, "Content-Type", "application/x-www-form-urlencoded");
esp_http_client_set_header(client, "Content-Length", "0");
esp_err_t err = esp_http_client_perform(client);
if (err == ESP_OK) {
int status_code = esp_http_client_get_status_code(client);
ESP_LOGI(TAG, "status_code: %d", status_code);
} else {
ESP_LOGE(TAG, "HTTP请求失败: %s", esp_err_to_name(err));
}
// 确保每次请求后释放资源
esp_http_client_cleanup(client);
}看起来比较繁琐,ESPIDF提供的https,使用起来必须附带cert_pem,获取过程较为繁琐,参考文章:
关于ESPIDF框架下的https使用_esp根证书-CSDN博客
回到请求构造,我们已经构建好了请求,接下来:
发送请求:
根据官方文档,https://ai.baidu.com/ai-doc/SPEECH/Jlbxdezuf
同样是post的方式上传请求。
如何发送?关于ESPIDF框架下的https使用_esp根证书-CSDN博客
也有提及,这里不多赘述。
示例代码:
// // 配置 HTTP 客户端
esp_http_client_config_t config = {
.url = API_URL_STT,
.cert_pem = my_stt_cert_pem_start,
.method = HTTP_METHOD_POST,
.timeout_ms = 100000,
.event_handler = stt_event_handler,
};
// 设置HTTP客户端
esp_http_client_handle_t client = esp_http_client_init(&config);
esp_http_client_set_header(client, "Accept", "application/json");
// 设置post数据
esp_http_client_set_post_field(client, json_str, strlen(json_str));
// 发送请求
esp_err_t err = esp_http_client_perform(client);
if (err != ESP_OK) {
ESP_LOGE(TAG, "HTTP 请求失败: %s", esp_err_to_name(err));
}
// 检查响应码
int status_code = esp_http_client_get_status_code(client);
if (status_code != 200) {
ESP_LOGE(TAG, "HTTP Error: %d", status_code);
}响应处理我们在event_handler 中处理,这是ESPIDFhttps的事件回调函数。
结果处理:
显然如果响应成功会返回结果文字,为后续LLM(大语言模型)对话使用,所以这里的设计是多样的,但在基于ESPIDF框架下提供的freertos,消息队列是一个不错的选择。
ESPIDF遵循严格的事件回调,对于http的事件,如下:
typedef enum {
HTTP_EVENT_ERROR = 0, /*!< This event occurs when there are any errors during execution */
HTTP_EVENT_ON_CONNECTED, /*!< Once the HTTP has been connected to the server, no data exchange has been performed */
HTTP_EVENT_HEADERS_SENT, /*!< After sending all the headers to the server */
HTTP_EVENT_HEADER_SENT = HTTP_EVENT_HEADERS_SENT, /*!< This header has been kept for backward compatibility
and will be deprecated in future versions esp-idf */
HTTP_EVENT_ON_HEADER, /*!< Occurs when receiving each header sent from the server */
HTTP_EVENT_ON_DATA, /*!< Occurs when receiving data from the server, possibly multiple portions of the packet */
HTTP_EVENT_ON_FINISH, /*!< Occurs when finish a HTTP session */
HTTP_EVENT_DISCONNECTED, /*!< The connection has been disconnected */
HTTP_EVENT_REDIRECT, /*!< Intercepting HTTP redirects to handle them manually */
} esp_http_client_event_id_t;显然,switch case语句为我们提供了便捷。每个case对于一个事件,但对于我们简单处理结果,无需将所有事件用到。这里我们只关注HTTP_EVENT_ON_DATA, HTTP_EVENT_ON_FINISH。即可完整处理响应。
当HTTP_EVENT_ON_DATA, 我们累计数据到缓冲区,当HTTP_EVENT_ON_FINISH,我们开始解析对应的响应,提取文字结果,往队列里面放。
所以以下是一份demo:
static esp_err_t stt_event_handler(esp_http_client_event_t *evt) {
static char response_buffer[MAX_RESPONSE_LEN]; // 静态缓冲区存储响应
static size_t response_len = 0; // 当前数据长度
switch (evt->event_id) {
case HTTP_EVENT_ON_DATA: {
// 累积数据到缓冲区
if (response_len < MAX_RESPONSE_LEN - 1) {
size_t to_copy = MIN(evt->data_len, MAX_RESPONSE_LEN - response_len - 1);
memcpy(response_buffer + response_len, evt->data, to_copy);
response_len += to_copy;
}
break;
}
case HTTP_EVENT_ON_FINISH: {
ESP_LOGI(TAG, "Response: %s", response_buffer);
// 确保字符串以结束符结尾
response_buffer[response_len] = '\0';
// 解析 JSON 响应
cJSON *response_json = cJSON_Parse(response_buffer);
if (response_json) {
cJSON *result = cJSON_GetObjectItem(response_json, "result");
if (result && cJSON_IsArray(result)) {
cJSON *first_result = cJSON_GetArrayItem(result, 0);
if (cJSON_IsString(first_result)) {
ESP_LOGI(TAG, "识别结果: %s", first_result->valuestring);
char* text_copy = strdup(first_result->valuestring); // 复制字符串
if (xQueueSend(stt_output_queue, &text_copy, pdMS_TO_TICKS(100)) != pdTRUE) {
free(text_copy); // 发送失败时释放
ESP_LOGE(TAG, "Queue full");
}
}
} else {
cJSON *error = cJSON_GetObjectItem(response_json, "err_msg");
ESP_LOGE(TAG, "识别失败: %s", error ? error->valuestring : "Unknown error");
}
cJSON_Delete(response_json);
} else {
ESP_LOGE(TAG, "JSON解析失败");
}
// 重置缓冲区
response_len = 0;
break;
}
case HTTP_EVENT_DISCONNECTED:
response_len = 0; // 重置以应对重连
break;
default:
break;
}
return ESP_OK;
}五、LLM
大语言模型。这一步就是将语音识别结果喂给大模型,大模型输出的回复再返回过来,扔给TTS(文字转语音)。
这里方法极多,可以选择现成的api, 也可以自己搭建服务器,本案例使用后者。
本案例使用的ollama下的deepseek v2 16b模型, 如何安装与配置这里不赘述,deepseek热度非常高,ollama下的配置教学非常多,自行搜索。
一)Django搭建
为何使用django? 当然完全可以不使用django, 完全可以使用flask等更轻量的服务。只是本案例服务端是基于django。
资源众多,随便点一篇
Python Web开发(二):Django的安装和运行_django安装-CSDN博客
二)Django api 编写
在views.py,编写响应逻辑:
简单来说,要处理的事情就是提取出MCU发给我们的文字,然后喂给大模型,将大模型结果返回给MCU
利用ollama,可快速实现这个过程:
@require_http_methods(["POST"])
def my_local_deepseek(request):
if request.method == 'POST':
try:
data = json.loads(request.body)
user_input = data.get("user_input")
# 直接获取响应内容
response = generate('deepseek-v2:16b', str(user_input) + "(回答二十个字以内, 且以可爱少女的口吻)")
result_text = response['response']
print(result_text)
return JsonResponse({"result": [result_text]},
status=200,
json_dumps_params={"ensure_ascii": False} # 禁用转义
)
except json.JSONDecodeError:
return JsonResponse({"error": "Invalid JSON"}, status=400)
except Exception as e:
return JsonResponse({"error": str(e)}, status=500)对于如何解析MCU输入,取决于MCU那边如何构造的请求。
设置路径:
在urls.py:
增加:
path('api/my_local_deepseek/', views.my_local_deepseek),第一个参数是路径名,第二个是对应的响应函数。
增加主机:
在settings.py, 按需增加域名。为何?由于MCU位于不同于电脑主机的网络,两者无法通讯,有多种方法这里:
1)ESP32连接手机热点,电脑也连接手机热点,这样,就不用增加域名,ESP32那边访问192.168.x.x下的接口(具体ip地址可通过windows 的 cmd , 输入ipconfig查看)
2)将电脑主机映射到共有域名,如使用内网穿透工具。可参考:
花生壳设置指南:映射HTTP服务实现API外网访问-CSDN博客
教程非常多。这样的话,就需要增加你的映射域名在settings.py的 ALLOWED_HOSTS列表。
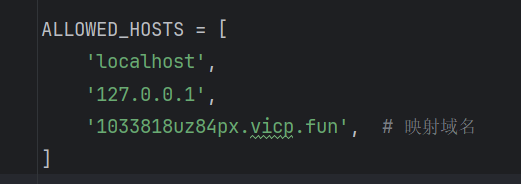
三)MCU端过程
数据的接收
之前说到stt的结果已经通过消息队列传输,所以先做数据的接收:
char* stt_text = nullptr;
if (xQueueReceive(stt_output_queue, &stt_text, portMAX_DELAY) != pdTRUE) {
ESP_LOGE(TAG, "Failed to receive data from stt_output_queue");
return;
}
if (stt_text == nullptr || strlen(stt_text) == 0) {
ESP_LOGE(TAG, "Received empty text from llm_output_queue");
free(stt_text); // 确保释放可能分配的内存
return;
}
ESP_LOGI(TAG, "stt_output_queue: %s", stt_text);接下来构造与我们服务端约定的json,
cJSON *messages = cJSON_CreateObject();
cJSON_AddStringToObject(messages, "user_input", stt_text);
char* payload = cJSON_PrintUnformatted(messages);
ESP_LOGI(TAG, "payload : %s", payload);发送请求:
同样,https需要证书,如何获取,参考前文教程
esp_http_client_config_t config = {
.url = LLM_API_URL,
.cert_pem = my_django_cert_pem_start,
.method = HTTP_METHOD_POST,
.timeout_ms = 100000,
.event_handler = LLM_event_handler,
};
esp_http_client_handle_t client = esp_http_client_init(&config);
esp_http_client_set_header(client, "Content-Type", "application/json");
esp_http_client_set_post_field(client, payload, strlen(payload));
esp_err_t err = esp_http_client_perform(client);
if (err == ESP_OK) {
ESP_LOGI(TAG, "Status: %d", esp_http_client_get_status_code(client));
}
编写回调函数:
同样两件事,累积消息,使用消息队列发送结果到TTS
static esp_err_t LLM_event_handler(esp_http_client_event_t* evt) {
static char response_buffer[MAX_RESPONSE_LEN]; // 静态缓冲区存储响应
static size_t response_len = 0; // 当前数据长度
switch (evt->event_id)
{
case HTTP_EVENT_ON_DATA: {
// 累积数据到缓冲区
if (response_len < MAX_RESPONSE_LEN - 1) {
size_t to_copy = MIN(evt->data_len, MAX_RESPONSE_LEN - response_len - 1);
memcpy(response_buffer + response_len, evt->data, to_copy);
response_len += to_copy;
}
break;
}
case HTTP_EVENT_ON_FINISH: {
response_buffer[response_len] = '\0';
cJSON *response_json = cJSON_Parse(response_buffer);
if (response_json) {
cJSON *result = cJSON_GetObjectItem(response_json, "result");
if (result && cJSON_IsArray(result)) {
cJSON *first_result = cJSON_GetArrayItem(result, 0);
if (cJSON_IsString(first_result) && first_result->valuestring) {
char* text_copy = strdup(first_result->valuestring);
if (xQueueSend(llm_output_queue, &text_copy, pdMS_TO_TICKS(100)) != pdTRUE) {
free(text_copy);
}
}
}
cJSON_Delete(response_json);
} else {
ESP_LOGE(TAG, "JSON解析失败");
}
response_len = 0;
break;
}
case HTTP_EVENT_DISCONNECTED:
response_len = 0; // 重置以应对重连
break;
default:
break;
}
return ESP_OK;
}六、TTS
同样,四件事情,从队列接收文字消息,请求体构造,然后发送到百度tts api, 然后处理结果
队列接收文字消息:
char* llm_text = nullptr;
if (xQueueReceive(llm_output_queue, &llm_text, portMAX_DELAY) != pdTRUE) {
ESP_LOGE(TAG, "Failed to receive data from llm_output_queue");
return;
}
ESP_LOGI(TAG, "llm_output_queue: %s", llm_text);
// 检查队列数据是否有效
if (llm_text == nullptr || strlen(llm_text) == 0) {
ESP_LOGE(TAG, "Received empty text from llm_output_queue");
free(llm_text); // 确保释放可能分配的内存
return;
}请求体构造:
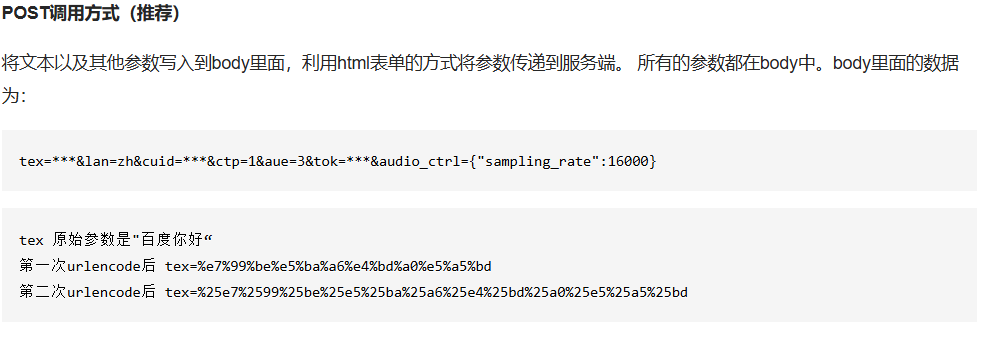
根据官方文档,由于POST方式下请求体是 表单请求体,而非json, 且文字要进行url编码,所以构造如下
// URL编码
char* final_text = url_encode(llm_text);
if (!final_text) {
ESP_LOGE(TAG, "URL encoding failed");
return;
}
// 计算payload需要的空间(保守估计)
size_t payload_size = strlen(final_text) + strlen(baidu_aip_token) + strlen(CUID) + 100;
char* payload = (char*)malloc(payload_size);
if (!payload) {
free(final_text);
ESP_LOGE(TAG, "Payload memory allocation failed");
return;
}
snprintf(payload, payload_size,
"tex=%s&tok=%s&cuid=%s&ctp=1&lan=zh&aue=4&spd=8&per=4103&vol=2",
final_text,
baidu_aip_token,
CUID);编码函数:
char* TTS::url_encode(const char* str) {
const char* hex = "0123456789ABCDEF";
size_t len = strlen(str);
char* encoded = (char* )malloc(len * 3 + 1);
char* p = encoded;
for (size_t i = 0; i < len; i++) {
if (isalnum((unsigned char)str[i]) || str[i] == '-' || str[i] == '_'
|| str[i] == '.' || str[i] == '~') {
*p++ = str[i];
} else {
*p++ = '%';
*p++ = hex[(unsigned char)str[i] >> 4];
*p++ = hex[(unsigned char)str[i] & 0xF];
}
}
*p = '\0';
return encoded;
}发送请求:
同样,证书获取参考前文
// HTTP客户端配置
esp_http_client_config_t config = {
.url = TTS_URL,
.cert_pem = my_tts_cert_pem_start,
.method = HTTP_METHOD_POST,
.timeout_ms = 20000,
.event_handler = tts_event_handler
};
esp_http_client_handle_t client = esp_http_client_init(&config);
esp_http_client_set_header(client, "Content-Type", "application/x-www-form-urlencoded");
esp_http_client_set_post_field(client, payload, strlen(payload));
ESP_LOGI(TAG, "TTS payload: %s", payload);
// 执行请求
esp_err_t err = esp_http_client_perform(client);
if (err == ESP_OK) {
ESP_LOGI(TAG, "TTS Status: %d", esp_http_client_get_status_code(client));
} else {
ESP_LOGE(TAG, "HTTP request failed: %d", err);
}结果处理:
根据官方文档,

audio/basic的出现表明了音频的成功合成,成功的前提下,再播放音频:
esp_err_t TTS::tts_event_handler(esp_http_client_event_t* evt) {
TTS* tts = static_cast<TTS*>(evt->user_data); // 获取实例指针
if (!tts) {
ESP_LOGI(TAG, "failed to reinterpret_cast");
return ESP_FAIL;
}
static bool is_audio_data = false; // 标识是否开始接收音频数据
switch (evt->event_id) {
case HTTP_EVENT_ON_CONNECTED:
ESP_LOGI(TAG, "连接服务器成功");
break;
case HTTP_EVENT_ON_HEADER:
// 识别音频数据开始(根据百度API特性)
if (strcasecmp(evt->header_key, "Content-Type") == 0) {
if (strstr(evt->header_value, "audio/basic") != NULL) { // audio/basic
is_audio_data = true;
ESP_LOGI(TAG, "开始接收PCM数据");
}
}
break;
case HTTP_EVENT_ON_DATA: {
if (!is_audio_data) {
// 打印非音频数据(可能是错误信息)
ESP_LOGW(TAG, "接收非音频数据: %.*s", evt->data_len, (char*)evt->data);
}
if (is_audio_data && evt->data_len > 0) {
tts->L.play(evt->data, evt->data_len);
}
break;
}
case HTTP_EVENT_ON_FINISH: {
ESP_LOGI(TAG, "音频传输完成");
break;
}
case HTTP_EVENT_DISCONNECTED: {
ESP_LOGI(TAG, "连接断开");
is_audio_data = false;
break;
}
default:
break;
}
return ESP_OK;
}
如何播放?
本案例使用max98357a放大器,也是I2S协议。
具体配置,要严格与aue参数对应的一致,如采样率。
当接收到音频数据,调用I2S写即可。
八、连接wifi
略,资源多,十分容易,但这是后续网络任务的必要条件。
九、整合
不难发现,STT, LLM, TTS是串行的,wifi任务是他们三个的前提。所以可以由wifi任务创建他们三个任务,且他们三个任务,同一时间只能有一个任务允许运行。
由于本案例未采用唤醒词出发,只是简单按键触发,所以按键在LLM, TTS时是无效的,简单标志位即可实现。
当然,本案例执行效率不高,数据不是流式传输,等,还有诸多地方需要优化,只是提供了一个基础的demo以运行。
十、测试



测试视频:
https://www.bilibili.com/video/BV1XK3EznEvv?vd_source=70543069472d00af99accfa2a70640cb
















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









