









前段时间为了做人工智能,回家重新恶补了一下C语言,使用的工具Code Blocks 17.12;
明明写好了代码,执行也没问题
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
#include <mmsystem.h>
#pragma comment(lib,"Winmm.lib")
int main()
{
printf("创造世界的日子开始了\n");
printf("Hello world!\n");
//播放音乐
PlaySound(TEXT("sounds\\85702.wav"),NULL,SND_FILENAME / SND_ASYNC / SND_LOOP);
return 0;
}重新打开中文部分就是乱码;
查了资料,显示默认情况下,是保存为windows本地编码的,也就是WINDOWS-936字符集,也就是GBK编码。
但是很神奇的是,GCC编译器默认编译的时候是按照UTF-8解析的。你存成GBK,但是当成UTF-8解析,这还能编译通过,这才有鬼了,所以这两个地方编码不统一好,编译的时候报错:error: converting to execution character set: Illegal byte sequence,你根本连通过编译的可能性都没有!
其实要解决这个问题很简单,编写Code::Blocks的人只需要在调用编译器之前检测一下源文件是什么编码,然后就自动让编译器用什么编码进行解释,问题就解决了。只是很可惜,Code::Blocks编写的人可能还没有这么做,或许是对本地化认识不够吧,也可能是觉得没必要吧?
解决方案:
查看编辑器-编码设置
修改源文件保存编码在:settings->Editor->gernal settings 看到右边的Encoding group Box了吗?如下图所示:
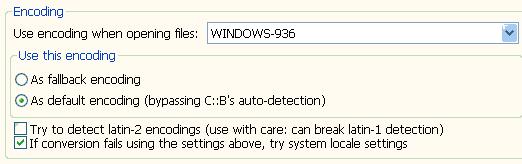
Use encoding when opening files:这个表示打开文件用的格式,第一次保存文件的时候也会用这个格式。
As default encoding:表示设置为文件缺省保存和打开编码格式
注意,要先设置好,然后保存文件,才有效。如果你已经保存了文件,无论你怎么修改这个设置,也不会改变你文件的格式了。你的文件还是保持第一次保存的时候的格式。
所以,如果遇到无法生效,只能先设置好格式,再重新建文件了。















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









