






作者|Ajit Rajasekharan 编译|VK 来源|Towards Data Science

从文档中获取的句子片段的嵌入可以作为该文档的提取摘要方面,并可能加速搜索,特别是当用户输入是一个句子片段时。这些片段嵌入不仅比传统的文本匹配系统产生更高质量的结果,也是问题的内在驱动的搜索方法。现代向量化表示挑战创建有效的文档嵌入,捕捉所有类型的文档,使其通过使用嵌入在文档级别进行搜索。
例如“蝙蝠是冠状病毒的来源”、“穿山甲中的冠状病毒”,由介词、形容词等连接一个或多个名词短语的短序列。这些突出显示的连接词在很大程度上被传统搜索系统忽略,它们不仅可以在捕获用户意图方面发挥关键作用(例如,“蝙蝠中的冠状病毒”不同于“蝙蝠是冠状病毒的来源”或“蝙蝠中不存在冠状病毒”)的搜索意图,但是,保留它们的句子片段也可以是有价值的候选索引,可以用作文档的摘要提取方面(子摘要)。通过将这些句子片段嵌入到适当的嵌入空间(如BERT)中,我们可以使用搜索输入片段作为对该嵌入空间的探测,以发现相关文档。
需要改进使用片段的搜索
找到一个有文献证据支持的综合答案来回答“COVID-19来源什么动物?”或者“冠状病毒与之结合的受体”,即使是在最近发布的covid19数据集这样的小数据集上(约500 MB的语料库大小,约13k文档,8500多万单词,文本中约有100万个不同的单词),也是一个挑战。
传统的文档搜索方法对于通过使用一个或多个名词短语搜索从几个文档中获得答案的典型用例非常有效。传统的文档搜索方法也满足以下对单词和短语的用户体验约束:
我们看到的(结果)是我们输入的(搜索的)
例如,当我们搜索单词和短语(连续的单词序列,如New York,Rio De Janeiro)时,结果通常包含我们输入的词汇或它们的同义词(例如,COVID-19搜索产生Sars-COV-2或新型冠状病毒等结果)。
然而,随着搜索输入的单词数量的增加,搜索结果的质量往往会下降,特别是名词短语之间使用连接词的情况下。即使搜索引擎在结果中会突出显示术语,但是这种结果质量的下降是还是显而易见,
例如,在下图中,当前搜索引擎选择性地突出显示了“蝙蝠作为冠状病毒的来源”(“bats as a source of coronavirus”)中的名词,有时甚至没有遵循输入序列中这些单词的顺序。 尽管文档相关性排序通常可以在很大程度上缓解这种情况,但我们仍然需要检查每个文档的摘要,因为文档不满足我们的搜索意图。
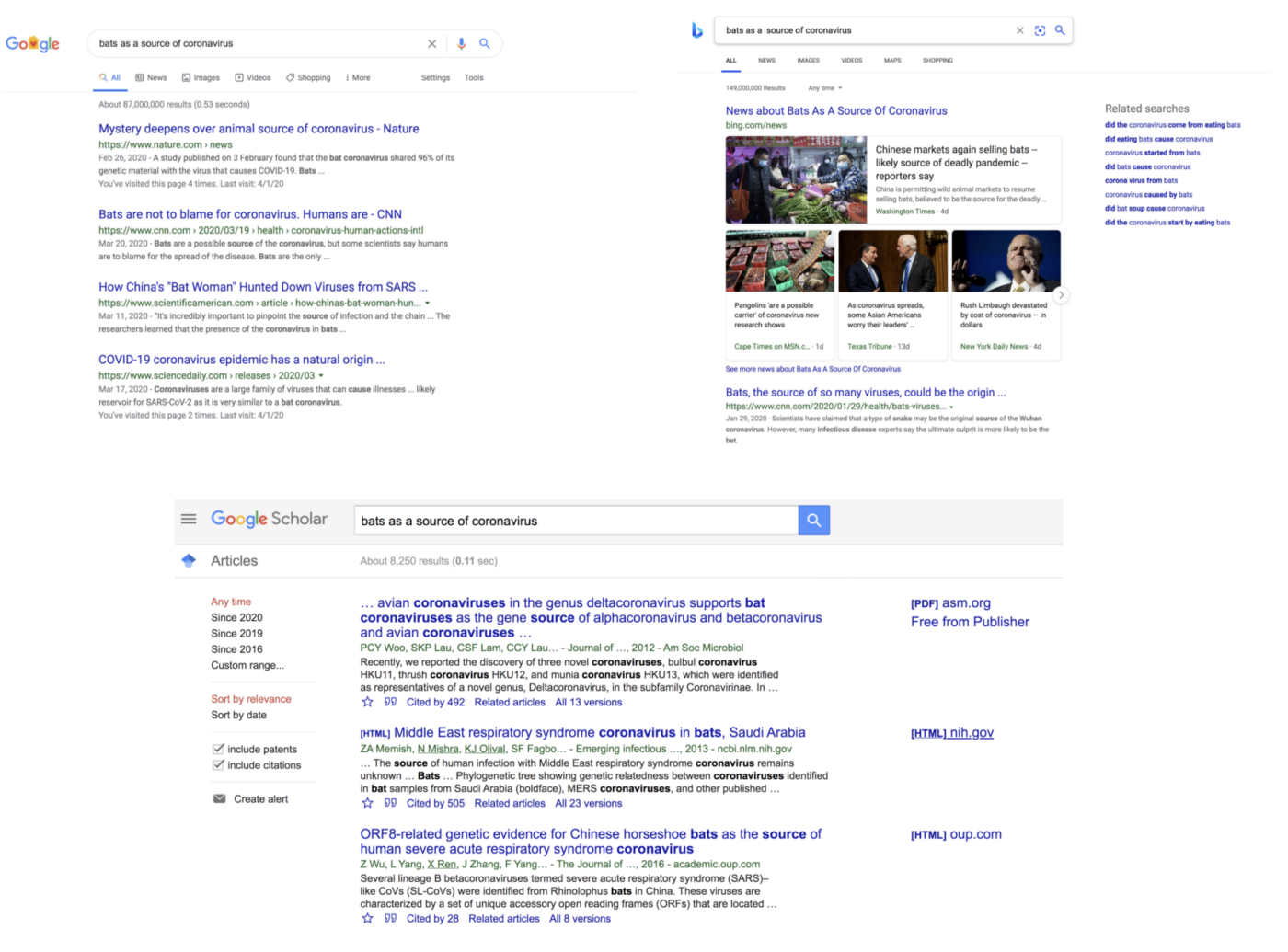
本文所述的文档搜索方法除产生更相关的结果外,还可以减少搜索系统中存在的这种认知负担,尤其是在搜索句子片段时。 作为说明,我们在上面的现有搜索系统中使用的相同查询可以产生如下所示形式的结果(该界面仅是用于说明搜索方法的示意图)。 值得注意的是,以下示意图中的要点是,摘要是文档中的实际匹配项(括号中的数字是包含片段的文档数以及带有输入搜索片段的片段的余弦距离),而不是在传统搜索系统中显示的建议查询或相关搜索查询。 这些摘要方面为结果空间提供了全景视图,减少了无用的文档导航并加快了对感兴趣文档的聚合。

输入片段可以是完整或部分的句子,对其组成或样式没有限制。 例如,与上面的肯定性查询相反,它们可能是疑问词,我们可以通过搜索“冠状病毒结合的受体是什么?”来找到冠状病毒结合的蛋白受体

上面的搜索系统之间的比较仅用于说明文档发现的基本方法之间的差异。 否则,鉴于语料库大小的数量级差异,这将是不公平的比较,因为我们一定会在一个微小的语料库中获得更多相关的结果。
嵌入在文档搜索中的作用
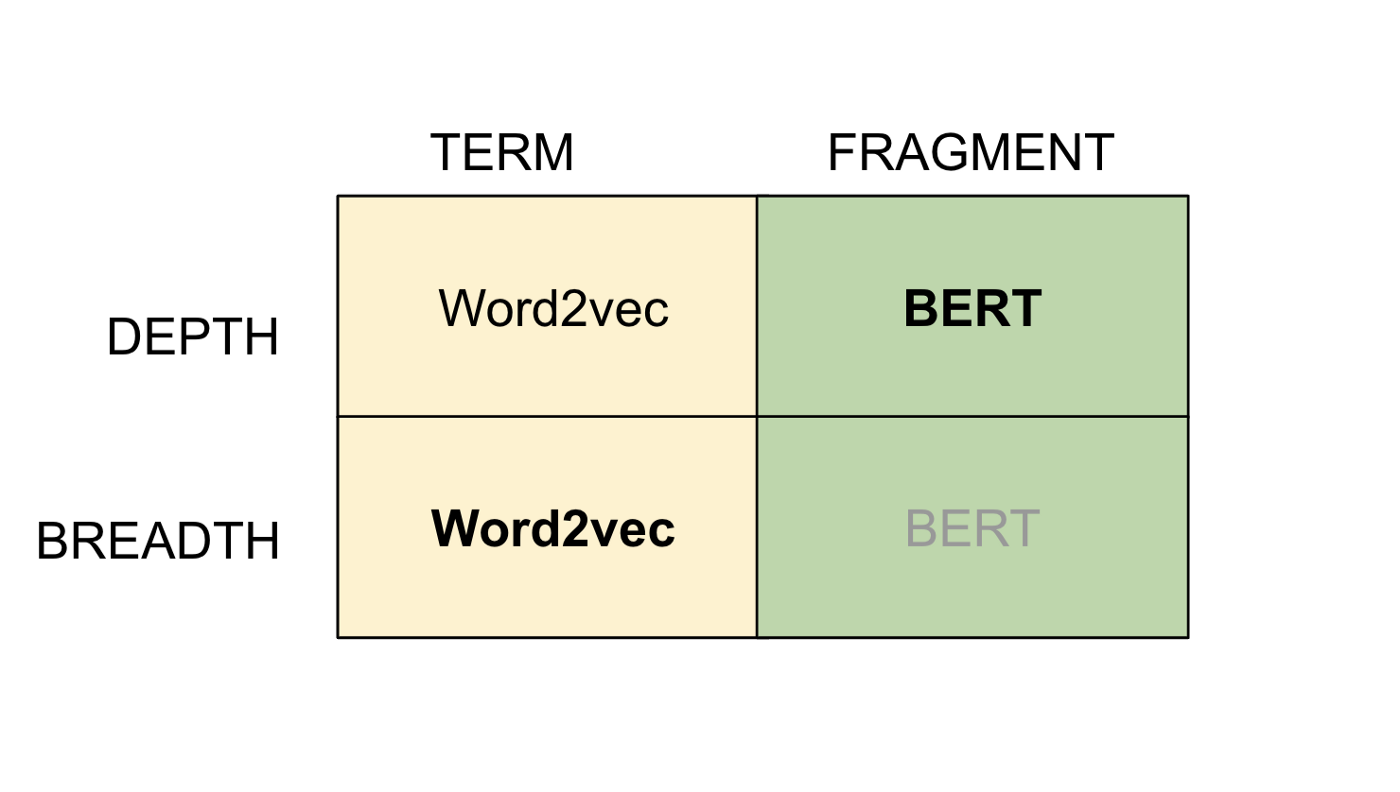
由于向量化表示相对于传统的纯符号搜索方法的优势,它已经成为任何搜索形式不可或缺的一部分。现代搜索系统越来越多地利用它们来补充符号搜索方法。如果我们将文档搜索广泛地视为文档空间的广度优先和深度优先遍历的组合,那么这两种形式的遍历需要具有特定于这些遍历的特征的嵌入。例如,我们可以从引起冠状病毒的动物开始,然后深入到蝙蝠,然后再扩展到爬行动物等。
文档的向量化表示——从Word2vec和BERT的嵌入空间中提取的单词、短语或句子片段都具有独特的互补属性,这些属性对于执行广泛而深入的搜索非常有用。具体地说,词的Word2vec嵌入(词指的是词和短语,如蝙蝠、果子狸等)是广度优先搜索的有效方法,基于实体的聚类应用于结果。搜索“蝙蝠”或“麝香猫”这个词,会得到其他动物,如穿山甲、骆驼等。
BERT嵌入的句子片段(“穿山甲中的冠状病毒”,“蝙蝠作为冠状病毒的来源”等)是有用的,可以发现片段变体,很大程度上保留原始名词,这取决于它们在语料库中的存在。例如,“蝙蝠作为冠状病毒的来源”将产生片段的变异,如“蝙蝠冠状病毒”、“由蝙蝠产生的冠状病毒”等。
这些嵌入虽然在很大程度上是互补的,但也有重叠的特性,word2vec嵌入可以产生深度优先的结果,BERT嵌入在统计结果的分布尾端产生广度优先结果。。例如,使用word2vec嵌入搜索蝙蝠,除了可以搜索到骆驼、穿山甲等其他动物之外,还可以搜索到蝙蝠物种(如果蝠、狐蝠、飞狐、翼龙等)。使用BERT对“孔雀冠状病毒”进行片段搜索,得到“猫冠状病毒病”、“猎豹冠状病毒”,尽管结果主要是鸟类冠状病毒。
BERT模型允许搜索输入(术语或片段)不在词汇表中,从而使任何用户输入都可以找到相关文档。
这种方法是如何工作的?
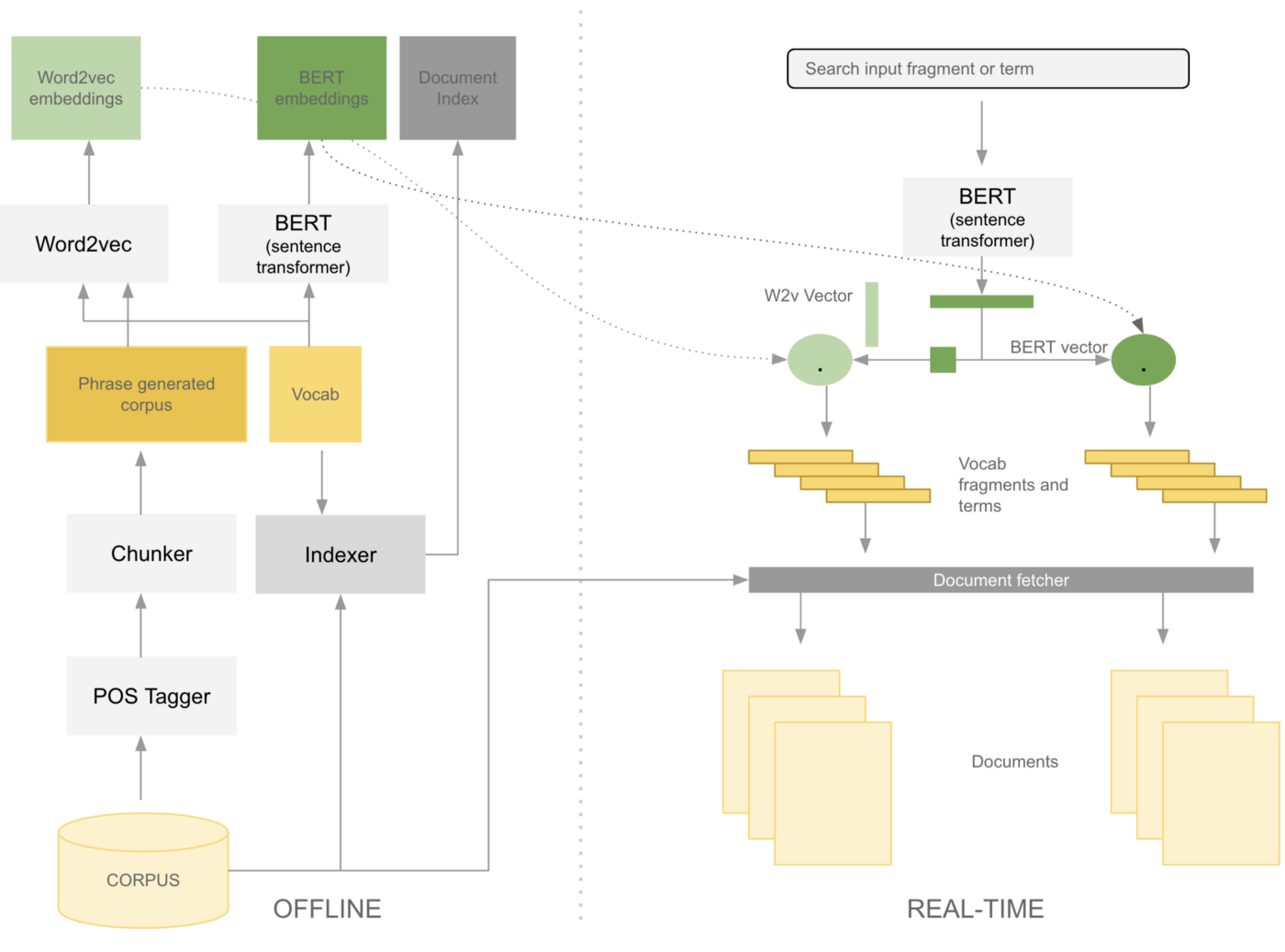
从word2vec/BERT嵌入中获取的扩展术语或片段,用于精确匹配已使用这些术语或片段离线索引的文档。在离线状态下,使用词性标记器和分块器的组合从语料库中获取片段,并使用word2vec和BERT这两种模型为其创建嵌入。
将用户输入映射到术语和片段嵌入不仅具有增加搜索广度和深度的优势,而且还避免了创建与用户输入匹配的高质量文档嵌入的问题。具体来说,片段扮演文档索引的双重角色,并使单个文档具有可搜索的多个“提取摘要”,因为片段嵌入在文档中。与纯粹使用术语或短语查找此类文档相比,使用片段还会增加找到大篇幅文档中目标关键词的几率。例如寻找冠状病毒的潜在动物来源就是在大篇幅文档中找到目标的一个明确的案例。我们可以在上面的图中看到片段与单个文档匹配(这在下面的notes部分中进行了详细的检查)。
使用嵌入纯粹是为了发现候选术语/片段,并利用传统的搜索索引方法来寻找匹配这些术语/片段的文档,这使我们能够大规模地执行文档搜索。
最后,在找到诸如“ COVID-19的动物来源是什么?”之类的广泛问题的答案时鉴于此任务的范围和处理时间很大,因此可以自动且脱机完成此操作,此处介绍的片段嵌入驱动的搜索方法适用于“并不太宽广”的实时搜索用例,例如在给定足够的计算资源和有效的散列方法的情况下,使用“受体冠状病毒的受体”的嵌入大规模执行嵌入空间搜索。
当前方法的局限性
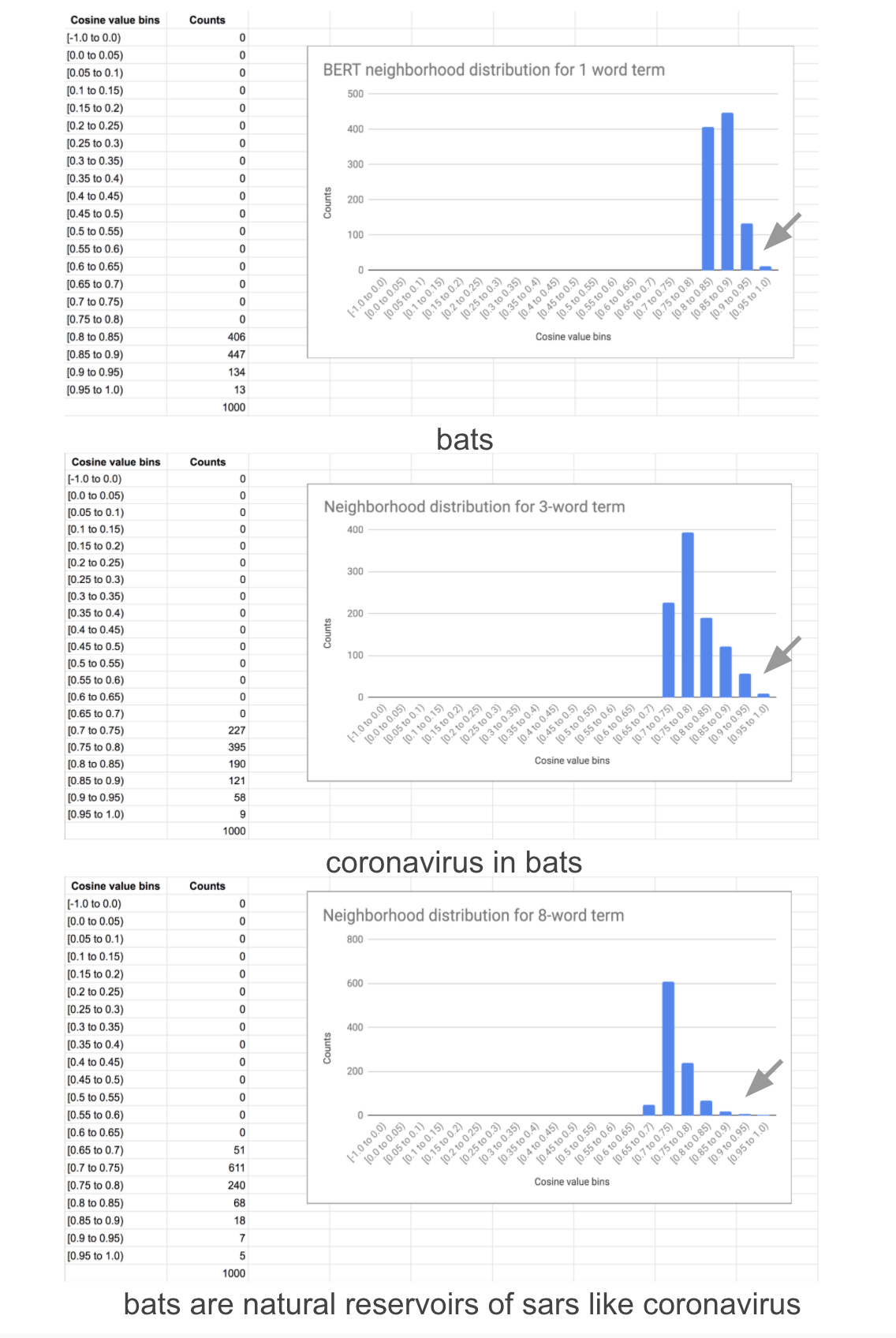
如前所述,word2vec嵌入扩展了单词和短语的搜索范围。它们不会扩展片段搜索的广度——邻域区域的直方图经常缺少一个明显的尾部(下面的图)。这是因为片段由于其长度而没有足够的邻域上下文来学习高质量的嵌入。这一缺陷可以通过扩展训练的窗口大小和忽略句子边界来增加周围的上下文来部分地解决,但是在实践中仍然是不够的,因为片段的出现次数很低。
BERT嵌入在很大程度上只增加了搜索的深度,特别是对于片段和短语(使用BERT嵌入扩展单词的搜索深度在实践中是没有用的)。虽然它们确实在一定程度上增加了宽度,例如,“猕猴中的冠状病毒”的查询扩展为“棕榈果子狸中的冠状病毒”,包含在统计结果的分布尾端,但其宽度不如word2vec提供的单词和短语。下面的图说明了它的不足之处。实现注释中还有一些关于片段搜索缺乏广度的例子,以及一些规避这一限制的方法。
结尾
Word2vec可能是大约七年前第一个明确建立向量化表示能力的模型。这个简单模型的“架构”实际上是两个向量数组,它输出的embeddings对于下游应用程序(如上面描述的文档搜索方法)仍然具有巨大的价值。
Word2vec与BERT嵌入合作,为文档搜索提供了一种解决方案,这种解决方案在搜索结果的质量和收敛时间方面都有可能改进传统方法(这种要求需要进行量化)。搜索系统可以使用该向量表示不仅选择特定的文档,而且还可以找到与所选文档类似的文档。
在选择文档之前,可以使用嵌入(无论是单词、短语还是句子片段)来扩大/深化搜索。词和短语的Word2vec嵌入在很大程度上增加了文档搜索的广度。BERT嵌入大大增加了句子片段的搜索深度。BERT嵌入还消除了生僻词场景,并促进了对文档中不同的重要片段的可搜索提取摘要,从而加快了对相关文档的聚合。
参考
- The animal source of COVID-19 is not confirmed to date. Sentence BERT
- Unsupervised NER using BERT
- An answer explaining how word2vec works
实现的注意事项
1. 此方法中使用的NLP方法/模型是什么?
词性标记来标记一个句子(基于CRF的比目前F1度量的STOA方法快一个数量级,并且模型的召回率也已经满足任务的要求)
分块器(chunker)创建短语
Word2vec表示单词和短语的嵌入
BERT用于片段嵌入(句子转换)
BERT用于无监督实体标记
2. 如何计算文档结果的相关性?
可以通过片段基于到输入片段的余弦距离的排序。并且集中匹配每个片段的文档将被优先挑选出来,并按照与输入片段顺序相同的顺序列出。
3.这种搜索方法是否适用于实时搜索?
实时搜索的计算密集型步骤是嵌入空间中的相似度搜索(Word2vec或BERT)。现有的开放源码解决方案已经可以大规模地执行此操作。我们可以做一些优化来减少时间/计算周期,比如根据输入搜索长度只搜索两个嵌入空间中的一个,因为这些模型的优缺点依赖于搜索长度。
4. 一个片段不就是一个很长的短语吗?如果是,为什么要换一种叫法呢?
a)片段本质上是一个长短语。与短语的区别之所以有用,有一个原因,片段可以是完整的句子,而不只是部分句子
b)这些模型的强度依赖于我们前面看到的输入长度。Word2vec在词/短语方面表现良好。BERT在片段区域表现最好(≥5个单词)
5. 邻域的直方图分布如何查找术语和片段?
以下是BERT和Word2vec的单词、短语(3个单词)和片段(8个单词)的邻域,它们说明了这两个模型的互补性。分布的尾部随着BERT单词长度的增加而增加,而与短语或单词相比,片段的尾部明显不同。当计数项较低时,有时分布可能有很厚的尾部,这表示结果较差。由sentence-transformers产生的嵌入往往有一个独特的尾巴,与bert-as-service产生的嵌入相反,尽管都使用对子词进行求和作为池化方法(也有其他池方法),因为sentence-transfomers的监督训练使用句子对的标签带有蕴含,中性和矛盾的语义。
Word2vec对单词和短语很感兴趣。对于长短语,即使出现的次数很高,这种向量化几乎可以分解为一种“病态形式”,在高端聚集,其余的集中在低端。长短语的分布形状也有所不同。然而,不管形状如何,邻域结果都清楚地表明了这种质量下降。

6. 结果对输入片段变化的敏感性。这就是我们使用输入变量来收敛于相同结果成为可能。
虽然针对同一问题的不同变体检索到的片段集是不同的,但是检索到的片段集中可能有很多交集。但是,由于前面讨论的片段的广度有限,有些问题可能不会产生任何涉及所有搜索的名词的片段。例如,“作为冠状病毒来源的翼龙”或“翼龙冠状病毒”可能不会产生任何含有蝙蝠的片段(翼龙属于蝙蝠科)。当片段不包含所有名词时,需要考虑的一种方法是找到该术语的Word2vec的近义词并使用这些术语重建查询。
7. 使用术语、短语和片段在大篇幅文档,这些模型分别表现如何呢?
Word2vec嵌入在这种情况下并不直接有用,因为单个出现项/短语的向量没有足够的上下文来学习丰富的表示。BERT嵌入没有这个缺点,单词有足够的上下文来学习好的表示。然而,Word2vec仍然可以在搜索中为一个名词找到近义词。例如,如果文档空间中只有一个对果蝠冠状病毒的引用,那么在翼龙中搜索冠状病毒可能不会得到该文档。然而,在果蝠中搜索冠状病毒片段(使用Word2vec创建)可以找到该文档。但是如果一个片段出现在一个分布尾部使它成为一个候选者,那么就可能会被筛出去。大多数片段固有的可解释性提供了一个优势,而一个单词或短语不一定具备这个优势。
8. 关于提取动物冠状病毒信息的更多细节
使用Word2vec和实体标记,大约获得了1000(998)个生物实体。这些被用来收集195个带有病毒的片段。这里显示了一个包含30个片段的示例

这些片段的样本有动物作为冠状病毒潜在来源的证据

原文链接:https://towardsdatascience.com/document-search-with-fragment-embeddings-7e1d73eb0104
欢迎关注磐创AI博客站: http://panchuang.net/
sklearn机器学习中文官方文档: http://sklearn123.com/
欢迎关注磐创博客资源汇总站: http://docs.panchuang.net/














 1998
1998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









