






作者:老宋的茶书会
https://zhuanlan.zhihu.com/p/69389583
前言
最近,已经几乎将重心完全放在了如何在 Bert 之上搞事情,主要还是探索 Bert 在分类问题以及阅读理解问题上的一些表现,已经踩了不少的坑,想着把最近遇到的坑都记录下来,帮助大家更好的使用 Bert。
几个需要注意的地方
文本长度
首先注意到的一点是, 随着文本长度的增加,所需显存容量也会随之呈现线性增加, 运行时间也接近线性,因此,我们往往要做一个权衡,对于不同任务而言, 文本长度所带来的影响力并不相同.
就分类问题而言, 到一定的文本长度后,模型表现就几乎没有变化了,这个时候再去提升文本长度意义就不大了。
512 的魔咒
当你设置你的文本长度超过 512 时,会发生如下错误:
RuntimeError: Creating MTGP constants failed.在 pytorch-pretrained-BERT 项目下的Bert 实现中, 文本长度最多支持512, 这是由于Position Embedding 决定的,这意味着,如果你的文本长度很长, 你就需要采用截断或分批读取的方式来读入。
不要一开始就跑整个数据集
在前期编码测试过程中,由于数据集往往很大,加载的过程很漫长,我们就必须等到加载完成才能看看模型能不能跑起来,而实际上,往往需要不断试错。如果每次都跑全数据集,那么对于中大数据集,尤其是使用上 Bert 之后(分词慢), 其效率简直令人发指。
因此,十分推荐先分出一个demo级别的子数据集,我一般会份 1000, 1000, 1000,完整的跑一次之后再进行真正数据集的运行。
文本分类任务如何微调 Bert [2]
如何截取文本
由于 Bert 支持最大长度为 512 个token,那么如何截 取文本也成为一个很关键的问题。[2] 中探讨了三种方式:
head-only:保存前 510 个 token (留两个位置给 [CLS] 和 [SEP] )
tail-only:保存最后 510 个token
head + tail :选择前128个 token 和最后382个 token
而作者在 IMDB 和 sogou 数据集上测试,发现 head + tail 效果最好,因此实际中,这三种思路都值得一试,搞不好能提高一点点呢。
多层策略
还有一种方法是将文本划分为多段,每一段都不超过512个token, 这样就能够完全捕捉到全部的文本信息了。但这对于分类任务来说真的有用吗?
我个人认为收效甚微, 就像我们读一篇文章,基本读个开头,结尾基本就知道这篇文章是什么主题,属于哪个分类了,极少数情况下会出现那种模糊不清的状况, 而实验也的确表明并没有获得很好的效果提升。
[2] 中首先将文本划分为 段, 然后分别对每一段进行编码,在融合信息的时候采用了三种战略:
多层 + mean:各段求平均值
多层 + max :各段求最大值
多层 + self-att :加一层 Attention 融合
实验表明,效果并没有任何提升,甚至还有所下降, 我自己在 CNews 数据集上进行了多层策略的测试,发现效果提升有限,0.09个百分点,可以说几乎没有提升了,后续会再测试几个数据集,可参见我的仓库:Bert-TextClassification
Catastrophic Forgetting
Catastrophic Forgetting 指的是在迁移学习中,当学习新知识时,会忘记以前很重要的旧知识,那么 Bert 作为NLP 中迁移学习的代表,它是否有严重的 Catastrophic Forgetting 问题呢?
[2] 中发现,一个较低的学习率,如 2e-5 是 Bert 克服 Catastrophic Forgetting 问题的关键,且在 pytorch-pretrained-BERT 的实现中, 学习率是 5e-5 ,也对应了这个观点。
是否需要预训练
微调虽然足够强大,但是预训练能否再次带来效果的提升以及如何进行预训练依旧是未知的话题。
首先第一个问题: 预训练能否带来效果的提升?答案是大概率会, 具体的提升依旧需要看数据集本身,从 [2] 中的实验看出,大多数数据集都有不等的效果提升。
第二个问题:如何进行预训练,或者说是采用哪些数据进行预训练,主要有三个策略:
在特定数据集上做预训练。[2] 中的实验表明,这种方式大概率能够提升效果。
同领域数据上预训练。一般情况下,这种会比策略1的效果更好,且数据更容易获取,但是如果数据来源不一,是可能带来噪声的。
跨领域数据上预训练。这种策略效果提升没有上两种策略大,这是因为Bert 本身就已经经过高质量,大规模的跨领域数据训练
综合来说, 策略 2 是最佳的,前提是你需要保证数据的质量。
卡几何,多多益善?
Pytorch 多GPU并行
我们先来谈谈在多GPU情况下, Pytorch 内部处理机制原理, 这对我们调参很有帮助。
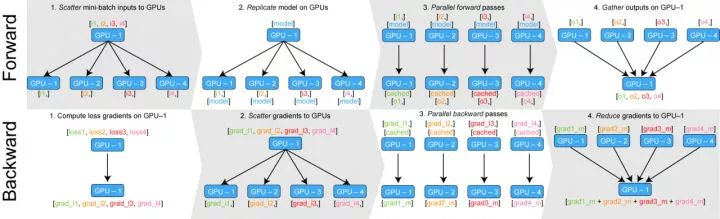
Pytorch 与大多数深度学习框架一样, 其选择了数据并行(图1)的方式来处理多GPU下的模型训练, 但有其特殊之处。

具体来说, Pytorch 首先将模型加载到主GPU(一般是device_id=0), 然后再将模型复制到各个GPU上, 然后将一个 batch 的数据按照GPU个数划分,将对应的数据输入到各个GPU内。每个GPU都独立的进行前向计算。而在反向传播中, Pytorch需要汇总各个GPU上的模型输出信息到GPU 0(个人理解,希望大佬指正,有时间会做实验分析一下),这使得GPU 0 所占用的显存相对较大, 且梯度计算过程会集中在GPU 0 上,梯度计算完成之后再将梯度复制到其余GPU,然后进行反向传播更新。
实际实验表明, 对于分类任务而言,差距并不明显,但对于语言模型任务,由于其输出层很大,有可能导致 GPU 爆掉。如下图所示:

我们要用几张卡?
对于小数据集而言, 建议使用 1 或2个GPU搞定, 多GPU情况下我们需要考虑到通信时间因素,而通信传输是比较慢的,亲测对于小数据集而言,GPU太多反而耗时更久。对于中大数据集,需要自己判断,多试试在几个GPU情况下相对最省时间,又有足够的显存。
pytorch 中使用多卡
多卡情况下,模型相关的调用有所区别,主要在以下几个方面:
# 模型定义
if n_gpu > 1:
model=nn.DataParallel(model,device_ids=[0,1,2])
# 损失计算
if n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu.
# 模型保存
model_to_save = model.module if hasattr(
model, 'module') else model
torch.save(model_to_save.state_dict(), output_model_file)我们看到。最主要的变化依旧在模型不分, 这也是必须了解的 nn.DataParallel。
多GPU情况下负载均衡问题
具体在使用单机多GPU, 发现 GPU 0所占用的显存要大于其余 GPU, 这是由于模型输出以及相关梯度张量最终会汇总在GPU 0 上,前面已经有所提及,这就是 Pytorch 的负载均衡问题。
Pytorch 的负载均衡问题对于一般任务如分类来说其实并不严重, 而对于输出层较大的任务如语言模型而言就十分关键,这也侧面证明了我以前说的话:语言模型并不是一般实验室和公司能搞的。
我个人目前并没有受到这个问题很深的困扰,因此就没有较深的探索,毕竟 梯度累积 这个Trick 还是十分良心的。
而对于 Pytorch 的负载均衡问题,大致有两种解决思路:
第一种是采用分布式 DistributedDataParallel
另一种是自己写, 可以看看 [1], 由于没有深入就不废话了。
最后
其实,这篇文章更像是笔记,算是对自己最近遇到的坑的一个总结,相信大家也都多多少少会遇到这些问题,因此分享出来给大家一些思考。懒得写的更长了,就这样吧。
如果觉得有用,点个赞再走吧,毕竟,写文不易啊。
Reference
[1] 增大Batch训练神经网络:单GPU、多GPU及分布式配置的实用技巧
[2] How to Fine-Tune BERT for Text Classification?


备注:公众号菜单包含了整理了一本AI小抄,非常适合在通勤路上用学习。

往期精彩回顾
2019年公众号文章精选适合初学者入门人工智能的路线及资料下载机器学习在线手册深度学习在线手册AI基础下载(第一部分)备注:加入本站微信群或者qq群,请回复“加群”加入知识星球(4500+用户,ID:92416895),请回复“知识星球”
喜欢文章,点个在看

















 2330
2330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









