






作者:十方
bert的大名如雷贯耳,无论在比赛,还是实际上的应用早已普及开来。想到十方第一次跑bert模型用的框架还是paddlepaddle,那时候用自己的训练集跑bert还是比较痛苦的,不仅要看很多配置文件,预处理代码,甚至报错了都不知道怎么回事,当时十方用的是bert双塔做文本向量的语义召回。如今tf都已经更新到了2.4了,tensorflow-hub的出现更是降低了使用预训练模型的门槛,接下来带大家看下,如何花十分钟时间快速构建bert双塔召回模型。
tensorflow hub
打开tensorflow官网,找到tensorflow-hub点进去,我们就能看到各种预训练好的模型了,找到一个预训练好的模型(如下图),下载下来,如介绍所说,这是个12层,768维,12头的模型。
在往下看,我们看到有配套的预处理工具:
同样下载下来,然后我们就可以构建bert双塔了。
Bert双塔
import os
import shutil
import pickle
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization
from tensorflow.keras import *
from tqdm import tqdm
import numpy as np
import pandas as pd
import json
import re
import random
# 这里读你自己的文本数据集
with open('./data/train_data.pickle', 'rb') as f:
train_data = pickle.load(f)
# 读数据用的generater
def train_generator():
np.random.shuffle(train_data)
for i in range(len(train_data)):
yield train_data[i][0], train_data[i][1]
# 训练数据 dataset
ds_tr = tf.data.Dataset.from_generator(train_generator, output_types=(tf.string, tf.string))
# bert 双塔 dim_size是维度 model_name是下载模型的路径
def get_model(dim_size, model_name):
# 下载的预处理工具路径
preprocessor = hub.load('./bert_en_uncased_preprocess/3')
# 左边塔的文本
text_source = tf.keras.layers.Input(shape=(), dtype=tf.string)
# 右边塔的文本
text_target = tf.keras.layers.Input(shape=(), dtype=tf.string)
tokenize = hub.KerasLayer(preprocessor.tokenize)
tokenized_inputs_source = [tokenize(text_source)]
tokenized_inputs_target = [tokenize(text_target)]
seq_length = 512 # 这里指定你序列文本的最大长度
bert_pack_inputs = hub.KerasLayer(
preprocessor.bert_pack_inputs,
arguments=dict(seq_length=seq_length))
encoder_inputs_source = bert_pack_inputs(tokenized_inputs_source)
encoder_inputs_target = bert_pack_inputs(tokenized_inputs_target)
# 加载预训练参数
bert_model = hub.KerasLayer(model_name)
bert_encoder_source, bert_encoder_target = bert_model(encoder_inputs_source), bert_model(encoder_inputs_target)
# 这里想尝试in-batch loss
# 也可以直接对 bert_encoder_source['pooled_output'], bert_encoder_target['pooled_output'] 做点积操作
matrix_logit = tf.linalg.matmul(bert_encoder_source['pooled_output'], bert_encoder_target['pooled_output'], transpose_a=False, transpose_b=True)
matrix_logit = matrix_logit / tf.sqrt(dim_size)
model = models.Model(inputs = [text_source, text_target], outputs = [bert_encoder_source['pooled_output'], bert_encoder_target['pooled_output'], matrix_logit])
return model
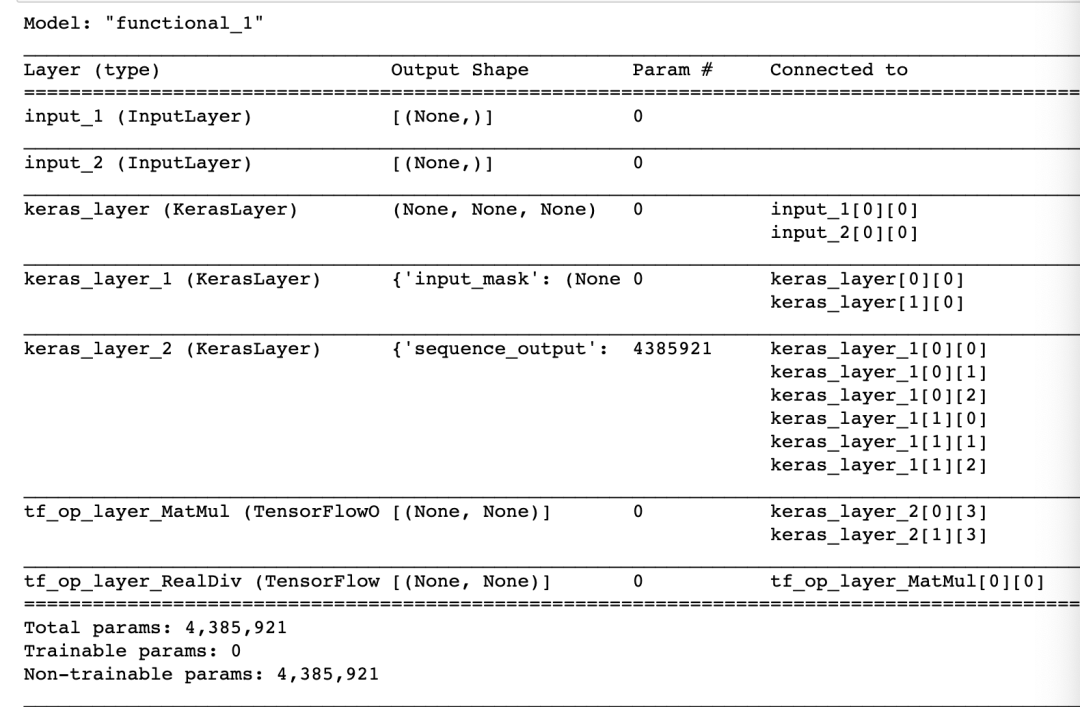
bert_double_tower = get_model(128.0, './small_bert_bert_en_uncased_L-2_H-128_A-2_1/3')
bert_double_tower.summary()
我们看到bert双塔模型已经构建完成:
然后定义loss,就可以训练啦!
optimizer = optimizers.Adam(learning_rate=5e-5)
loss_func_softmax = tf.keras.losses.CategoricalCrossentropy(from_logits=True)
train_loss = metrics.Mean(name='train_loss')
train_acc = metrics.CategoricalAccuracy(name='train_accuracy')
def train_step(model, features):
with tf.GradientTape() as tape:
p_source, p_target, pred = model(features)
label = tf.eye(tf.shape(pred)[0])
loss = loss_func_softmax(label, pred)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss.update_state(loss)
train_acc.update_state(label, pred)
def train_model(model, bz, epochs):
for epoch in tf.range(epochs):
steps = 0
for feature in ds_tr.prefetch(buffer_size = tf.data.experimental.AUTOTUNE).batch(bz):
logs_s = 'At Epoch={},STEP={}'
tf.print(tf.strings.format(logs_s,(epoch, steps)))
train_step(model, feature)
steps += 1
train_loss.reset_states()
train_acc.reset_states()
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑
本站qq群851320808,加入微信群请扫码:















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









