






作者丨helton_yan@CSDN(已授权)
来源丨https://blog.csdn.net/SESESssss/article/details/114340066
编辑丨极市平台
导读
本文基于代码实战复现了经典的Backbone结构Inception v1、ResNet-50和FPN,并基于PyTorch分享一些网络搭建技巧,很详细很干货!
文章目录
1.VGG
1.1改进:
1.2 PyTorch复现VGG19
1.2.1 小Tips:
1.2.2 打印网络信息:
Inception(GoogLeNet)
2.1改进(Inception v1)
2.2.2改进(Inception v2)
2.2 PyTorch复现Inception v1:
2.2.1 网络的整体框架:
2.2.2 各层的参数情况:
2.2.3 pytorch复现Inception基础模块
2.2.4 小Tips
ResNet
3.1改进
3.2PyTorch 复现 ResNet-50
3.2.1ResNet-50网络整体架构
3.2.2 Bottleneck结构
3.2.3 ResNet-50图解及各层参数细节
3.2.4 实现一个Bottleneck模块:
3.2.5 实现resnet-50
FPN(特征金字塔)
4.1 特征的语义信息
4.2 改进
4.3 PyTorch 复现 FPN
4.3.1 FPN网络架构
4.3.2 复现FPN
前言
卷积神经网络的发展,从上个世纪就已经开始了,让时间回到1998年,在当时,Yann LeCun 教授提出了一种较为成熟的卷积神经网络架构LeNet-5,现在被誉为卷积神经网络的“HelloWorld”,但由于当时计算机算力的局限性以及支持向量机(核学习方法)的兴起,CNN方法并不是当时学术界认可的主流方法。时间推移到14年后,随着AlexNet以高出第二名约10%的accuracy rate成为了2012年ImageNet图像识别竞赛的第一名,深度学习以及卷积神经网络的研究热潮被彻底引爆,从此CNN进入了飞速发展的阶段,从无人问津到一度成为计算机视觉的主流框架,在此之后,各种基于CNN的图像识别网络开始大放异彩。各种CNN网络层出不穷。
本次博客将介绍如今图像识别领域十分经典的一些CNN网络,虽然现在卷积网络框架也随着研究的深入变得越来越复杂,但我们仍然可以在一些最新的网络结构中发现它们的身影,这些经典CNN网络有时候是整个算法提取特征的骨架(特征的质量往往直接影响到分类结果的准确度,表达能力更强的特征也能给模型带来更强的分类能力),因此又称为“Backbone”(骨干网络)。
本次博客基于代码实战复现经典的Backbone结构,并基于PyTorch分享一些网络搭建技巧。
1.VGG
网络架构:
VGG16网络由13层卷积层+3层全连接层构成。
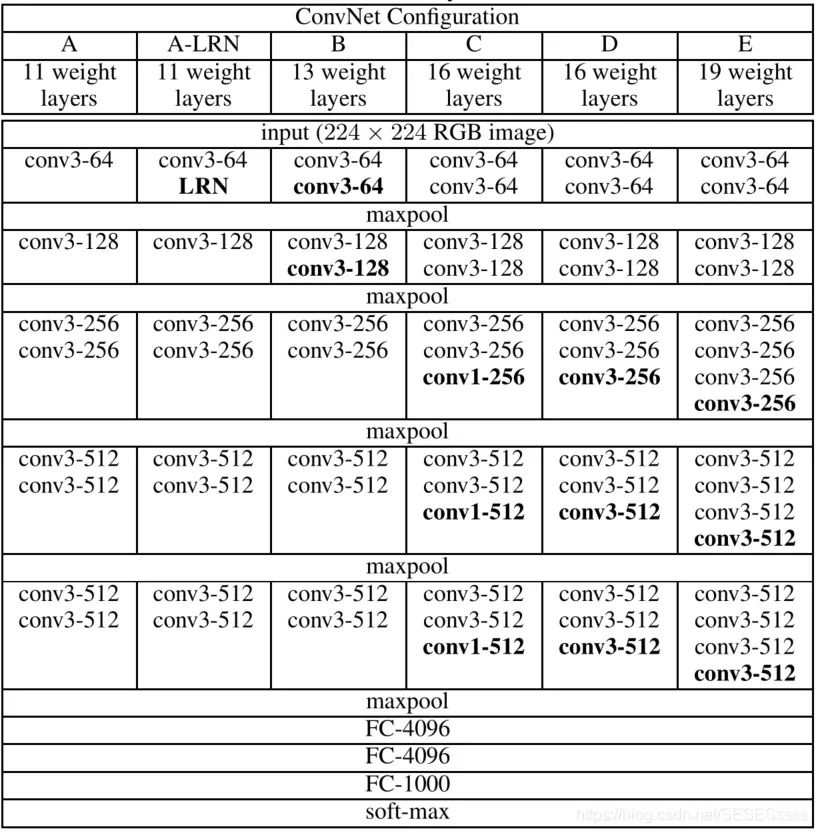
1.1改进:
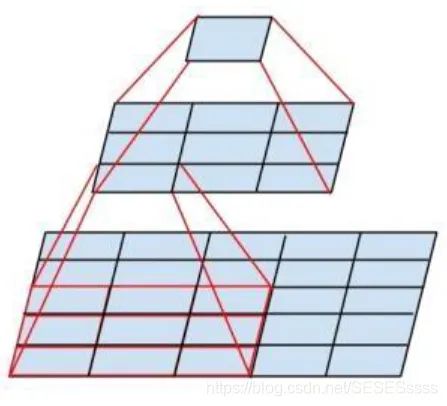
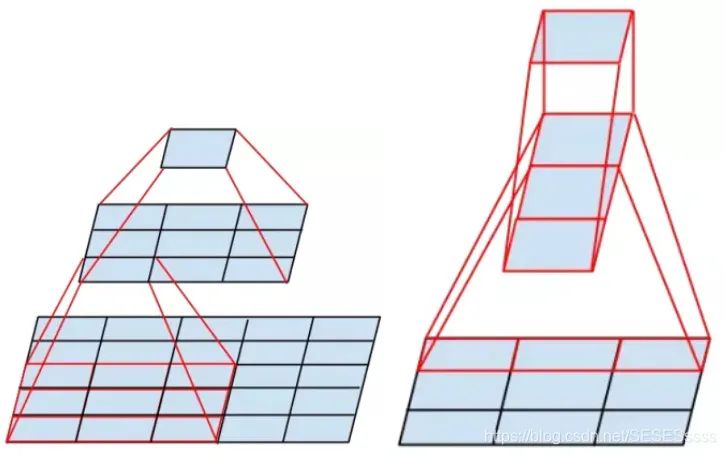
更小的卷积核,对比AlexNet,VGG网络使用的卷积核大小不超过3x3,这种结构相比于大卷积核有一个优点,就是两个3x3的卷积核堆叠对于原图提取特征的感受野(特征图一个像素融合了输入多少像素的信息决定了感受野的大小)相当于一个5x5卷积核(如图),并且在同等感受野的条件下,两个3x3卷积之间加入激活函数,其非线性能力比单个5x5卷积要强。
更深的网络结构,相比于AlexNet只有5层卷积层,VGG系列加深了网络的深度,更深的结构有助于网络提取图像中更复杂的语义信息。
1.2 PyTorch复现VGG19
class VGG19(nn.Module):
def __init__(self, num_classes = 1000): # num_classes 预分类数
super(VGG19, self).__init__()
#构造特征提取层:
feature_layers = [] # 将卷积层存储在list中
in_dim = 3 # 输入是三通道图像
out_dim = 64 # 输出特征的深度为64
#采用循环构造的方式,对于深度网络能避免代码形式冗余:
for i in range(16):# vgg19共16层卷积
feature_layers += [nn.Conv2d(in_dim, out_dim,3,1,1), nn.ReLU(inplace = True)] # 基本结构:卷积+激活函数
in_dim = out_dim
# 在第2,4,8,12,16,层卷积后增加最大池化:
if i == 1 or i == 3 or i == 7 or i == 11 or i == 15 :
feature_layers += [nn.MaxPool2d(2)]
if i < 11:
out_dim *= 2
self.features = nn.Sequential(*feature_layers)
# *表示传入参数的数量不固定,否则报错list is not a Module subclass
#全连接层分类:
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(inplace = True),
nn.Dropout(),
nn.Linear(4096,4096),
nn.ReLU(inplace = True),
nn.Dropout(),
nn.Linear(4096,num_classes),
)
#前向传播
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x1.2.1 小Tips:
当网络的结构重复时,使用for循环构造避免代码形式冗余
将不同功能的网络各自封装到一个大的Sequential模块中,结构分明
卷积操作输出尺寸计算公式:Out=(In-Kernel+2Padding)/Stride+1 (Kernel:卷积核尺寸,Stride:步长,Padding:边界填充) 若要保证输出尺寸和原尺寸一致,Padding可以设置为:Padding = (kernel-1)/2)
池化操作输出尺寸计算公式同卷积操作一致
在实际深度学习框架实现卷积和全连接的计算中,本质都是矩阵运算:
若输入的特征图深度是N,输出特征图深度是M,则卷积核的维度是:NxMxKxK(K为卷积核大小)。因此全卷积网络对输入图像的尺寸没有要求。
全连接层的尺寸和输入的特征尺寸相关(将特征图展平成为一维向量),若输入的特征向量是1xN,输出是1xM,则全连接层的维度是:MxN。
1.2.2 打印网络信息:
使用torch.summary输出网络架构:
vgg19 = VGG19()
#print(vgg19) #输出网络的架构
summary(vgg19, input_size = [(3, 224, 224)]) #输出网络架构,每一层的输出特征尺寸,及网络参数情况输出网络每一层的尺寸:
for param in vgg19.parameters(): # 输出每一层网络的尺寸
print(param.size())
batch_size = 16
input = torch.randn(batch_size, 3, 224, 224) #构建一个随机数据,模拟一个batch_size
output = vgg19(input)
print(output.shape) # torch.Size([16, 1000])2.Inception(GoogLeNet)
2.1改进(Inception v1)
以往网络的不足:
加深深度导致的网络参数增加
深层网络需要更多的训练数据,容易产生过拟合
深层网络在训练过程中容易导致梯度消失
改进:
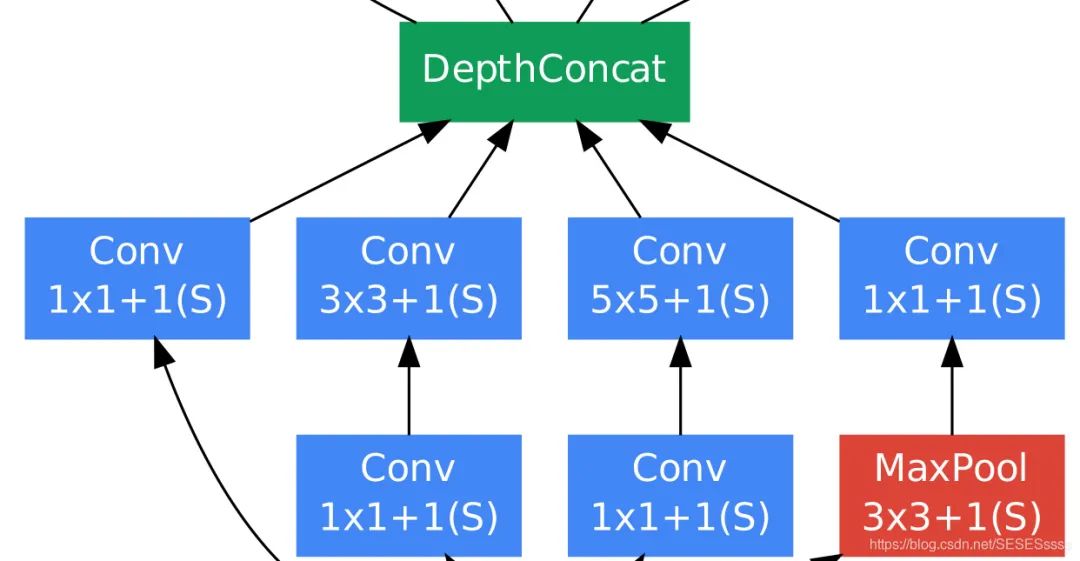
引入了Inception模块作为网络的基础模块,整体的网络基于基础模块的堆叠;在模块中使用了通道拼接(Concat)的方法对不同卷积核提取的特征进行拼接
Inception基础的模块如图所示,使用3个不同尺寸的卷积核进行卷积运算,同时还包括一个最大池化,最后将这四个部分输出的结果进行通道拼接,传给下一层:
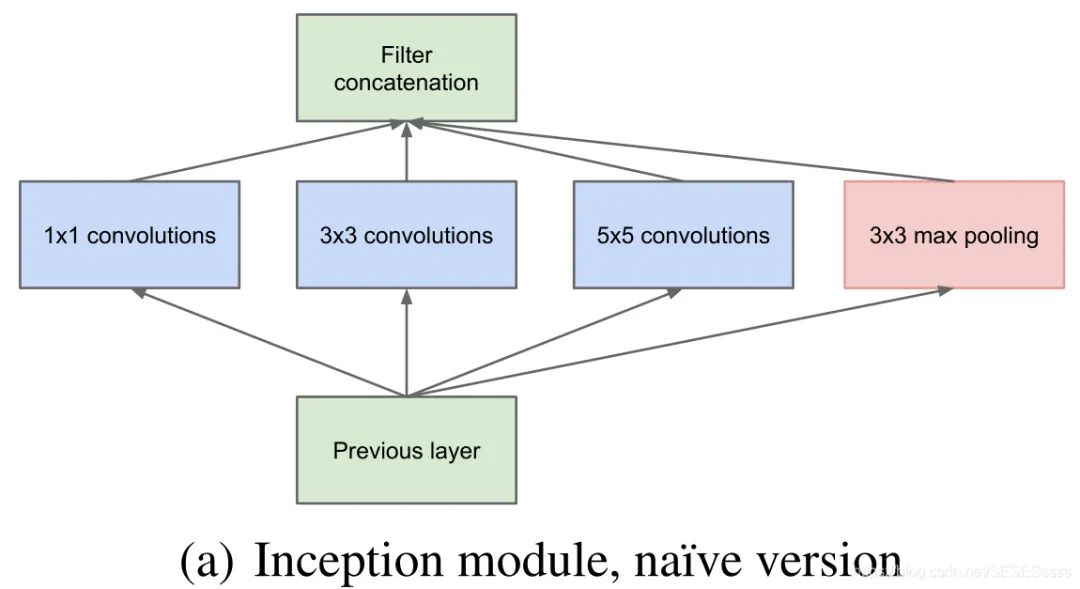
使用1x1卷积进行数据降维(减少深度),减少训练的参数量。
上图这个结构有一个弊端,即模块中一个分支的输入通道数就是前一个模块所有分支输出通道数之和(通道合并),在多个模块堆叠后计算的参数量将会变得十分巨大,为了解决这个问题,作者在每一个分支的卷积层之前单独加了一个1x1卷积,来进行通道数的降维
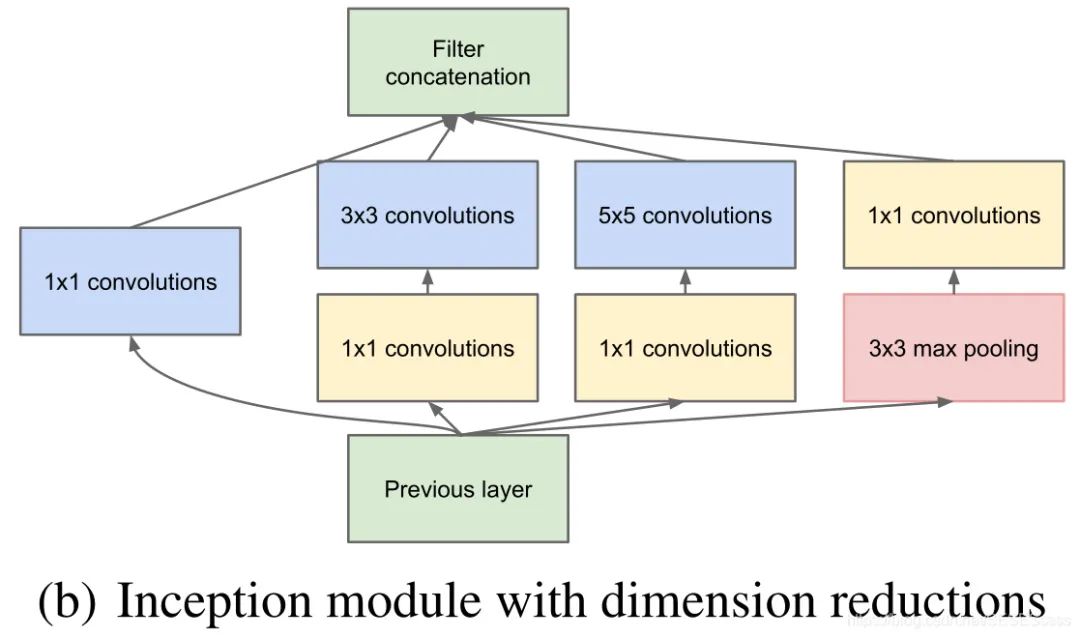
我们或许会有一个疑问,为什么不在3x3或5x5卷积输出上直接降维特征,而非得使用1x1卷积呢,(作者认为这样做能够增加网络的非线性能力,因为卷积和卷积之间有激活函数)
引入辅助分类器(在不同深度计算分类最后一并回传计算损失)
作者发现网络中间层的特征和较深层的特征有很大的不同,因此在训练时额外在中间层增加了两个辅助分类器。辅助分类器的结果同输出结果一并计算损失,并且辅助分类器的损失为网络总损失的0.3。作者认为这样的结构有利于增强网络在较浅层特征的分类能力,**相当于给网络加了一个额外的约束(正则化)**,并且在推理时这些辅助网络的结构将被舍弃。
2.2.2改进(Inception v2)
卷积分解
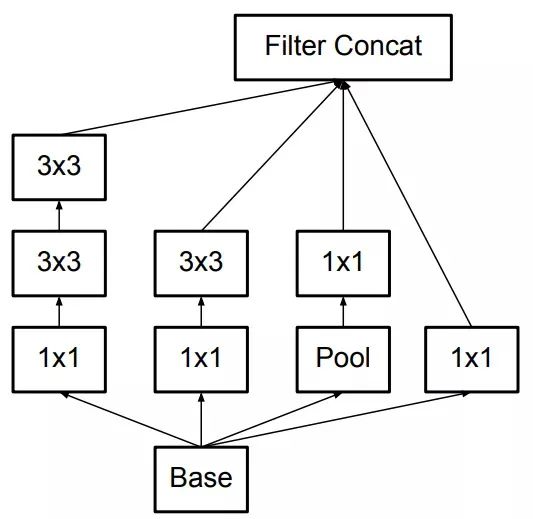
Inception v2较Inception v1将5x5的大卷积分解成两个3x3的小卷积(效仿VGG网络的处理方式,减少了参数量同时增加网络的非线性能力),并加入了BN层:
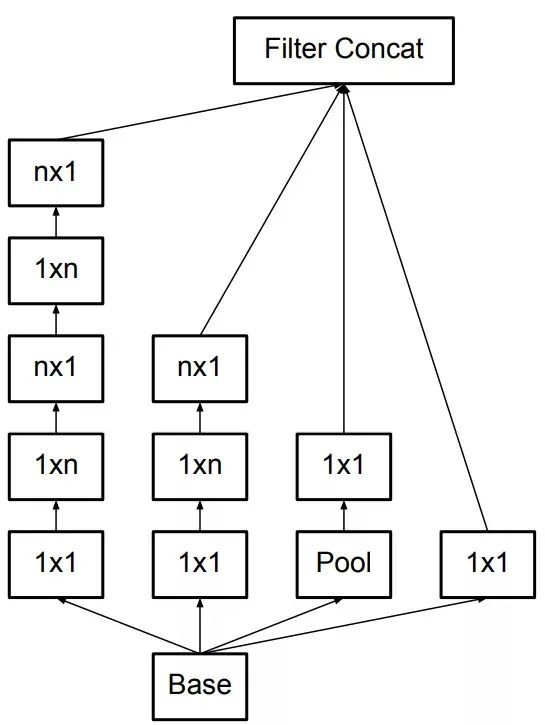
进一步的,Inception v2将nxn卷积分解为两个1xn和nx1卷积(空间可分离卷积Spatially Separable Convolution),在感受野相当的情况下,进一步减少了网络的参数:
参考:
Inception系列之Inception_v2-v3:https://www.cnblogs.com/wxkang/p/13955363.html
[论文笔记] Xception:https://zhuanlan.zhihu.com/p/127042277
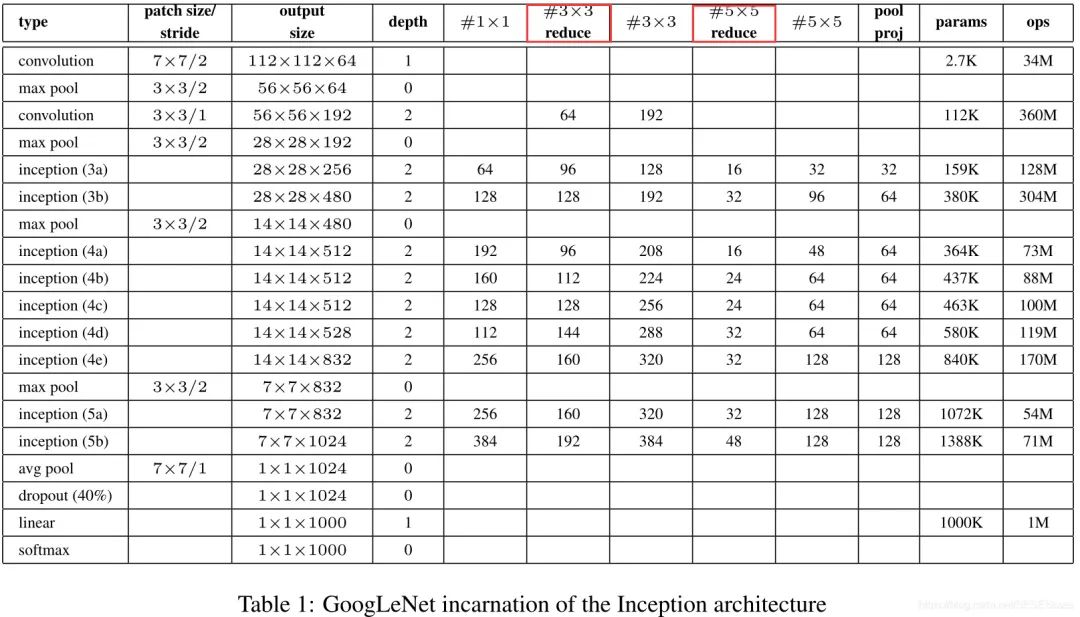
2.2 PyTorch复现Inception v1:
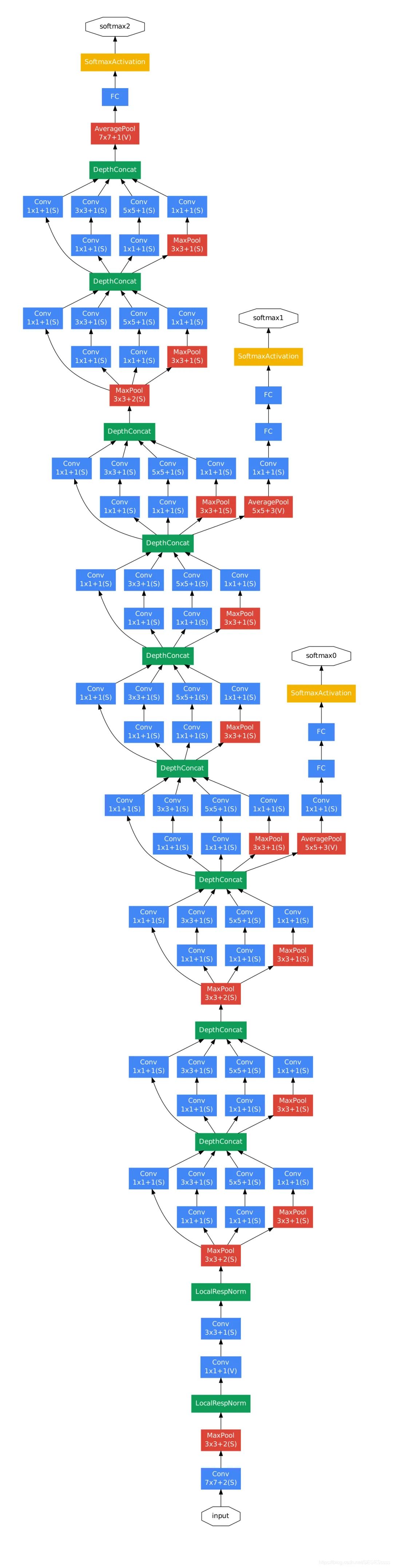
2.2.1 网络的整体框架:
2.2.2 各层的参数情况:
红色框表示用于特征降维的1x1卷积
2.2.3 pytorch复现Inception基础模块
将卷积+激活函数作为一个基础的卷积组:
# 将Conv+ReLU封装成一个基础类:
class BasicConv2d(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size,
stride=stride, padding=padding),
nn.ReLU(True)
)
def forward(self, x):
x = self.conv(x)
return x构造一个Inception模块:
# 构造Inception基础模块:
class Inception(nn.Module):
def __init__(self, in_dim, out_1x1, out_3x3_reduce, out_3x3, out_5x5_reduce, out_5x5, out_pool):
super(Inception, self).__init__()
# 分支1:
self.branch_1x1 = BasicConv2d(in_dim, out_1x1, 1)
# 分支2:
self.branch_3x3 = nn.Sequential(
BasicConv2d(in_dim, out_3x3_reduce, 1),
BasicConv2d(out_3x3_reduce, out_3x3, 3, padding=1),
)
# 分支3:
self.branch_5x5 = nn.Sequential(
BasicConv2d(in_dim, out_5x5_reduce, 1),
BasicConv2d(out_5x5_reduce, out_5x5, 5, padding=2),
)
# 分支4:
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
BasicConv2d(in_dim, out_pool, 1),
)
def forward(self, x):
b1 = self.branch_1x1(x)
b2 = self.branch_3x3(x)
b3 = self.branch_5x5(x)
b4 = self.branch_pool(x)
output = torch.cat((b1, b2, b3, b4), dim=1) # 四个模块沿特征图通道方向拼接
return output搭建完整的Inceptionv1:
# 构建Inceptionv1:
class Inception_v1(nn.Module):
def __init__(self, num_classes=1000, state="test"):
super(Inception_v1, self).__init__()
self.state = state
self.block1 = nn.Sequential(
BasicConv2d(3, 64, 7, stride=2, padding=3),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
nn.LocalResponseNorm(64),
BasicConv2d(64, 64, 1),
BasicConv2d(64, 192, 3, padding=1),
nn.LocalResponseNorm(192),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
)
self.block2 = nn.Sequential(
Inception(192, 64, 96, 128, 16, 32, 32),
Inception(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
Inception(480, 192, 96, 208, 16, 48, 64),
)
self.block3 = nn.Sequential(
Inception(512, 160, 112, 224, 24, 64, 64),
Inception(512, 128, 128, 256, 24, 64, 64),
Inception(512, 112, 144, 288, 32, 64, 64),
)
self.block4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=2, padding=1),
Inception(528, 256, 160, 320, 32, 128, 128),
Inception(832, 256, 160, 320, 32, 128, 128),
Inception(832, 384, 192, 384, 48, 128, 128),
nn.AvgPool2d(3, stride=1),
)
self.classifier = nn.Linear(4096, num_classes)
if state == "train":
# 两个辅助分类器:
self.aux_classifier1 = Inception_classify(
192 + 208 + 48 + 64, num_classes)
self.aux_classifier2 = Inception_classify(
112 + 288 + 64 + 64, num_classes)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
# 插入辅助分类层1
if self.state == 'train':
aux1 = self.aux_classifier1(x)
x = self.block3(x)
# 插入辅助分类层2
if self.state == 'train':
aux2 = self.aux_classifier2(x)
x = self.block4(x)
x = x.view(x.size(0), -1)
out = self.classifier(x)
if self.state == 'train':
return aux1, aux2, out
else:
return out2.2.4 小Tips
在构建比较复杂的网络时,将网络重叠使用的一些基础模块封装为一个基础的类(层次分明)。
3.ResNet
在以往的经验上,人们普遍认为通过加深网络的层数能够使得网络具有更强的学习能力,即使网络容易产生过拟合/梯度消失的问题,在现有方法下也可以通过增加数据集,Dropout或者正则化/加入BN层解决。但是通过实验数据发现,即使加入有效的措施抑制网络产生过拟合或者梯度消失,网络的精度也会随着深度的增加而下降,并且还不是由于过拟合引起的(实验数据表明越深的网络training loss反而越高)
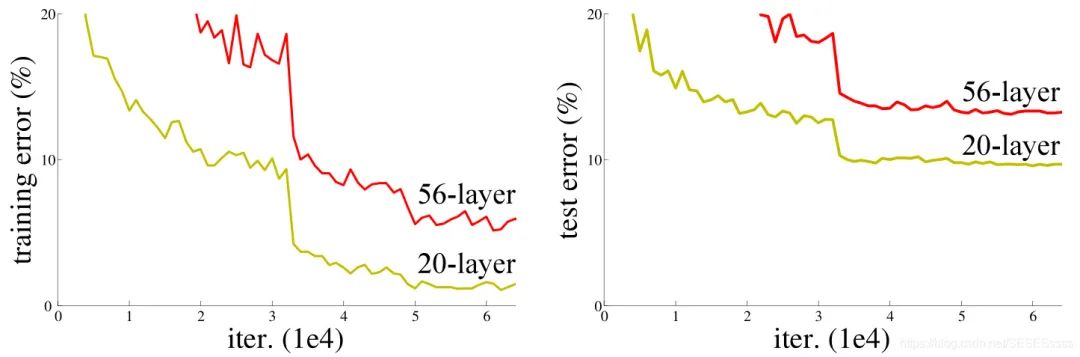
事实上,阻碍网络向深度发展的一个主要因素就是梯度不能得到有效的传播,越深的网络反传过程中的梯度相关性会越来越差,接近于白噪声,导致梯度的更新也相当于随机扰动。
Resnet到底在解决一个什么问题呢?https://www.zhihu.com/question/64494691
打个形象的比喻,就如我们小时候玩过的口传悄悄话游戏,随着参与人数的增多,最后一个人口中说出的信息往往早已和原先纸条上的信息大相径庭。
3.1 改进
以往的瓶颈:深度网络不可控的梯度消失,深层网络与浅层网络的梯度相关性下降,网络难以训练。
ResNet的改进:引入了一个残差映射的结构来解决网络退化的问题:
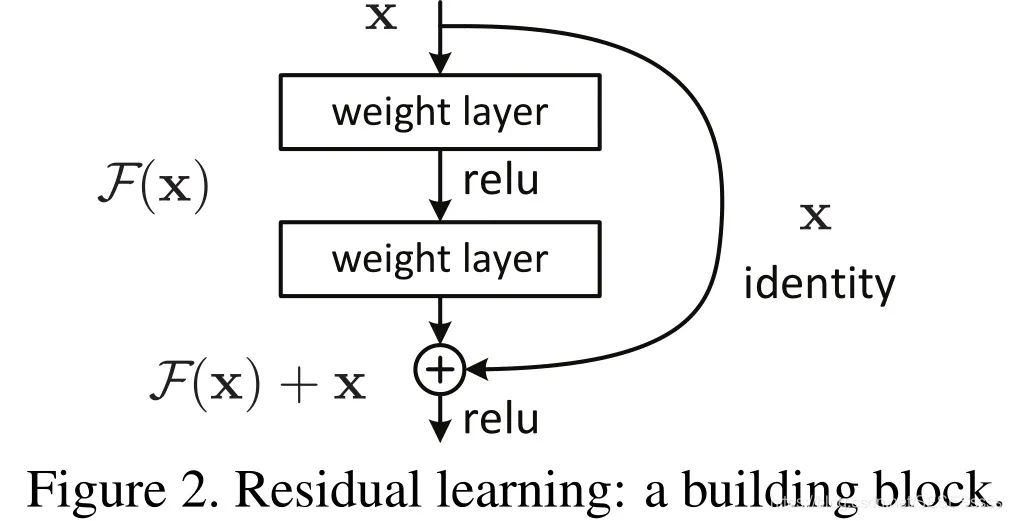
何为残差映射?
假设输入的特征为x,期望输出的特征为H(x)。我们知道,对于一般的神经网络而言,每一层的目的无非就是对输入x进行非线性变换,将特征x映射到尽量趋近H(x),即,网络需要直接拟合输出H(x).
而对于残差映射,模块中通过引入一个shortcut分支(恒等映射),将网络需要拟合的映射变为残差F(x):F(x) = H(x) - x.
作者在论文中假设:相较于直接优化H(x),优化残差映射F(x)能有效缓解反向传播过程中的梯度消失问题,解决了深度网络不可训练的困难:[Resnet-50网络结构详解]https://www.cnblogs.com/qianchaomoon/p/12315906.html
3.2 PyTorch 复现 ResNet-50
3.2.1 ResNet-50网络整体架构
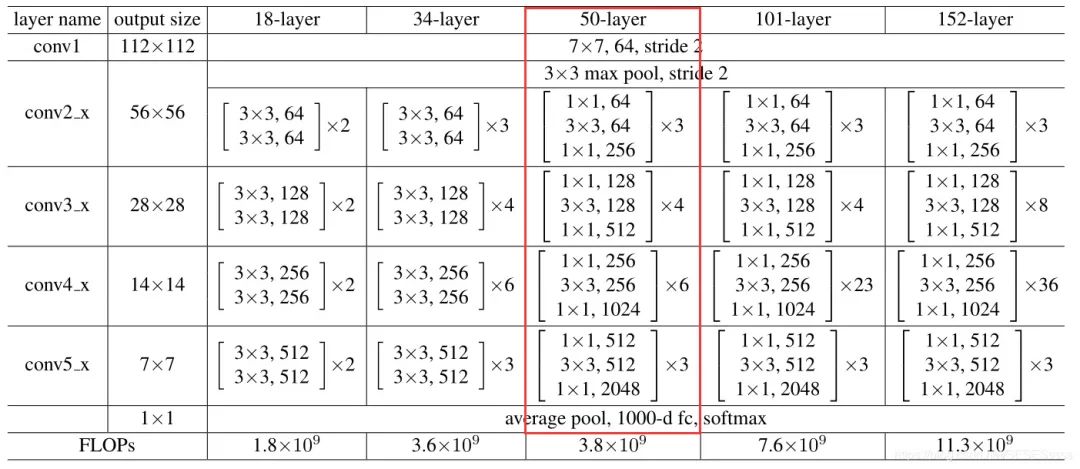
3.2.2 Bottleneck结构
论文中将Resnet-50分成了4个大的卷积组,每一个大的卷积组叫做一个Bottleneck(瓶颈)模块(输入和输出的特征图通道较多,中间的卷积层特征深度较浅,类似瓶颈的中间小两头大的结构)。卷积组与卷积组之间会通过一个shortcut相连。
左:非瓶颈结构,右:瓶颈结构
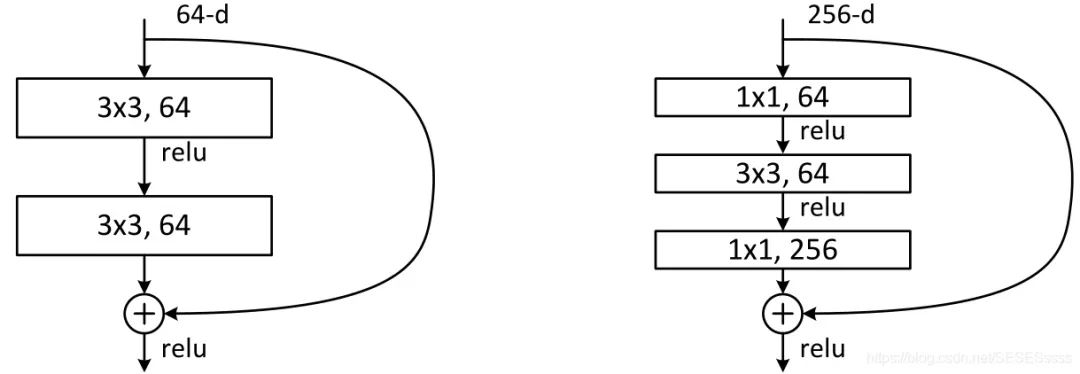
值得注意的是,ResNet使用Bottleneck结构主要是是为了减小网络的参数量(特征降维),在实际中作者注意到,瓶颈结构的使用同样出现了普通网络的退化问题:

3.2.3 ResNet-50图解及各层参数细节
对于F(x)+x,ResNet采取的是逐通道相加的形式,因此在相加时需要考虑两者的通道数是否相同,相同的情况直接相加即可(图实线处),若两者通道不同,需要用1x1卷积对特征进行升维,将通道数变为相同(图虚线处):
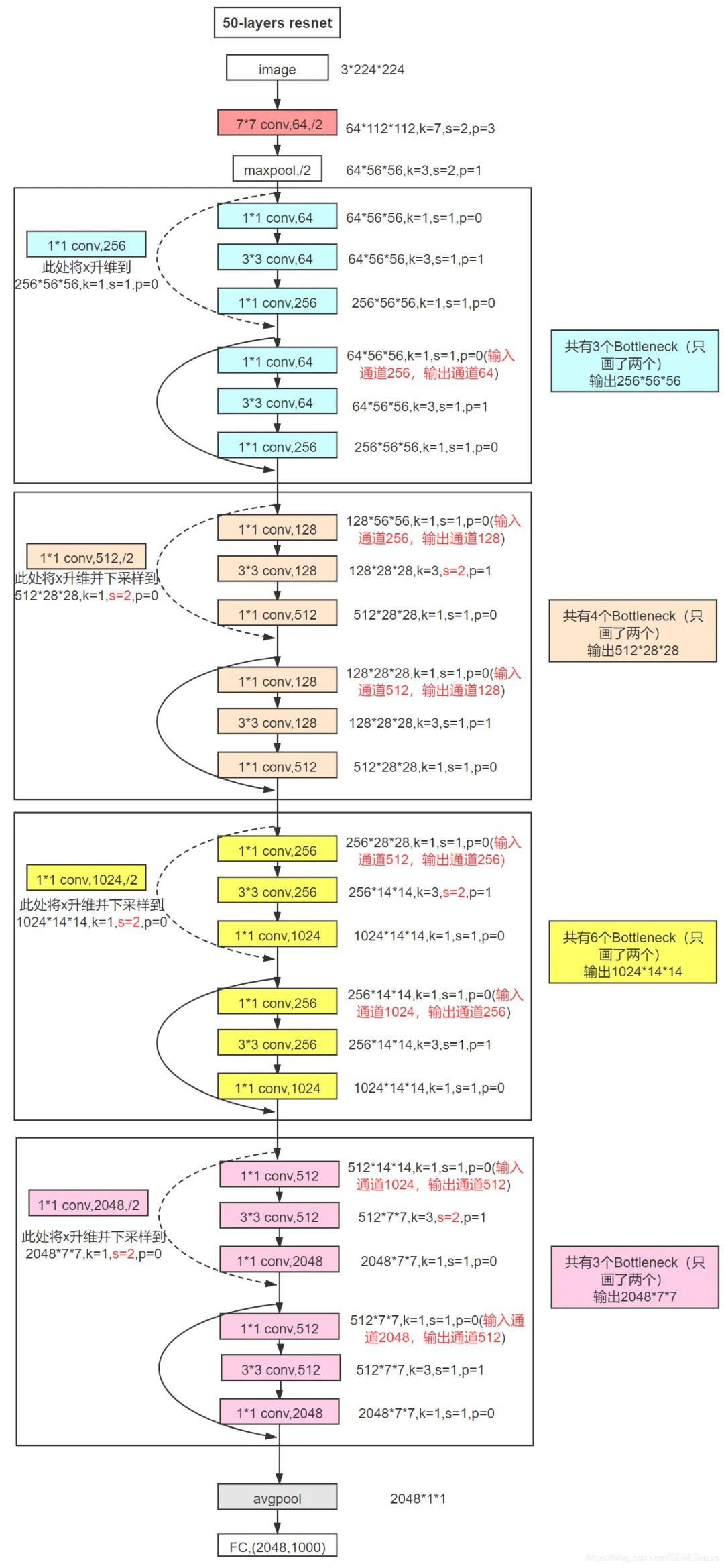
3.2.4 实现一个Bottleneck模块:
# 将Conv+BN封装成一个基础卷积类:
class BasicConv2d(nn.Module):
def __init__(self, in_channel, out_channel, kernel_size, stride=1, padding=0):
super(BasicConv2d, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel_size,
stride=stride, padding=padding, bias=False),
nn.BatchNorm2d(out_channel)
)
def forward(self, x):
x = self.conv(x)
return x
# 一个Bottleneck模块:
class Bottleneck(nn.Module):
def __init__(self, in_channel, mid_channel, out_channel, stride=1):
super(Bottleneck, self).__init__()
self.judge = in_channel == out_channel
self.bottleneck = nn.Sequential(
BasicConv2d(in_channel, mid_channel, 1),
nn.ReLU(True),
BasicConv2d(mid_channel, mid_channel, 3, padding=1, stride=stride),
nn.ReLU(True),
BasicConv2d(mid_channel, out_channel, 1),
)
self.relu = nn.ReLU(True)
# 下采样部分由一个包含BN层的1x1卷积构成:
if in_channel != out_channel:
self.downsample = BasicConv2d(
in_channel, out_channel, 1, stride=stride)
def forward(self, x):
out = self.bottleneck(x)
# 若通道不一致需使用1x1卷积下采样
if not self.judge:
self.identity = self.downsample(x)
# 残差+恒等映射=输出
out += self.identity
# 否则直接相加
else:
out += x
out = self.relu(out)
return out3.2.5 实现resnet-50
# Resnet50:
class ResNet_50(nn.Module):
def __init__(self, class_num):
super(ResNet_50, self).__init__()
self.conv = BasicConv2d(3, 64, 7, stride=2, padding=3)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
# 卷积组1
self.block1 = nn.Sequential(
Bottleneck(64, 64, 256),
Bottleneck(256, 64, 256),
Bottleneck(256, 64, 256),
)
# 卷积组2
self.block2 = nn.Sequential(
Bottleneck(256, 128, 512, stride=2),
Bottleneck(512, 128, 512),
Bottleneck(512, 128, 512),
Bottleneck(512, 128, 512),
)
# 卷积组3
self.block3 = nn.Sequential(
Bottleneck(512, 256, 1024, stride=2),
Bottleneck(1024, 256, 1024),
Bottleneck(1024, 256, 1024),
Bottleneck(1024, 256, 1024),
Bottleneck(1024, 256, 1024),
Bottleneck(1024, 256, 1024),
)
# 卷积组4
self.block4 = nn.Sequential(
Bottleneck(1024, 512, 2048, stride=2),
Bottleneck(2048, 512, 2048),
Bottleneck(2048, 512, 2048),
)
self.avgpool = nn.AvgPool2d(4)
self.classifier = nn.Linear(2048, class_num)
def forward(self, x):
x = self.conv(x)
x = self.maxpool(x)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
out = self.classifier(x)
return out4.FPN(特征金字塔)
4.1 特征的语义信息
对于CNN网络,图像通过网络浅层的卷积层,输出的特征图往往只能表示一些简单的语义信息(比如一些简单的线条),越深层的网络,提取特征表示的语义信息也就越复杂(从一些纹理,到一些类别具有的相似轮廓):(图中的特征有经过反卷积上采样)
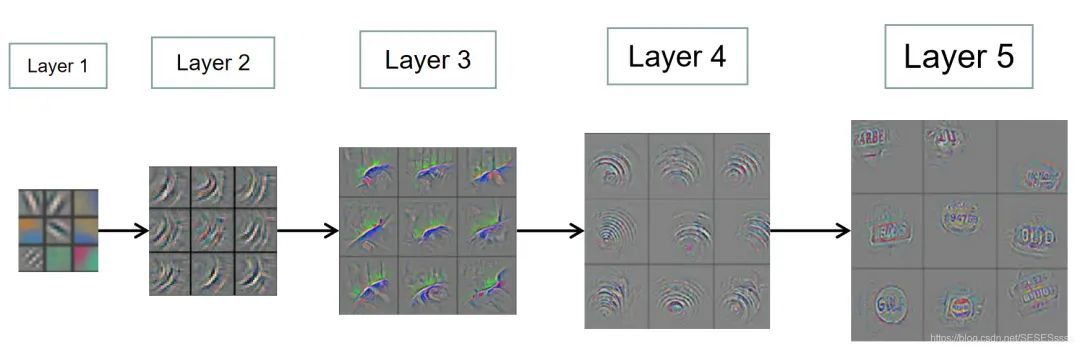
因此,传统的检测网络通常只在最后一个卷积输出上的高层语义特征图进行后续的步骤,但这也不可避免的存在一些问题。
4.2 改进
我们知道,越是深层的网络,特征的下采样率也就越高,即深层的特征图一个像素就对应浅层特征的一片区域,这对于大目标的检测不会造成太大的影响。但对于图像上的小目标,在深层特征上的有效信息较少,导致网络对于小物体的检测性能急剧下降,这种现象也被称作多尺度问题。
基于多尺度问题,一个直接的解决办法便是利用图像金字塔,将原始的输入变换为多张不同尺寸的多尺度图像,将这些图像分别进行特征提取,生成多尺度的特征后再进行后续的处理,这样一来,在小尺度的特征上检测到小目标的几率就大大增加。这种方法简单有效,曾大量在COCO目标检测竞赛上使用。但这种方法的缺点就在于计算量大,需要消耗大量的时间。
对此,FPN网络(Feature Pyramid Networks)针对这一问题改进了提取多尺度特征的方法。基于4.1的介绍我们知道,卷积网络不同层提取的特征尺寸各不相同,本身就类似于一个金字塔的结构,同时,每一层的语义信息也各不相同,越浅的特征语义信息越简单,显示的细节也就越多,越深层的特征显示的细节越少,语义信息越高级。基于此,FPN网络在特征提取的过程中融合了不同卷积层的特征,较好的改善了多尺度检测问题。
4.3 PyTorch 复现 FPN
4.3.1 FPN网络架构
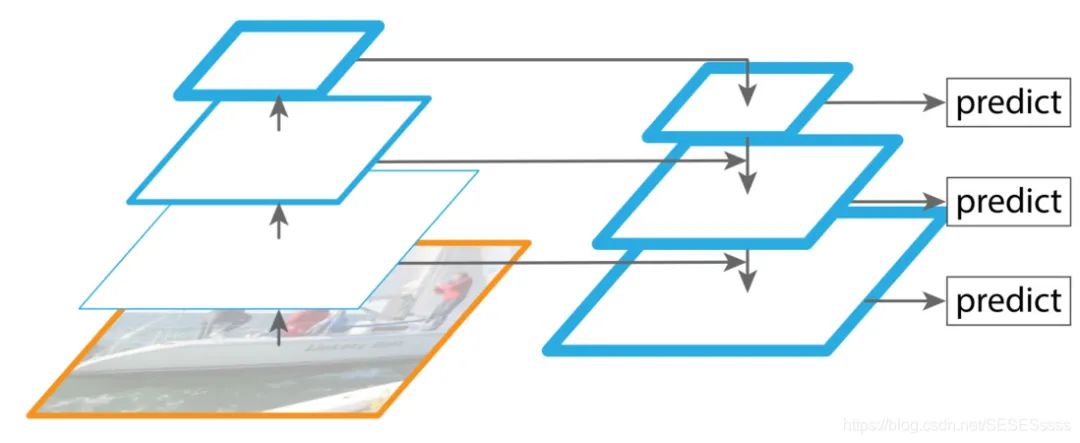
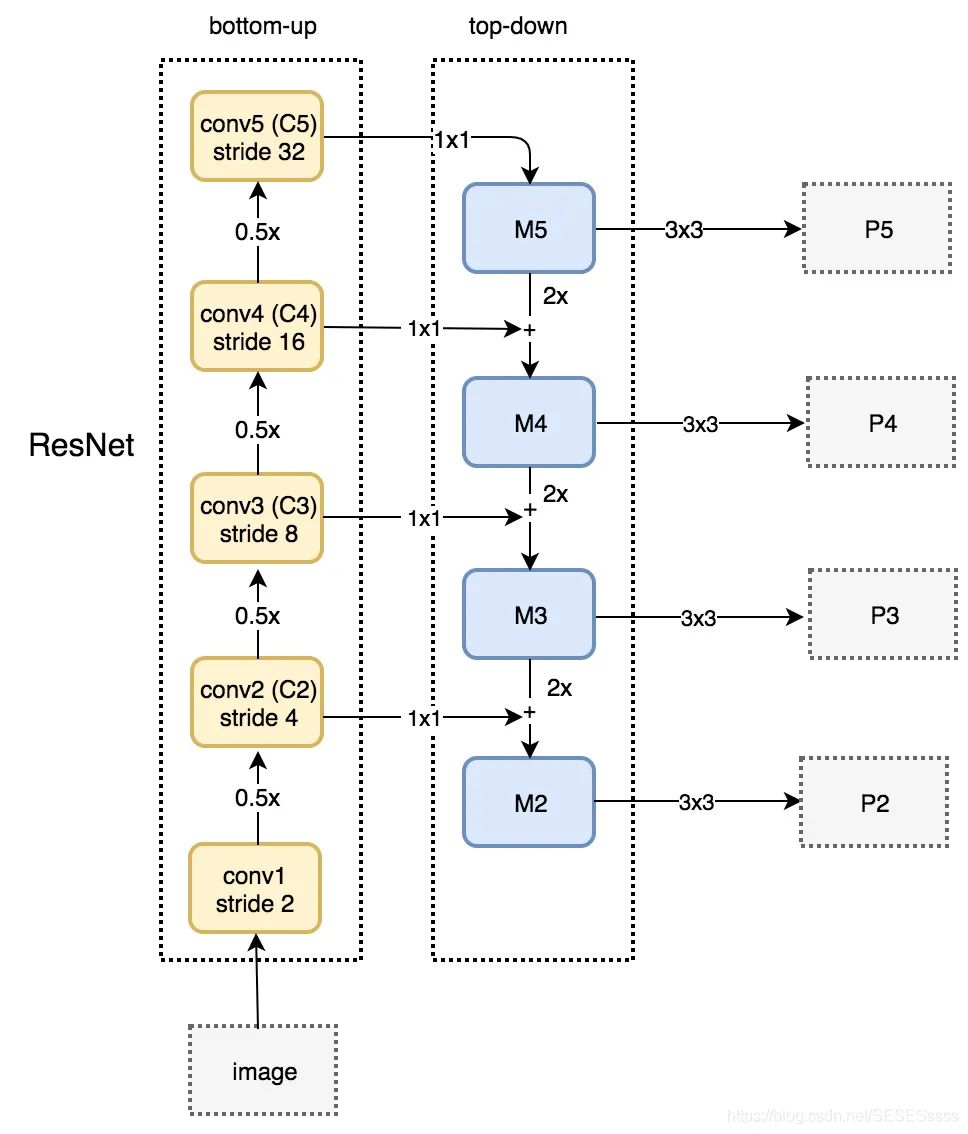
FPN网络主要包含四个部分,自下而上网络,自上而下网络,横向连接与卷积融合。
自下而上网络(提供不同尺度的特征):
最左侧为普通的特征提取卷积网络(ResNet),C2-C4代表resnet中的四个大的卷积组,包含了多个Bottleneck结构,原始图像的输入就从该结构开始。
自上而下网络(提供高层语义特征): 在这一结构中,首先对C5进行1x1卷积降低通道数得到M5,接着依次上采样得到M4,M3,M2.目的是得到与C4,C3,C2相同尺寸但不同语义的特征。方便特征的融合(融合的方式为逐元素相加)。
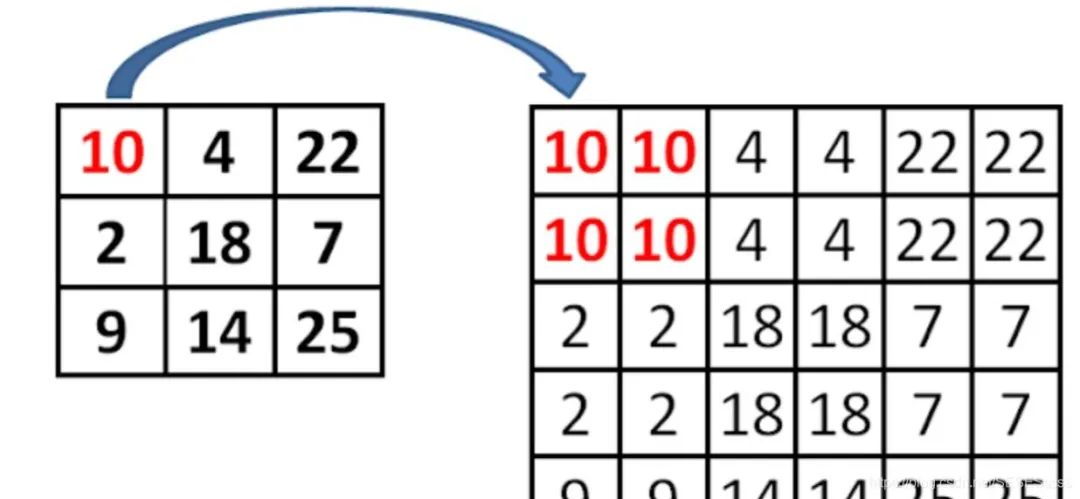
值得注意的是,在网络的上采样过程中采用的不是反卷积或者非线性插值方法,而是普通的2倍最邻近上采样(可以最大程度保留特征图的语义信息,得到既有良好的空间信息又有较强烈的语义信息的特征图。):【论文笔记】FPN —— 特征金字塔:https://zhuanlan.zhihu.com/p/92005927
横向连接:
将高层的语义特征与浅层的细节特征相融合(中途使用1x1卷积使得两者的通道数相同)
卷积融合:
得到相加的特征后,再利用3x3卷积对M2-M4进一步融合(论文表示这么做可以消除上采样带来的重叠效应)
4.3.2 复现FPN网络
# 导入resnet50
resnet = models.resnet50(pretrained=True)
# 分块, 以便提取不同深度网络的特征
layer1 = nn.Sequential(
resnet.conv1,
resnet.bn1,
resnet.relu,
resnet.maxpool,
)
layer2 = resnet.layer1
layer3 = resnet.layer2
layer4 = resnet.layer3
layer5 = resnet.layer4
class FPN(nn.Module):
def __init__(self):
super(FPN, self).__init__()
# 3x3 卷积融合特征
self.MtoP = nn.Conv2d(256, 256, 3, 1, 1)
# 横向连接, 使用1x1卷积降维
self.C2toM2 = nn.Conv2d(256, 256, 1, 1, 0)
self.C3toM3 = nn.Conv2d(512, 256, 1, 1, 0)
self.C4toM4 = nn.Conv2d(1024, 256, 1, 1, 0)
self.C5toM5 = nn.Conv2d(2048, 256, 1, 1, 0)
# 特征融合方法
def _upsample_add(self, in_C, in_M):
H = in_M.shape[2]
W = in_M.shape[3]
# 最邻近上采样方法
return F.upsample_bilinear(in_C, size=(H, W)) + in_M
def forward(self, x):
# 自下而上
C1 = layer1(x)
C2 = layer2(C1)
C3 = layer3(C2)
C4 = layer4(C3)
C5 = layer5(C4)
# 自上而下+横向连接
M5 = self.C5toM5(C5)
M4 = self._upsample_add(M5, self.C4toM4(C4))
M3 = self._upsample_add(M4, self.C3toM3(C3))
M2 = self._upsample_add(M3, self.C2toM2(C2))
# 卷积融合
P5 = self.MtoP(M5)
P4 = self.MtoP(M4)
P3 = self.MtoP(M3)
P2 = self.MtoP(M2)
# 返回的是多尺度特征
return P2, P3, P4, P5如发现本文中存在任何错误或是有不解的地方,欢迎在评论区留言~
往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载中国大学慕课《机器学习》(黄海广主讲)机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码:














 386
386











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









