






✦
什么是OCR
✦
OCR(optical character recognition)文字识别是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、用户界面的友好性,产品的稳定性,易用性及可行性等。
✦
推荐框架
✦
PaddleOCR
PaddleOCR是飞浆开源的文字识别的模型套件,其主要目标是打造丰富、领先、实用的文本识别模型/工具库,其中最新开源的超轻量PP-OCRv3模型大小仅为16.2M,同时支持中英文识别;支持倾斜、竖排等多种方向文字识别;支持GPU、CPU预测;用户既可以通过PaddleHub很便捷的直接使用该超轻量模型,也可以使用PaddleOCR开源套件训练自己的超轻量模型。
模型推荐:
1、ch_pp-ocrv3模型
PP-OCR是PaddleOCR自研的实用的超轻量OCR系统。在实现前沿算法的基础上,考虑精度与速度的平衡,进行模型瘦身和深度优化,使其尽可能满足产业落地需求。该系统包含文本检测和文本识别两个阶段,其中文本检测算法选用DB,文本识别算法选用CRNN,并在检测和识别模块之间添加文本方向分类器,以应对不同方向的文本识别。当前模块为PP-OCRv3,在PP-OCRv2的基础上,针对检测模型和识别模型,进行了共计9个方面的升级,进一步提升了模型效果。
模型名称 | ch_pp-ocrv3 |
类别 | 图像-文字识别 |
网络 | Differentiable Binarization+SVTR_LCNet |
数据集 | icdar2015数据集 |
是否支持Fine-tuning | 否 |
模型大小 | 13M |
2、Chinese_ocr_db_crnn_mobile模型
chinese_ocr_db_crnn_mobile用于识别图片当中的汉字。其基于https://www.paddlepaddle.org.cn/hubdetail?name=chinese_text_detection_db_mobile&en_category=TextRecognition 检测得到的文本框,继续识别文本框中的中文文字。之后对检测文本框进行角度分类。最终识别文字算法采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module是一个超轻量级中文OCR模型,支持直接预测。
3、Chinese_text_detection_db_server模型
Differentiable Binarization(简称DB)是一种基于分割的文本检测算法。在各种文本检测算法中,基于分割的检测算法可以更好地处理弯曲等不规则形状文本,因此往往能取得更好的检测效果。但分割法后处理步骤中将分割结果转化为检测框的流程复杂,耗时严重。DB将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。该Module是一个通用的文本检测模型,支持直接预测。
MMOCR
MMOCR 是基于 PyTorch 和 mmdetection 的开源工具箱,专注于文本检测,文本识别以及相应的下游任务,如关键信息提取。它是 OpenMMLab 项目的一部分。该工具箱提供了一套全面的实用程序,可以帮助用户评估模型的性能。它包括可对图像,标注的真值以及预测结果进行可视化的可视化工具,以及用于在训练过程中评估模型的验证工具。它还包括数据转换器,演示了如何将用户自建的标注数据转换为 MMOCR 支持的标注文件。
模型推荐:
1、ABINet 模型
ABINet模型主要围绕如何进行有效地建模语言这个问题展开了一些探索及讨论,总体上的思想就是从NLP字符级别拼写矫正的语言建模角度来思考场景文字识别问题,尤其是针对图像质量退化的这种场景文字识别。
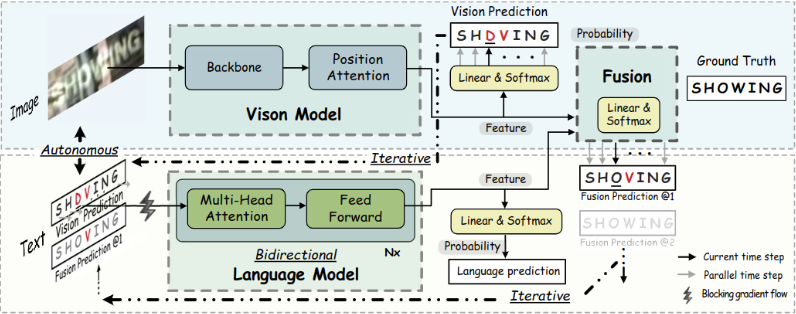
2、MASTER模型
MASTER模型主要是采用CNN+Transformer的方式实现文字识别,本模型的创新点主要在CNN中参考GCnet提出的multi-Aspect GCAttention在CNN部分进行的改进。

✦
常用trick
✦
OCR识别效果影响因素
图片质量不应过低,分辨率建议300dpi以上;
一般来说训练数据的数量和需要解决问题的复杂度有关系,其中难度越大,精度要求越高,其要求的数据量也就越大,所以一般情况下实际中运用的数据越多其对应的模型效果就相对越好;
针对存在背景干扰的文字,首先需要保证文字检测框准确,如果出现检测框不准确那么需要通过一定的途径进行图像预处理如颜色过滤、数据扩充等;同时在训练数据中加入多场景的背景干扰因素也可以提升模型效果;
如果OCR识别任务存在多语种并列的问题可以尝试“1个检测模型+1个N类分类模型+N个识别模型”的解决方案,即让不同类型的文本共用一个检测模型,N分类模型是指额外训练一个分类器,对文本类型进行分类,N种语言即是N分类,同时在识别的过程中,针对每个类型的文本单独训练识别模型。
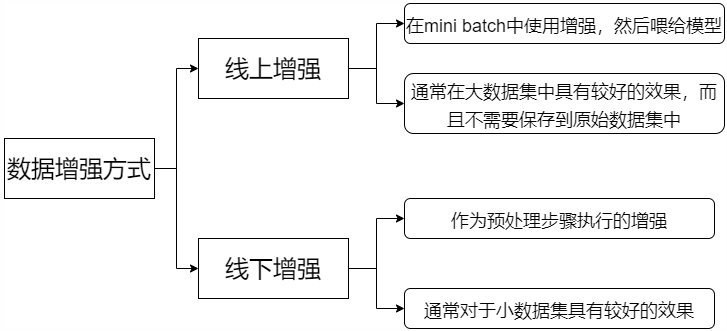
数据增强
深度学习中,数据增强是一种并不会改变模型结构的正则化方法,目前图像类数据增强库主要有skimage、opencv、imgaug、Albumentations、Augmentor、Keras(ImageDataGenerator)、SOLT、torchvision(transforms),通过对数据进行增强可以提升模型最终的训练效果,而数据增强的方法主要有以下两种:
Albumentations库
此处主要以Albumentations库进行介绍数据增强的方式,albumentations可以对数据集进行逐像素的转换,譬如图像模糊、图像下采样、高斯处理、旋转、随机雾化、RGB转换等,部分支持方法如下表所示:
Transform | Image | Masks | BBoxes | Keypoints |
Affine | √ | √ | √ | √ |
CenterCrop | √ | √ | √ | √ |
CoarseDropout | √ | √ | _ | √ |
Crop | √ | √ | √ | √ |
CropAndPad | √ | √ | √ | √ |
CropNonEmpty -MaskIfExists | √ | √ | √ | √ |
ElasticTransform | √ | √ | _ | _ |
Cutout
Cutout是一种新的正则化方法,其工作原理是在训练时随机将图片的一部分减掉,这样一定程度上能够提高模型的鲁棒性,该算法是来源于计算机视觉任务中物体遮挡的情况,通过该算法可以快速生成一些类似被遮挡的目标物体,这样不仅可以让模型在遮挡场景中具备更好的适应能力,也可以实现模型在做决策时可以充分考虑不同环境场景下的影响。
Mixup
Mixup是一种新的数据增强的方法,简单来说就是每次取出2张图片,然后将其线性组合得到新的图片,以此作为新的训练样本,进行网络训练。Mixup方法主要增强了训练样本之间的线性表达,同时也增强了网络的泛化能力,不过mixup的缺点是需要相对较长的时间进行收敛。
模型优化
一般我们使用现有的预训练模型来训练算法时往往会忽略超参数的优化,只使用原始参数进行处理,虽然原始参数已经可以得到较好的结果,但是如果可以根据实际的赛题进行个性化优化,那么无疑会得到更高的精度。
模型学习率以及权重初始化
深度学习中的权重初始化对于模型的收敛速度以及模型的预测精度有着很重要的作用,参数在模型刚开始训练过程中并不能全部初始化为0,因为如果模型刚开始训练全部初始化为0那么所有的神经元的输出都将是完全相同的,那么在反向传播时同一层多的神经元的行为也将会是一致的。
模型学习率影响模型训练过程中的收敛与否,一个较为合理的学习率可以促进模型训练过程中的快速收敛,而一个不太理想的学习率可能会导致模型损失值爆炸,从而导致模型精度不理想,所以一般来说,在训练模型时不宜设置较大的学习率,以0.01,0.001为宜。当然我们也可以采用动态优化学习率的方法或者直接采用预训练模型中的默认学习率进行训练模型,因为模型中的默认学习率往往都是经历过实验验证的。
学习率的调整方法:
-
从自己和竞赛中的经验来看,学习率可以设置为0.1,0.05,0.001,0.0001,0.005等,具体的设置需要结合数据集的真实情况进行对比判断,但是一般来说,学习率越小,模型收敛速度越慢,但是能将loss降到更低;
根据数据集的大小来选择合适的学习率,如果此处使用平方和误差(SSE)作为损失函数时,数据量越大,学习率应该设置的越小;
一般来说训练全过程并不是使用一个固定值作为全局的学习速度,而是随之视觉的推移采用动态的学习率,这种方式一般在pytorch、tensorflow中都有很直接的设置动态学习率的方式。
标签平滑(label smoothing)
标签平滑时一种损失函数的修正算法,同时该算法也被证明在训练深度学习网络中有效。在传统的分类计算损失函数任务中,通常是将真实的标签one hot形式与神经网络的输出做相应的交叉熵计算,而label smoothing 则是将真实标签的one hot形式做一个标签平滑的处理,这样可以避免网络学习的标签的hard label,而变成一个有概率的soft label,这样其在类别对应的位置其概率最大,而在其他位置的概率则是个非常小的数值。简单来说就是降低我们对标签的信任,实现对模型的约束,降低模型的过拟合程度。
指数移动平均(EMA)
指数移动平均(Exponential Moving Average)也叫权重移动平均(Weighted Moving Average),是一种赋予近期数据较大权重的平均方法。
一般来说移动平均可以看作是取变量过去一段时间的均值,所以相较于对变量直接赋值的操作,移动平均得到的值在图像上更加平滑,抖动性更小,并不会因为某次的异常值而使其整体趋势波动较大。
初始化指数移动平均时,需要提供一个衰减率(decay)。衰减率决定了模型的更新速度,每次变量更新时,影子变量也会进行更新,关于指数移动平均的算法细节可以在网上查找,本处主要是介绍此方法对深度学习训练的优势,ema并不参与实际的训练流程,而是在测试阶段发挥作用。
对抗训练
对抗训练的基本配置是生成器和判别器,其中生成器希望能够生成一些可以欺骗过判别器的样本,让判别器无法正确判别样本,而判别器需要不断增强自身的识别能力,从而可以尽可能的正确识别生成器生成的样本,在整个相互作用下,可以得到一个很好的判别器。
一句话形容对抗训练的思路,就是在输入上进行梯度提升,也就是增大loss,在参数上进行梯度下降,也就是减少loss,所以对抗训练的优化方向就是得到更优的扰动以及提升训练速度。
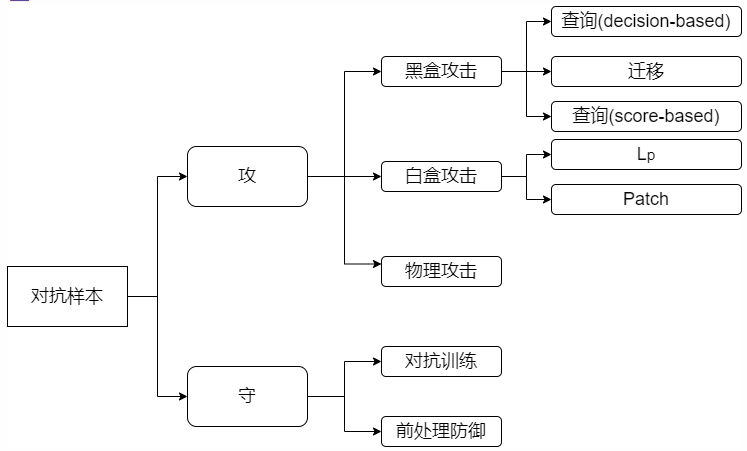
一般我们常用的对抗训练算法主要有FGSM(Fast Gradient Sign Method)、FGM(Fast Gradient Method)、PGD (Projected Gradient Descent)、FreeAT (Free Adversarial Training)、YOPO (You Only Propagate Once)、FreeLB (Free Large-Batch)、SMART (SMoothness-inducing Adversarial Regularization)。
— End —

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码














 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









