



 本文介绍了Anthropic发布的Claude3系列模型,该模型在多模态、语言能力等方面全面超越GPT-4,尤其在处理复杂任务时展现出接近人类的水平。文章还提到大模型训练的新进展,如多模态情感分析、知识图谱增强和模型微调方法,以及未来企业应用的潜力。
本文介绍了Anthropic发布的Claude3系列模型,该模型在多模态、语言能力等方面全面超越GPT-4,尤其在处理复杂任务时展现出接近人类的水平。文章还提到大模型训练的新进展,如多模态情感分析、知识图谱增强和模型微调方法,以及未来企业应用的潜力。
2024年,大模型再次卷疯了!就在近日,Anthropic发布的Claude 3系列模型,已经实现了对GPT-4的全面超越。
大模型(LLMs)是一种人工智能模型,旨在理解和生成人类语言。大模型通过在大量的文本数据上进行训练,可以执行广泛的任务,包括文本总结、翻译、情感分析等等。
为了更好地让大家了解大模型时下爆火热点并抓住机遇,我们邀请顶会审稿人/workshop、高校教授/博导、大厂算法研究员等大牛联合授课,带来2024年最新大模型系列课程合集,限时免费领!
扫码免费领取课程
赠200+大模型论文合集&精选论文带读课程

(文末福利)
授课ppt&论文合集部分展示
系列课程概览
01 大模型时代的多模态情感分析
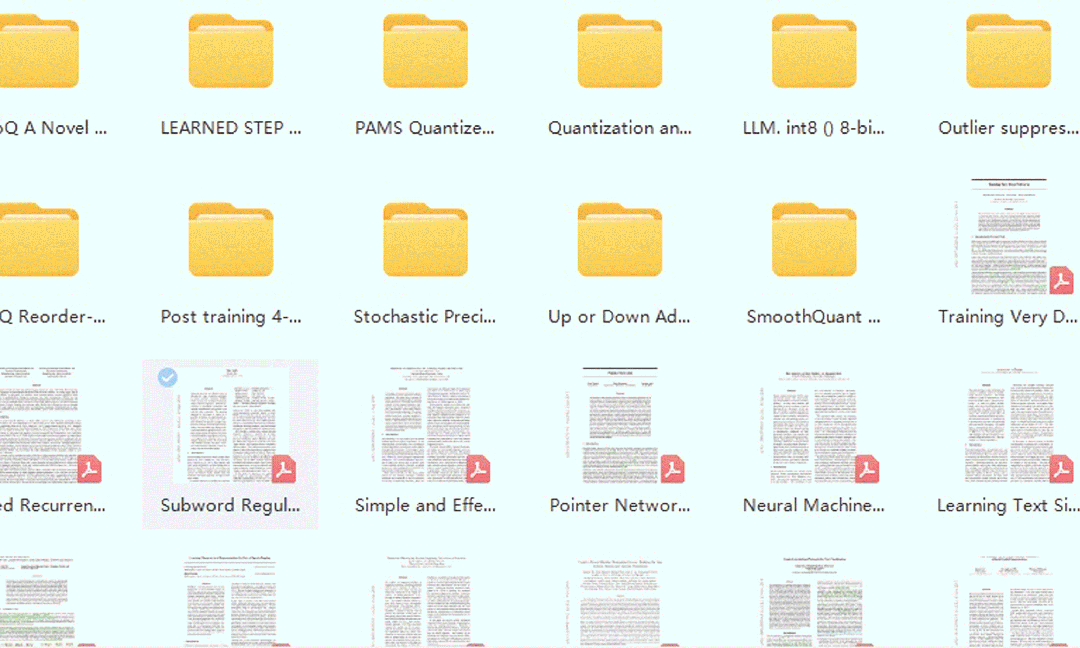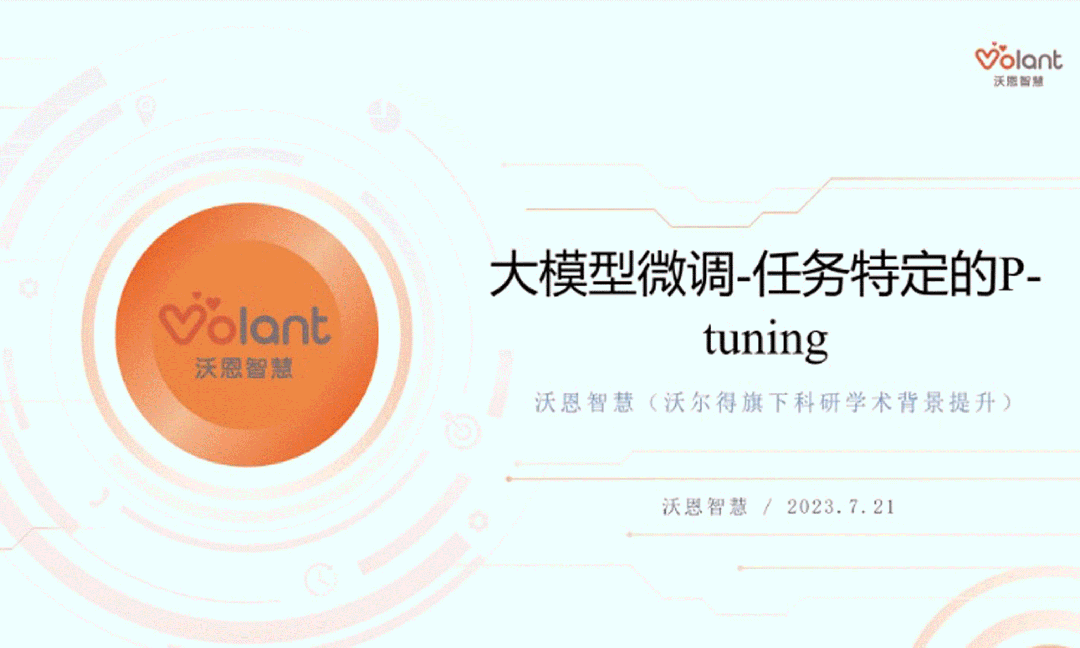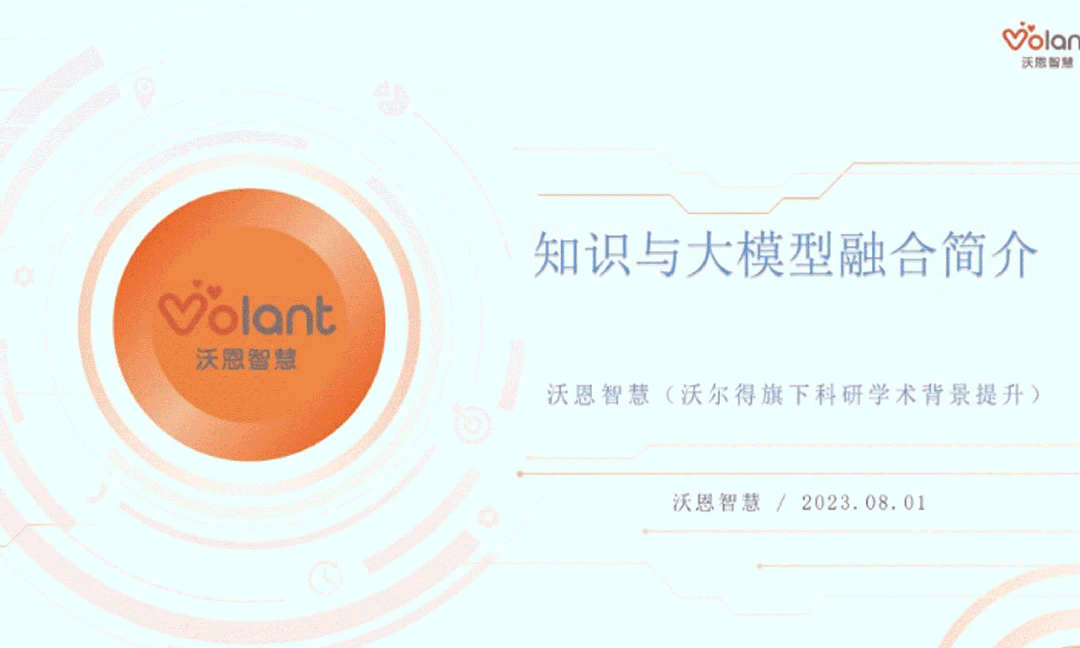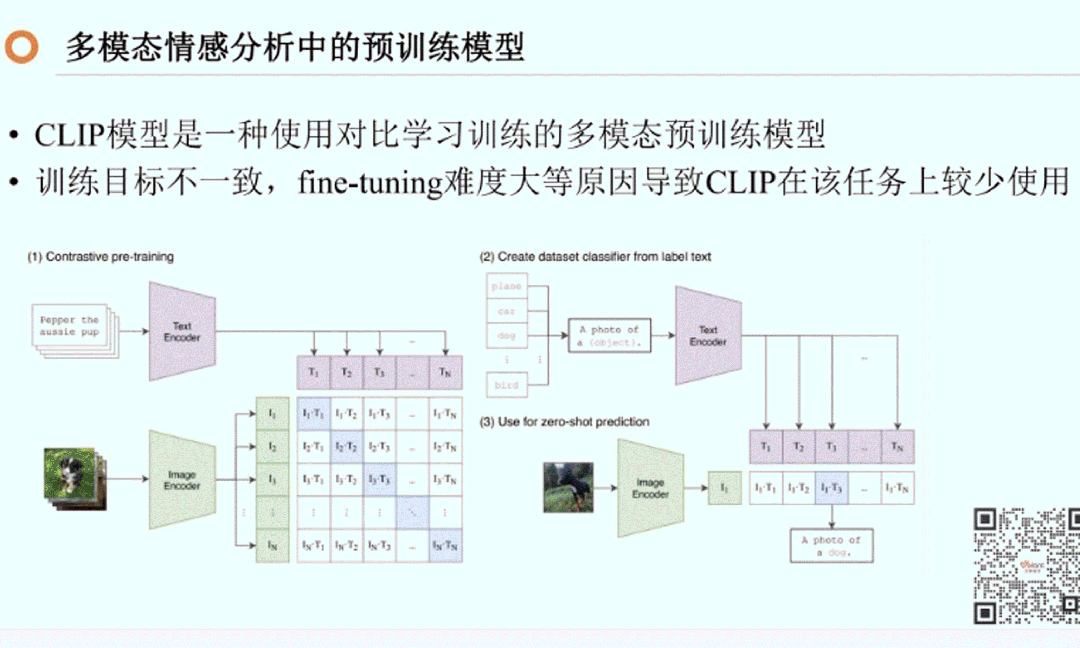
1.多模态情感分析中的预训练大模型介绍
2.针对多模态情感分析的大模型训练
3.使用大模型的多模态情感分析案例研究
02 多模态学习-大模型开启AI新时代
1.如何快速训练自己的多模态AI大模型
2.后AI时代,多模态的研究方向和热点
03 惊艳的大模型高效参数微调法
1.大模型微调-任务特定的P-tuning
2.大模型微调-任务/模型无关的LORA
3.大模型微调方法-Peft库使用实践(实战篇)
04 知识图谱增强的LLM
1.知识图谱组成要素及其分类
2.知识图谱和 LLM 融合路线3.知识图谱增强 LLM 的方法
05惊艳的文本生成视频大模型
1.目前主流视频生成模式
2.主流模式的缺点
3.工作原理及优点

扫码免费领取课程
赠200+大模型论文合集&精选论文带读课程

LLM 带来的巨大进步,所能产生的效果是之前我们大多数人都没有能预见到的。究其原因,一是使用大数据大模型大算力,规模带来了质的变化。ChatGPT 有 175B 参数,300B 的 token 做训练。而之前的模型参数规模超过 1B 的都不多。二是 Open AI 开发出了一套调教大模型的方法,包括基本步骤、技巧和工程实现。利用语言建模的机制将人的知识和能力输入给大模型。大规模系统的工程实现和模型的调教方法成了 Open AI 的核心竞争力。这一点可以从相关技术的演进过程中看出。
Anthropic发布了最新的Claude 3系列模型,一句话评价:真·全面碾压GPT-4!
多模态和语言能力指标上,Claude 3都赢麻了。用Anthropic的话说,Claude 3系列模型在推理、数学、编码、多语言理解和视觉方面,都树立了新的行业基准!

Opus,是Claude 3系列中最先进的模型。
它在多项AI系统常用评估标准,包括本科级别专业知识(MMLU)、研究生级别专家推理(GPQA)、基础数学(GSM8K),均取得领先业界LLM的性能。尤其是,Opus在处理复杂任务时,展现了几乎与人类相媲美的理解和表达能力,是AGI领域的领跑者。Claude 3系列模型在分析预测、创建细微内容、代码生成,以及用西班牙语、日语、法语等非英语语言交流的能力上都实现了显著进步。

Anthropic表示,LLM智能的潜力还远未被挖掘。
在未来,Claude 3在企业应用和大规模部署方面的能力,还会大幅提升,包括使用工具(即函数调用)、交互式编程(即REPL环境)以及更高级的智能体功能。扫码免费领取课程
赠200+大模型论文合集&精选论文带读课程


文末福利

给大家送一波大福利!我整理了100节计算机全方向必学课程,包含CV&NLP&论文写作经典课程,限时免费领!



立即扫码 赠系列课程
—END—


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









