






一、前言
最近因为有爬一些招聘网站的招聘信息的需要,而我之前也只是知道有“网络爬虫”这个神奇的名词,具体是什么、用什么实现、什么原理、如何实现比较好都不清楚,因此最近大致研究了一下,当然,研究的并不是很深入,毕竟一个高大上的知识即使站在巨人的肩膀上,也不能两三天就融会贯通。在这里先做一个技术储备吧,具体的疑难知识点、细节等以后一点一点的完善,如果现在不趁热打铁,以后再想起来恐怕就没印象了,那么以我的懒惰的性格估计就要抛弃对它的爱情了。废话不多说,让我们开始在知识的海洋里遨游吧。哎,等等,说到这我突然想到昨天新记的一首诗感觉挺好,给大家分享一下,缓解一下气氛,再给大家讲爬虫吧:
君生我未生,我生君已老 君恨我生迟,我恨君生早
君生我未生,我生君已老 恨不生同时,日日与君好
我生君未生,君生我已老 我离君天涯,君隔我海角
我生君未生,君生我已老 化蝶去寻花,夜夜栖芳草
二、什么是网络爬虫
是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
三、优点
简单易理解,管理方便。
四、WebMagic总体架构
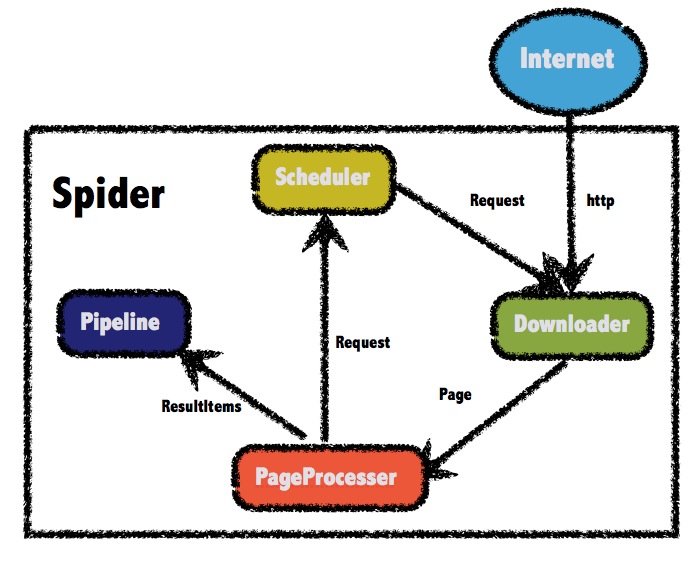
五、如何用WwbMagic
1.5.1 WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。
1.5.2 爬虫项目简单例子
依赖:
1 <dependency> 2 <groupId>us.codecraft</groupId> 3 <artifactId>webmagic-core</artifactId> 4 <version>0.6.1</version> 5 </dependency> 6 <dependency> 7 <groupId>us.codecraft</groupId> 8 <artifactId>webmagic-extension</artifactId> 9 <version>0.6.1</version> 10 </dependency>
简单代码:
1 import us.codecraft.webmagic.Page; 2 import us.codecraft.webmagic.Site; 3 import us.codecraft.webmagic.Spider; 4 import us.codecraft.webmagic.processor.PageProcessor; 5 6 public class GithubRepoPageProcessor implements PageProcessor { 7 8 private Site site = Site.me().setRetryTimes(3).setSleepTime(100); 9 10 @Override 11 public void process(Page page) { 12 page.addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all()); 13 page.putField("author", page.getUrl().regex("https://github\\.com/(\\w+)/.*").toString()); 14 page.putField("name", page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString()); 15 if (page.getResultItems().get("name")==null){ 16 //skip this page 17 page.setSkip(true); 18 } 19 page.putField("readme", page.getHtml().xpath("//div[@id='readme']/tidyText()")); 20 } 21 22 @Override 23 public Site getSite() { 24 return site; 25 } 26 27 public static void main(String[] args) { 28 Spider.create(new GithubRepoPageProcessor()).addUrl("https://github.com/code4craft").thread(5).run(); 29 }
如果仔细分析这段代码的逻辑,将其弄明白了,那么对于一个简单的爬虫项目,你就可以自己写了。
addUrl是定义从哪一个页面开始爬取;
addTargetRequests(page.getHtml().links().regex("(https://github\\.com/\\w+/\\w+)").all());是指定抓取html页面的符合此正则表达式的所有链接url;
page.getHtml().xpath("//h1[@class='entry-title public']/strong/a/text()").toString是指定抓取h1标签下的class属性值为entry-title public的子标
签strong下的a标签下的文本内容;
tidyText()所有的直接和间接文本子节点,并将一些标签替换为换行,使纯文本显示更整洁。当然这也就要求大家也要对正则表达式熟悉了。本文用的是xsoup,Xsoup是
基于Jsoup开发的一款XPath 解析器,之前WebMagic使用的解析器是HtmlCleaner,使用过程存在一些问题。主要问题是XPath出错定位不准确,并且其不太合理的代码结构
,也难以 通过注解将值赋给model属性的实体类:
1 @TargetUrl("https://github.com/\\w+/\\w+") 2 @HelpUrl("https://github.com/\\w+") 3 public class GithubRepo { 4 5 @ExtractBy(value = "//h1[@class='entry-title public']/strong/a/text()", notNull = true) 6 private String name; 7 8 @ExtractByUrl("https://github\\.com/(\\w+)/.*") 9 private String author; 10 11 @ExtractBy("//div[@id='readme']/tidyText()") 12 private String readme; 13 }
提示:
HelpUrl/TargetUrl是一个非常有效的爬虫开发模式,TargetUrl是我们最终要抓取的URL,最终想要的数据都来自这里;而HelpUrl则是为了发现这个最终URL,我们需要访问的页面。几乎所有垂直爬虫的需求,都可以归结为对这两类URL的处理:- 对于博客页,HelpUrl是列表页,TargetUrl是文章页。
- 对于论坛,HelpUrl是帖子列表,TargetUrl是帖子详情。
- 对于电商网站,HelpUrl是分类列表,TargetUrl是商品详情。
模拟浏览器请求:
1 public VideoSpider(String url, String proxyStr) { 2 this.client_url = url; 3 String[] tmp = proxyStr.split(":"); 4 HttpHost proxy = new HttpHost(tmp[1].substring(2), Integer.parseInt(tmp[2]), tmp[0]); 5 Site site = Site.me().setRetryTimes(3).setHttpProxy(proxy).setSleepTime(100).setTimeOut(10 * 1000).setCharset("UTF-8") 6 .setUserAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.63 Safari/537.36"); 7 8 GPHttpClientDownloader downloader = new GPHttpClientDownloader(); 9 Request request = new Request(this.client_url); 10 11 this.setCookie(request, site, downloader); 12 this.setParameters(request, site, downloader); 13 }
中setUserAgent("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/31.0.1650.57 Safari/537.36"),jobInfoDaoPipeline, LieTouJobInfo.class)
是模拟火狐、苹果、谷歌等浏览器进行请求将通过实体类LieTouJobInfo来抓取指定的内容并通过数据库访问层jobInfoDaoPipeline将相关属性存入数据库。
六、思考
简单的爬虫用以上代码基本就可以实现,但是我们要知道,要想真正爬取自己想要的内容,还有一段很长的落要走。因为我们在抓取数据的时候要考虑到去重、动态页面的产生、快速的更新频率、巨大的数据量等等的问题。针对这些问题我们该怎么做才能有效简单的去解决,这是
一个特别值得探讨的问题。就先写到这吧,如果我研究的有进展了,足以在公司项目中稳定投入使用了,再来完善吧。下载:
最新版:WebMagic-0.6.1
Maven依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId> <version>0.6.1</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.6.1</version> </dependency> 文档:
- 中文: http://webmagic.io/docs/zh/
- English: http://webmagic.io/docs/en
源码:
- https://git.oschina.net/flashsword20/webmagic
- https://github.com/code4craft/webmagic














 1256
1256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









