







😎 作者介绍:我是程序员行者孙,一个热爱分享技术的制能工人。计算机本硕,人工制能研究生。公众号:AI Sun,视频号:AI-行者Sun
🎈
本文专栏:本文收录于《yolov8》系列专栏,相信一份耕耘一份收获,我会详细的分享yolo系列目标检测详细知识点,yolov1到yolov9全系列,不说废话,祝大家早日中稿cvpr
🤓 欢迎大家关注其他专栏,我将分享Web前后端开发、人工智能、机器学习、深度学习从0到1系列文章。 🖥
随时欢迎您跟我沟通,一起交流,一起成长、进步!
YOLO目标检测框架中的conv.py文件包含作用:
-
构建卷积网络:
conv.py文件定义了YOLO模型中使用的卷积层,这些层负责从输入图像中提取特征。它包括设置卷积核、步长(stride)、填充(padding)等参数,以及可能的批量归一化层和激活函数,如ReLU。 -
特征提取与处理:该文件实现了对输入图像进行特征提取和处理的整个流程。通过堆叠多个卷积层,YOLO能够学习从简单到复杂的特征表示,这对于目标检测至关重要。
-
网络配置与灵活性:
conv.py通常还提供了一种灵活的方式,用于配置网络结构,允许研究人员和开发者根据特定应用调整网络的深度和复杂性。此外,它可能包含用于初始化网络权重的函数,这对于训练过程和最终模型性能非常重要。
以下是使用Mermaid语法编写的YOLO conv.py构建流程图的一个修正和简化版本:
- 初始化网络:设置网络的基本参数。
- 配置卷积层:定义每个卷积层的属性。
- 多层:决定是否重复配置多层网络结构。
- 构建网络:根据配置构建整个网络。
- 特征提取:通过卷积层提取图像特征。
- 特征融合:将不同层的特征图进行融合。
- 边界框预测:在网络的最后进行边界框的预测。
- 添加层:如果需要多层,可以选择添加的层类型。
- 选择层类型:选择要添加的层是卷积层、激活层还是归一化层。
HIHIHI

后面将详细解析 conv.py 中的各个组件,了解这些模块如何共同作用,以提高检测性能和效率。
核心卷积模块
conv.py 文件定义了多个卷积模块,每个模块都有其独特的特点和应用场景。
1. Conv 类(注意yolov8里面conv=标准conv+bn)
Conv 类是 conv.py 中的基础卷积模块,它包含标准的卷积操作,后接批量归一化(Batch Normalization)和激活函数(Activation)。该类接受输入通道数 (c1)、输出通道数 (c2)、卷积核大小 (k)、步长 (s)、填充 (p)、组数 (g) 和扩张率 (d) 作为参数,并提供了一个默认的激活函数 nn.SiLU()。
卷积层(Conv Layer)简介:
卷积层是用于提取图像特征的层,它通过滤波器(或称为卷积核)在输入数据上滑动以产生特征图(feature maps)。每个卷积核负责提取一种特定的特征,例如边缘、角点或更复杂的纹理模式。
卷积层的关键参数:
- kernel_size: 卷积核的大小,例如3x3或5x5。
- in_channels: 输入特征图的通道数。
- out_channels: 输出特征图的通道数,通常与卷积核的数量相等。
- stride: 卷积核滑动的步长。
- padding: 边缘填充,用于控制输出特征图的大小。
卷积层的流程通常如下:
- 输入层:输入数据通常是图像或前一个卷积层的输出。
- 卷积核定义:每个卷积核都有特定的大小(如3x3或5x5)和深度(与输入数据的通道数相同)。
- 卷积运算:卷积核在输入数据上滑动(根据stride参数),计算卷积核与输入数据的局部区域的点积。
- 填充(Padding):如果需要,会在输入数据的边缘添加填充以控制输出特征图的大小。
- 步长(Stride):定义了卷积核移动的步长。
- 激活函数:卷积运算的结果通常会通过一个激活函数,如ReLU,以引入非线性。
- 输出层:生成的新特征图作为下一层的输入。
示例代码:
使用PyTorch实现的简单卷积层的例子:
import torch
import torch.nn as nn
# 定义一个简单的卷积神经网络
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 卷积层:输入通道为3(RGB图像),输出通道为16,卷积核大小为3x3,步长为1,填充为1
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
# 可以继续添加更多的层
# ...
def forward(self, x):
# 应用第一个卷积层,并激活ReLU函数
x = self.conv1(x)
x = torch.relu(x)
# 可以继续添加更多的操作
# ...
return x
# 实例化网络
net = SimpleCNN()
# 创建一个假的输入数据,例如一个32x32的RGB图像
input_tensor = torch.randn(1, 3, 32, 32) # 1个样本,3个通道,32x32像素
# 前向传播
output = net(input_tensor)
print(output.size()) # 输出结果将展示经过卷积层后张量的尺寸
2. Conv2 类
Conv2 类在 Conv 的基础上增加了一个额外的 1x1 卷积层,用于融合特征。这种设计允许模型在保持参数数量不变的情况下,捕获更丰富的特征表示。
在YOLO(You Only Look Once)目标检测框架中,conv2通常指的是二维卷积层,它是卷积神经网络中用于处理图像数据的基本构建块。conv2层负责在图像的二维平面上应用卷积操作,以提取特征。
conv2层的关键属性包括:
filters: 卷积核的数量,对应于输出特征图的数量。size: 每个卷积核的尺寸,例如(3, 3)。stride: 卷积核移动的步长,可以是单个数字或一对数字,例如(1, 1)。padding: 边缘填充,用于确定卷积核如何覆盖输入特征图的边缘部分。batch_normalize: 布尔值,指示是否对卷积层的输出应用批量归一化。activation: 应用的激活函数,如relu或leaky。
示例代码:
使用Darknet框架(YOLO的原始实现框架)风格的conv2层的示例代码。
// 假设我们正在定义一个YOLO的配置文件(.cfg),其中包含conv2层的定义
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
padding=1
activation=leaky
// 解释:
// 这个conv2层将执行以下操作:
// - 使用批量归一化(batch_normalize=1)
// - 应用32个大小为3x3的卷积核
// - 使用步长(stride)为1
// - 使用填充(padding)为1,以保持输出特征图与输入特征图大小相同
// - 使用leaky激活函数
YOLO配置文件中,这些层将被串联在一起,定义整个网络的结构。每个[convolutional]块后面可能会跟随其他类型的层,如[upsample]、[route]、[yolo]等。
在PyTorch中,可以使用nn.Conv2d来定义一个二维卷积层。
3. LightConv 类
LightConv 类是一个轻量级的卷积模块,它结合了 1x1 卷积和深度可分离卷积(Depthwise Separable Convolution),旨在减少计算量和模型大小,同时保持性能。
LightConv的关键特点:
- Mish激活函数:
LightConv通常与Mish激活函数一起使用,Mish是一个近期流行起来的激活函数,它结合了ReLU和Sigmoid的优点。 - 组卷积:
LightConv使用组卷积来减少参数数量和计算量,每个输入通道通过自己的卷积核,而不是所有输入通道共享同一个卷积核。 - 1x1卷积:在组卷积之后,
LightConv可能会使用1x1的卷积来整合特征。
示例代码:
使用PyTorch实现LightConv的示例代码:
import torch
import torch.nn as nn
class Mish(nn.Module):
def __init__(self):
super(Mish, self).__init__()
def forward(self, x):
return x * torch.tanh(nn.functional.softplus(x))
class LightConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, padding=1, groups=1):
super(LightConv, self).__init__()
# 组卷积层
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, groups=groups)
# 1x1 卷积层用于降维或升维
self.conv1x1 = nn.Conv2d(out_channels, out_channels, kernel_size=1, stride=1, padding=0)
# Mish激活函数
self.mish = Mish()
def forward(self, x):
x = self.conv(x)
x = self.mish(x)
x = self.conv1x1(x)
return x
# 示例:创建一个LightConv层
# 输入通道数为32,输出通道数为64
lightconv = LightConv(in_channels=32, out_channels=64)
# 创建一个假的输入数据,例如一个批量大小为1,通道数为32,尺寸为64x64的特征图
input_tensor = torch.randn(1, 32, 64, 64)
# 前向传播
output = lightconv(input_tensor)
print(output.size()) # 输出结果将展示经过LightConv层后张量的尺寸
这个示例中,LightConv类首先定义了一个组卷积层,其中groups参数设置为输入通道数,使得每个输入通道通过自己的卷积核。接着定义了一个1x1的卷积层,用于在组卷积后整合特征。最后,使用了Mish激活函数来引入非线性。
4. DWConv 类
DWConv 类实现了深度可分离卷积,这是一种有效的卷积变体,它首先对每个输入通道进行空间过滤,然后使用 1x1 卷积进行特征融合。这种设计在保持精度的同时减少了参数数量和计算复杂度。
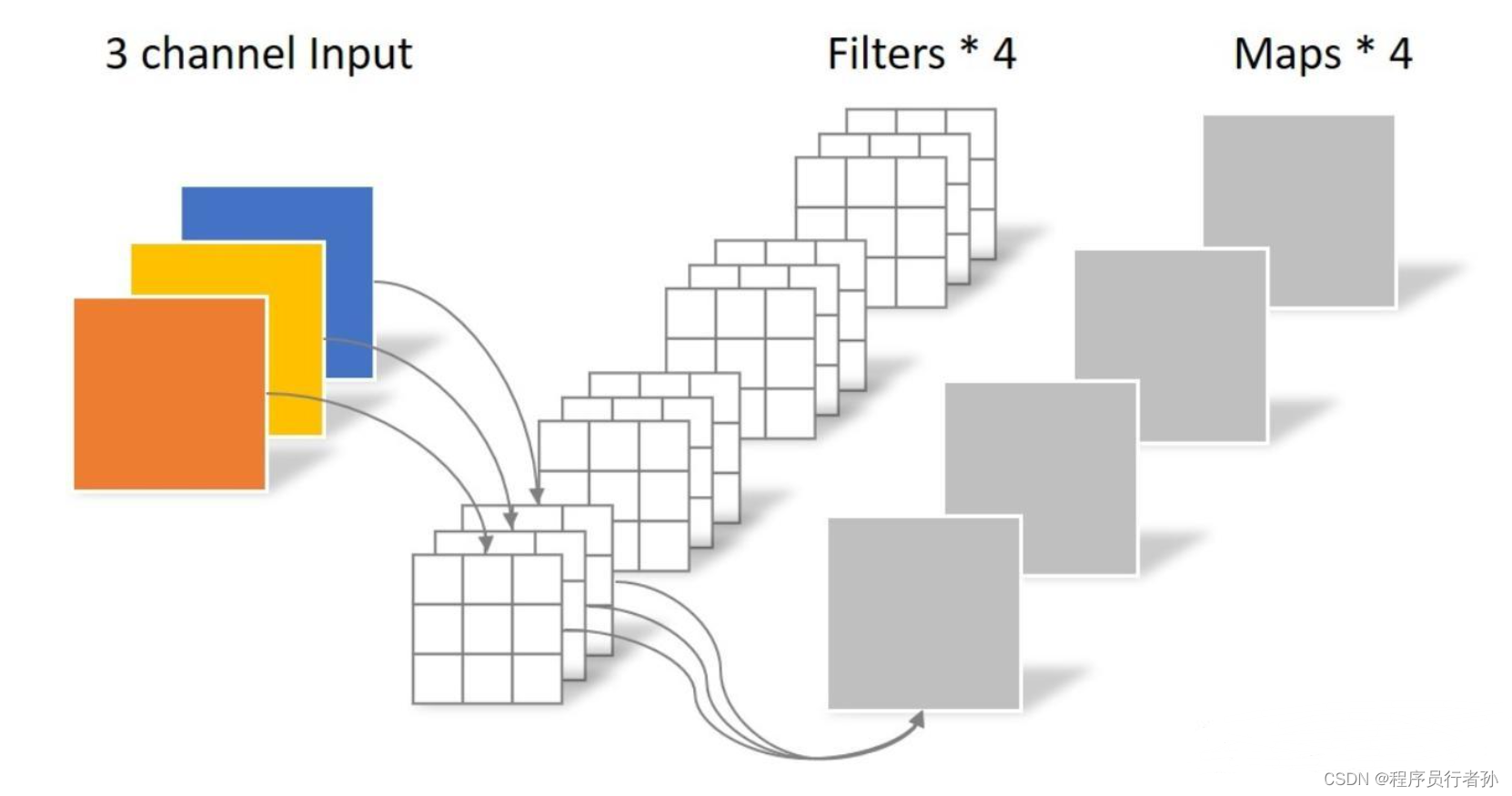
深度可分离卷积(DWConv)的两个步骤:
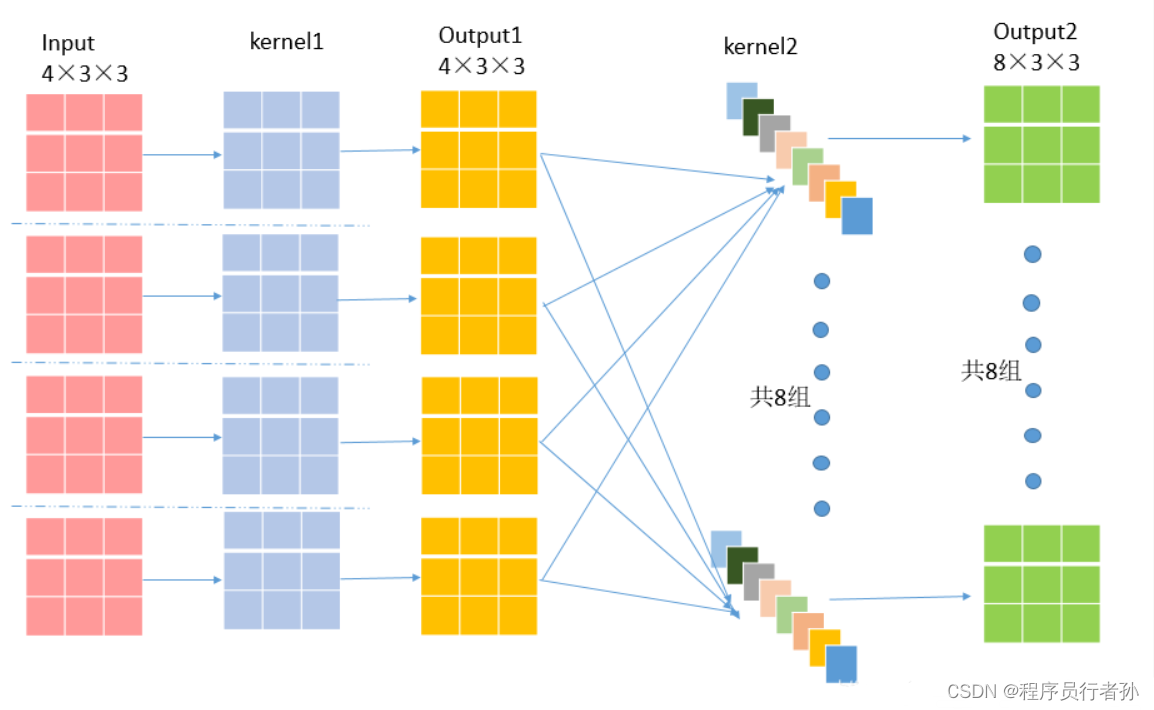
-
深度卷积(Depthwise Convolution):
- 在这一步中,每个输入通道通过自己的卷积核独立地进行卷积运算,生成深度特征图,每个深度特征图对应一个输入通道。
-
逐点卷积(Pointwise Convolution):
- 深度卷积的输出然后通过逐点卷积进行组合,其中使用1x1的卷积核将深度特征图的每个通道进行线性组合,生成最终的输出特征图。
示例代码:
以下是使用PyTorch实现DWConv的示例代码:
import torch
import torch.nn as nn
class DepthwiseConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1):
super(DepthwiseConv2d, self).__init__()
self.depthwise = nn.Conv2d(
in_channels=in_channels,
out_channels=in_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=in_channels,
bias=False
)
self.pointwise = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=False
)
def forward(self, x):
x = self.depthwise(x)
x = self.pointwise(x)
return x
# 示例:创建一个深度可分离卷积层
# 输入通道数为32,输出通道数为64,卷积核大小为3x3
dwconv = DepthwiseConv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1)
# 创建一个假的输入数据,例如一个批量大小为1,通道数为32,尺寸为64x64的特征图
input_tensor = torch.randn(1, 32, 64, 64)
# 前向传播
output = dwconv(input_tensor)
print(output.shape) # 输出结果将展示经过DWConv层后张量的尺寸
首先定义了一个DepthwiseConv2d类,它包含深度卷积和逐点卷积两个部分。深度卷积使用groups参数设置为输入通道数,以实现每个输入通道独立卷积的效果。逐点卷积则使用1x1的卷积核来组合深度卷积的输出。最后,我们创建了一个输入张量并通过DWConv层进行前向传播。
转置卷积模块
转置卷积(也称为反卷积)在网络的上采样和特征融合阶段扮演重要角色。
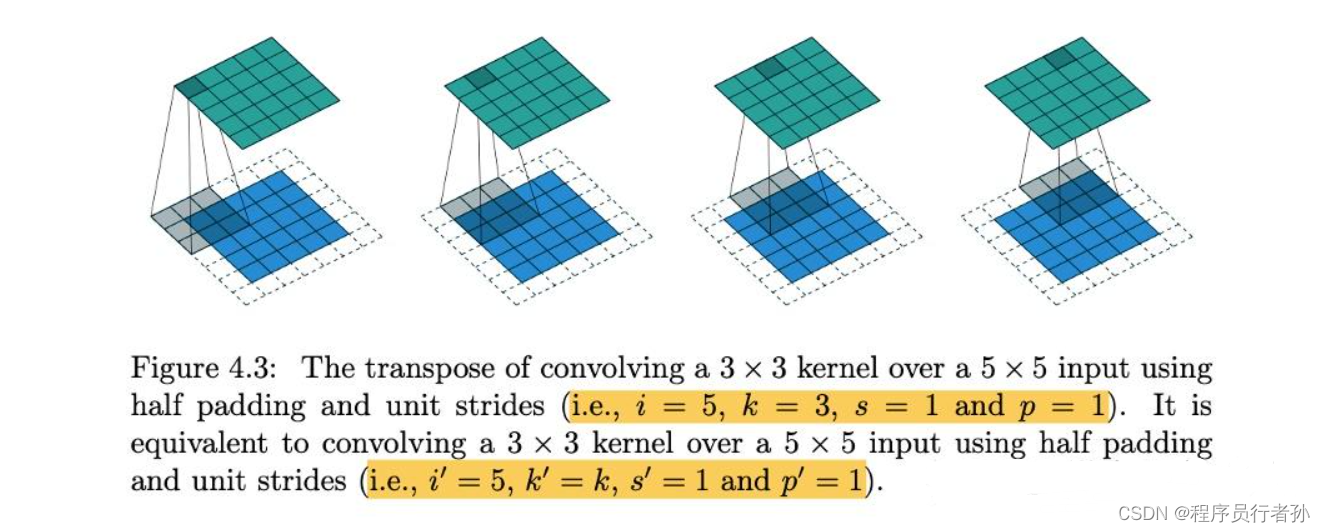
1. ConvTranspose 类
ConvTranspose 类定义了转置卷积层,并可选地包括批量归一化和激活函数。它允许网络在保持特征维度的同时增加特征的空间分辨率。
ConvTranspose的关键特点:
- 上采样:通过转置卷积可以增加特征图的尺寸。
- 学习性上采样:与简单的最近邻或双线性插值等上采样方法不同,转置卷积的上采样过程是可学习的,这意味着网络可以学习如何最好地重建特征。
- 步长:步长参数(
stride)定义了输出特征图相对于输入特征图的扩张程度。
示例代码:
使用PyTorch实现ConvTranspose的示例代码:
import torch
import torch.nn as nn
# 定义一个简单的转置卷积层
class DeconvolutionLayer(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=2, padding=0):
super(DeconvolutionLayer, self).__init__()
self.conv_transpose = nn.ConvTranspose2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding
)
def forward(self, x):
return self.conv_transpose(x)
# 创建转置卷积层实例
# 假设输入特征图的通道数为16,我们希望输出特征图的通道数为32
# 转置卷积的核大小为3x3,步长为2(这意味着输出特征图的尺寸将是输入的两倍)
deconv_layer = DeconvolutionLayer(in_channels=16, out_channels=32, kernel_size=3, stride=2, padding=1)
# 创建一个假的输入数据,例如批量大小为1,通道数为16,尺寸为64x64的特征图
input_tensor = torch.randn(1, 16, 64, 64)
# 前向传播
output = deconv_layer(input_tensor)
print(output.shape) # 输出结果将展示经过ConvTranspose层后张量的尺寸
我们定义了一个DeconvolutionLayer类,它包含一个ConvTranspose2d层。我们创建了一个输入张量并通过转置卷积层进行前向传播,输出的特征图尺寸将是输入特征图尺寸的两倍。
后面还有注意力模块和一些其他的新增模块

祝大家实验顺利,有效涨点~
以上是yolov8的conv.py解析,欢迎评论区留言讨论,如果有用欢迎点赞收藏文章,博主才有动力持续分享笔记!!!
免费资料获取
关注博主公众号,获取更多粉丝福利。



















 9661
9661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











