






今天跟大家分享一下Excel如何把符合多条件的多条数据全部提取出来。
如下图是某学校某次竞赛成绩表,现在想要将所有一年级2班的学生名单及成绩提取出来。
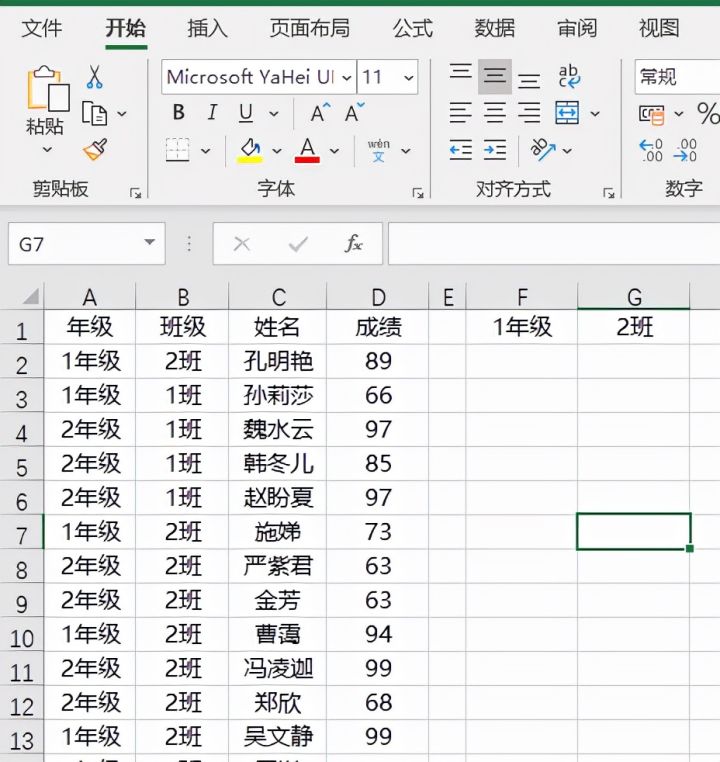
在F2单元格输入公式=INDEX(C:C,SMALL(IF(($A$2:$A$36=$F$1)*($B$2:$B$36=$G$1),ROW($2:$36),4^8),ROW(A1)))&""然后按下Ctrl+shift+enter三键结束,最后下拉填充直至出现空白单元格为止。
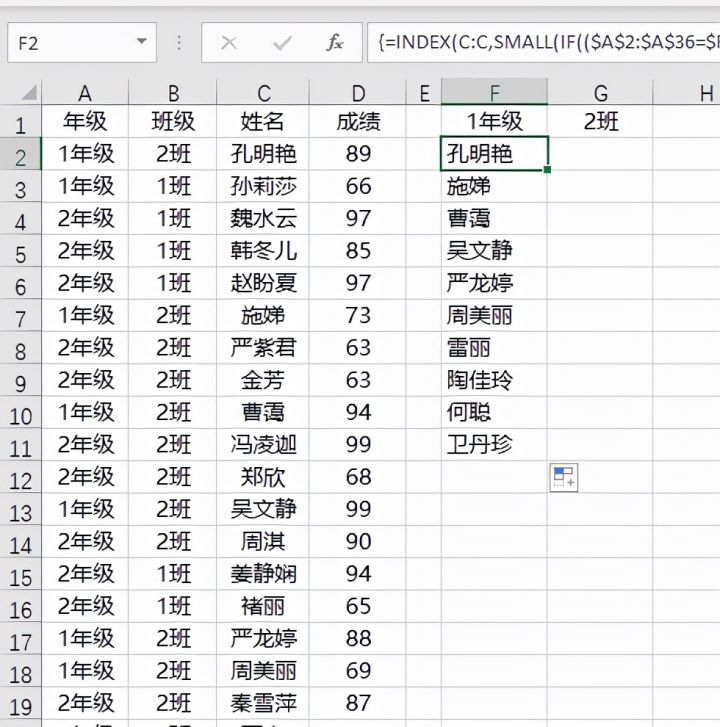
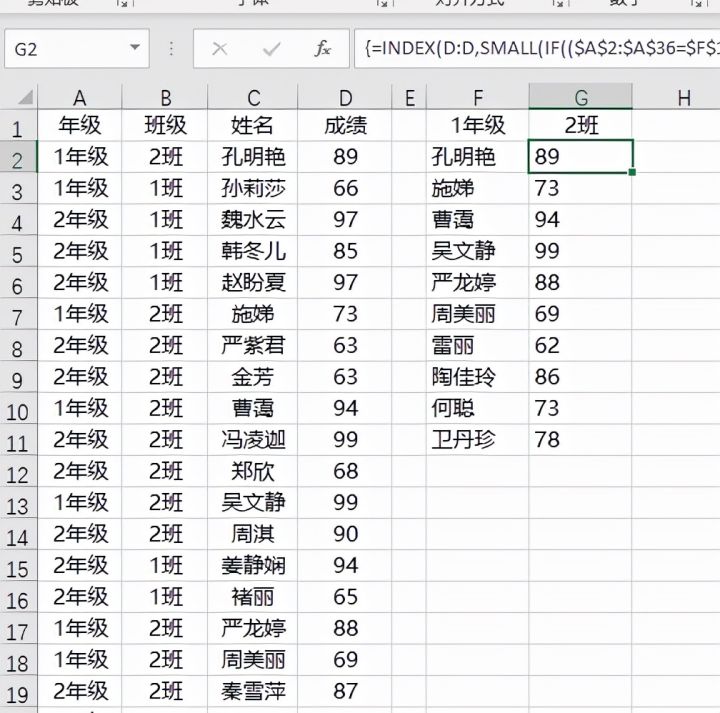
在G2单元格输入公式=INDEX(D:D,SMALL(IF(($A$2:$A$36=$F$1)*($B$2:$B$36=$G$1),ROW($2:$36),4^8),ROW(B1)))&""同样按下Ctrl+shift+enter三键结束,最后下拉填充直至出现空白单元格为止。这样就把1年级1班的学生名单及成绩全部提取出来了。
首先是if函数,它是Excel中常用的条件函数,根据指定的条件来判其“真”(TRUE)、“假”(FALSE),根据逻辑计算的真假值,从而返回相应的内容。可以使用函数 IF 对数值和公式进行条件检测

IF(($A$2:$A$36=$F$1)*($B$2:$B$36=$G$1),ROW($2:$36),4^8)在本文中的意思就是当年级为1年级且班级为2班时,返回其对应的行号,否则返回4^8的结果65536。最后得到一个有大量数字组成的内存数据组,为了方便大家理解我将这组数据放到E列中,如下图
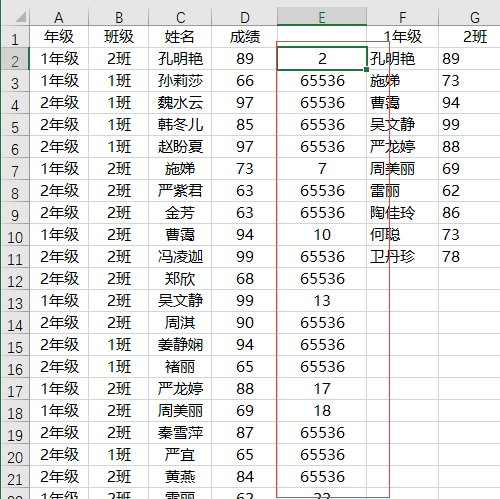
接着是SMALL函数和row函数,small函数作用是返回数据第K个最小值,row函数则是返回参数的行号。SMALL(IF(($A$2:$A$36=$F$1)*($B$2:$B$36=$G$1),ROW($2:$36),4^8),ROW(A1))则是依次返回上一步所说的内存数据组的第1,第2,第3……个最小值。在单元格中输入=SMALL($E$2:$E$36,ROW(A1))其返回结果如下图。
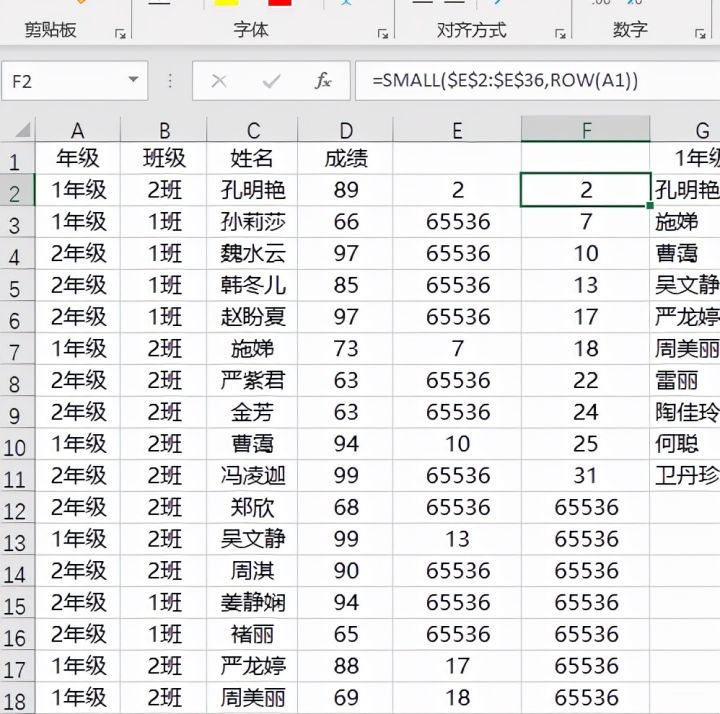
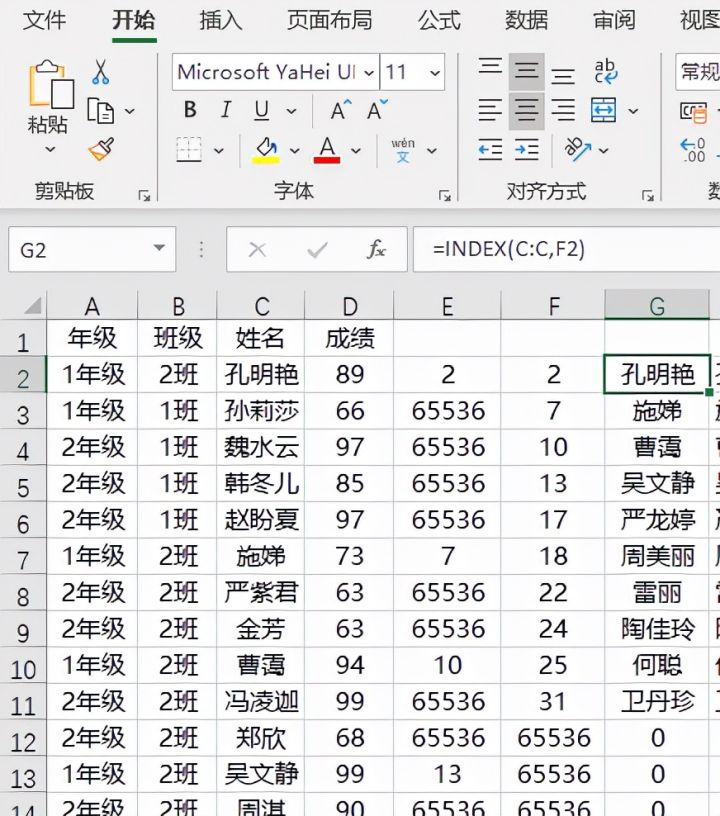
然后是INDEX函数,它是返回表或区域中的值或值的引用。它的语法结构是INDEX(单元格区域,行号,列号),因此他在本文中的作用就是返回small函数提供的行号所对应的姓名或者成绩。在单元格中输入公式=INDEX(C:C,F2),其返回结果如下图。

















 2121
2121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









