子带。子带(subband)是指这样的一种频率范围,当两个音调的频率位于一个子带内时,人就会把两个音调听成一个。更一般的情况是,如果一个复杂信号的频率分布位于一个子带内时,人耳的感觉是该信号等价于一个频率位于该子带中心频率处的简单信号,这是子带的核心内涵。简单说,子带是指一个频率范围,频谱位于这个范围内的信号可以用一个单一频率的分量来代替。
一般等价的频率取子带的中心频率,振幅取子带内个频率分量振幅的加权和,更简单的方法则是将各频率分量的振幅直接相加,作为等价信号的振幅,这样一个范围内的频率分量用一个分量就可以代替了。
设一个信号的频谱频率最低值为w0,最大值为w1。子带编码就是将w0-w1之间的频率范围划分成若干子带,然后每个子带范围内的分量用一个等价的频率分量来替换。这样,一个具有复杂频谱的信号可以等价为一个频谱构成灰常简单的信号——频谱被大大简化了,需要存储的东西就非常少了。
从以上过程不难知道,子带如何划分对压缩后音频的质量影响很大(毕竟是近似等价)。子带的划分方法是子带编码的一个很重要的研究主题,大致可以分为等宽子带编码和变宽子带编码,见名知意,不解释。
子带划分后子带数量的不同导致了压缩算法的不同等级。容易知道,码率越低压缩率越高时,子带数量少,同时音质较差。相反的情况也容易理解。
理解了子带编码,音频压缩就很容易理解了,一个信号经过一组三角滤波器(等同于一组子带)后,被精简为数量很少的频率分量。然后考察这些频率分量,能量或者说振幅位于可听度阈值曲线之下的直接无视(删除该分量,因为听不到)。再考察余下的两两相邻的频率分量,如果其中一个被旁边的频率屏蔽,也删除掉。经过以上的处理,一个复杂信号的频谱所含有的频率分量就很简单了,使用很少的数据就可以存储或者传输这些信息。
解码的时候使用傅里叶逆变换将上面得到的简单频谱重构到时域上,得到解码后的语音。
子带编码往往是音频编码的第一步,方便之后利用心理声学模型来处理各个频带。
比如:
auditory masking in the human auditory system. Human ears are normally sensitive to a wide range of frequencies, but when a sufficiently loud signal is present at one frequency, the ear will not hear weaker signals at nearby frequencies. We say that the louder signal masks the softer ones. The louder signal is called the masker, and the point at which masking occurs is known as the masking threshold.
The basic idea of SBC is to enable a data reduction by discarding information about frequencies which are masked. The result differs from the original signal, but if the discarded information is chosen carefully, the difference will not be noticeable, or more importantly, objectionable.
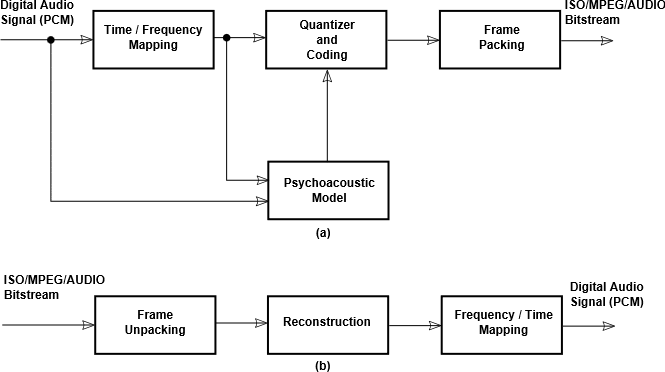
基本的子带编码的流程:
To enable higher quality compression, one may use subband coding. First, a digital filter bank divides the input signal spectrum into some number (e.g., 32) of subbands. The psychoacoustic model looks at the energy in each of these subbands, as well as in the original signal, and computes masking thresholds using psychoacoustic information. Each of the subband samples is quantized and encoded so as to keep the quantization noise below the dynamically computed masking threshold. The final step is to format all these quantized samples into groups of data called frames, to facilitate eventual playback by a decoder.
Decoding is much easier than encoding, since no psychoacoustic model is involved. The frames are unpacked, subband samples are decoded, and a frequency-time mapping reconstructs an output audio signal.
Beginning in the late 1980s, a standardization body called the Motion Picture Experts Group (MPEG) developed generic standards for coding of both audio and video. Subband coding resides at the heart of the popular MP3 format (more properly known as MPEG-1 Audio Layer III), for example.























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









