







Spark SQL笔记
转载自Spark修炼之道
1. Spark SQL简介
Spark SQL是Spark的五大核心模块之一,用于在Spark平台之上处理结构化数据,利用Spark SQL可以构建大数据平台上的数据仓库,它具有如下特点:
(1)能够无缝地将SQL语句集成到Spark应用程序当中
(2)统一的数据访问方式
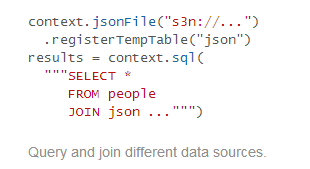
DataFrames and SQL provide a common way to access a variety of data sources, including Hive, Avro, Parquet, ORC, JSON, and JDBC. You can even join data across these sources.
(3) 兼容Hive
(4) 可采用JDBC or ODBC连接


2. DataFrame
(1)DataFrame简介
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,与传统RDBMS的表结构类似。与一般的RDD不同的是,DataFrame带有schema元信息,即DataFrame所表示的表数据集的每一列都带有名称和类型,它对于数据的内部结构具有很强的描述能力。因此Spark SQL可以对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行了针对性的优化,最终达到大幅提升运行时效率。
DataFrames具有如下特点:
(1)Ability to scale from kilobytes of data on a single laptop to petabytes on a large cluster(支持单机KB级到集群PB级的数据处理)
(2)Support for a wide array of data formats and storage systems(支持多种数据格式和存储系统,如图所示)
(3)State-of-the-art optimization and code generation through the Spark SQL Catalyst optimizer(通过Spark SQL Catalyst优化器可以进行高效的代码生成和优化)
(4)Seamless integration with all big data tooling and infrastructure via Spark(能够无缝集成所有的大数据处理工具)
(5)APIs for Python, Java, Scala, and R (in development via SparkR)(提供Python, Java, Scala, R语言API)

(2)DataFrame 实战
将people.json上传到HDFS上,放置在/data目录下,people.json文件内容如下:
root@sparkslave01:~# hdfs dfs -cat /data/people.json
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
由于json文件中已经包括了列名称的信息,因此它可以直接创建DataFrame
scala> val df = sqlContext.read.json("/data/people.json")
df: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
//显示DataFrame完整信息
scala> df.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
//查看DataFrame元数据信息
scala> df.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
//返回DataFrame某列所有数据
scala> df.select("name").show()
+-------+
| name|
+-------+
|Michael|
| Andy|
| Justin|
+-------+
//DataFrame数据过滤
scala> df.filter(df("age") > 21).show()
+---+----+
|age|name|
+---+----+
| 30|Andy|
+---+----+
//按年龄分组
scala> df.groupBy("age").count().show()
+----+-----+
| age|count|
+----+-----+
|null| 1|
| 19| 1|
| 30| 1|
+----+-----+
//注册成表
scala> df.registerTempTable("people")
//执行SparkSQL
scala> val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
teenagers: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
//结果格式化输出
scala> teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
Name: Justin
3. 运行流程
1、整体运行流程
使用下列代码对SparkSQL流程进行分析,让大家明白LogicalPlan的几种状态,理解SparkSQL整体执行流程
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Define the schema using a case class.
// Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit,
// you can use custom classes that implement the Product interface.
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.
val people = sc.textFile("/examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
(1)查看teenagers的Schema信息
scala> teenagers.printSchema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
(2)查看运行流程
scala> teenagers.queryExecution
res3: org.apache.spark.sql.SQLContext#QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias('name),unresolvedalias('age)]
'Filter (('age >= 13) && ('age <= 19))
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
Filter ((age#1 >= 13) && (age#1 <= 19))
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
Code Generation: true
QueryExecution中表示的是整体Spark SQL运行流程,从上面的输出结果可以看到,一个SQL语句要执行需要经过下列步骤:
== (1)Parsed Logical Plan ==
'Project [unresolvedalias('name),unresolvedalias('age)]
'Filter (('age >= 13) && ('age <= 19))
'UnresolvedRelation [people], None
== (2)Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
Filter ((age#1 >= 13) && (age#1 <= 19))
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== (3)Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== (4)Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
//启动动态字节码生成技术(bytecode generation,CG),提升查询效率
Code Generation: true
2、全表查询运行流程
执行语句:
val all= sqlContext.sql("SELECT * FROM people")
运行流程:
scala> all.queryExecution
res9: org.apache.spark.sql.SQLContext#QueryExecution =
//注意*号被解析为unresolvedalias(*)
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
//unresolvedalias(*)被analyzed为Schema中所有的字段
//UnresolvedRelation [people]被analyzed为Subquery people
name: string, age: int
Project [name#0,age#1]
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Physical Plan ==
Scan PhysicalRDD[name#0,age#1]
Code Generation: true
3、filter查询运行流程
执行语句:
scala> val filterQuery= sqlContext.sql("SELECT * FROM people WHERE age >= 13 AND age <= 19")
filterQuery: org.apache.spark.sql.DataFrame = [name: string, age: int]
执行流程:
scala> filterQuery.queryExecution
res0: org.apache.spark.sql.SQLContext#QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Filter (('age >= 13) && ('age <= 19))
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
//多出了Filter,后同
Filter ((age#1 >= 13) && (age#1 <= 19))
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:20
== Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:20
== Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
Code Generation: true
4、join查询运行流程
执行语句:
val joinQuery= sqlContext.sql("SELECT * FROM people a, people b where a.age=b.age")
查看整体执行流程
scala> joinQuery.queryExecution
res0: org.apache.spark.sql.SQLContext#QueryExecution =
//注意Filter
//Join Inner
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Filter ('a.age = 'b.age)
'Join Inner, None
'UnresolvedRelation [people], Some(a)
'UnresolvedRelation [people], Some(b)
== Analyzed Logical Plan ==
name: string, age: int, name: string, age: int
Project [name#0,age#1,name#2,age#3]
Filter (age#1 = age#3)
Join Inner, None
Subquery a
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
Subquery b
Subquery people
LogicalRDD [name#2,age#3], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
Project [name#0,age#1,name#2,age#3]
Join Inner, Some((age#1 = age#3))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4]...
//查看其Physical Plan
scala> joinQuery.queryExecution.sparkPlan
res16: org.apache.spark.sql.execution.SparkPlan =
TungstenProject [name#0,age#1,name#2,age#3]
SortMergeJoin [age#1], [age#3]
Scan PhysicalRDD[name#0,age#1]
Scan PhysicalRDD[name#2,age#3]
前面的例子与下面的例子等同,只不过其运行方式略有不同,执行语句:
scala> val innerQuery= sqlContext.sql("SELECT * FROM people a inner join people b on a.age=b.age")
innerQuery: org.apache.spark.sql.DataFrame = [name: string, age: int, name: string, age: int]
查看整体执行流程:
scala> innerQuery.queryExecution
res2: org.apache.spark.sql.SQLContext#QueryExecution =
//注意Join Inner
//另外这里面没有Filter
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Join Inner, Some(('a.age = 'b.age))
'UnresolvedRelation [people], Some(a)
'UnresolvedRelation [people], Some(b)
== Analyzed Logical Plan ==
name: string, age: int, name: string, age: int
Project [name#0,age#1,name#4,age#5]
Join Inner, Some((age#1 = age#5))
Subquery a
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
Subquery b
Subquery people
LogicalRDD [name#4,age#5], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
//注意Optimized Logical Plan与Analyzed Logical Plan
//并没有进行特别的优化,突出这一点是为了比较后面的子查询
//其Analyzed和Optimized间的区别
== Optimized Logical Plan ==
Project [name#0,age#1,name#4,age#5]
Join Inner, Some((age#1 = age#5))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder ...
//查看其Physical Plan
scala> innerQuery.queryExecution.sparkPlan
res14: org.apache.spark.sql.execution.SparkPlan =
TungstenProject [name#0,age#1,name#6,age#7]
SortMergeJoin [age#1], [age#7]
Scan PhysicalRDD[name#0,age#1]
Scan PhysicalRDD[name#6,age#7]
5、子查询运行流程
执行语句:
scala> val subQuery=sqlContext.sql("SELECT * FROM (SELECT * FROM people WHERE age >= 13) a where a.age <= 19")
subQuery: org.apache.spark.sql.DataFrame = [name: string, age: int]
查看整体执行流程:
scala> subQuery.queryExecution
res4: org.apache.spark.sql.SQLContext#QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Filter ('a.age <= 19)
'Subquery a
'Project [unresolvedalias(*)]
'Filter ('age >= 13)
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
Filter (age#1 <= 19)
Subquery a
Project [name#0,age#1]
Filter (age#1 >= 13)
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
//这里需要注意Optimized与Analyzed间的区别
//Filter被进行了优化
== Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
Code Generation: true
6、聚合SQL运行流程
执行语句:
scala> val aggregateQuery=sqlContext.sql("SELECT a.name,sum(a.age) FROM (SELECT * FROM people WHERE age >= 13) a where a.age <= 19 group by a.name")
aggregateQuery: org.apache.spark.sql.DataFrame = [name: string, _c1: bigint]
运行流程查看:
scala> aggregateQuery.queryExecution
res6: org.apache.spark.sql.SQLContext#QueryExecution =
//注意'Aggregate ['a.name], [unresolvedalias('a.name),unresolvedalias('sum('a.age))]
//即group by a.name被 parsed为unresolvedalias('a.name)
== Parsed Logical Plan ==
'Aggregate ['a.name], [unresolvedalias('a.name),unresolvedalias('sum('a.age))]
'Filter ('a.age <= 19)
'Subquery a
'Project [unresolvedalias(*)]
'Filter ('age >= 13)
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, _c1: bigint
Aggregate [name#0], [name#0,sum(cast(age#1 as bigint)) AS _c1#9L]
Filter (age#1 <= 19)
Subquery a
Project [name#0,age#1]
Filter (age#1 >= 13)
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
Aggregate [name#0], [name#0,sum(cast(age#1 as bigint)) AS _c1#9L]
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitions...
//查看其Physical Plan
scala> aggregateQuery.queryExecution.sparkPlan
res10: org.apache.spark.sql.execution.SparkPlan =
TungstenAggregate(key=[name#0], functions=[(sum(cast(age#1 as bigint)),mode=Final,isDistinct=false)], output=[name#0,_c1#14L])
TungstenAggregate(key=[name#0], functions=[(sum(cast(age#1 as bigint)),mode=Partial,isDistinct=false)], output=[name#0,currentSum#17L])
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
其它SQL语句,大家可以使用同样的方法查看其执行流程,以掌握Spark SQL背后实现的基本思想。
4. 案例实战
1、获取数据
本文通过将github上的Spark项目git日志作为数据,对SparkSQL的内容进行详细介绍。
数据获取命令如下:
[root@master spark]# git log --pretty=format:'{"commit":"%H","author":"%an","author_email":"%ae","date":"%ad","message":"%f"}' > sparktest.json
格式化日志内容输出如下:
[root@master spark]# head -1 sparktest.json
{"commit":"30b706b7b36482921ec04145a0121ca147984fa8","author":"Josh Rosen","author_email":"joshrosen@databricks.com","date":"Fri Nov 6 18:17:34 2015 -0800","message":"SPARK-11389-CORE-Add-support-for-off-heap-memory-to-MemoryManager"}
然后使用命令将sparktest.json文件上传到HDFS上
[root@master spark]#hadoop dfs -put sparktest.json /data/
2、创建DataFrame
使用数据创建DataFrame
scala> val df = sqlContext.read.json("/data/sparktest.json")
16/02/05 09:59:56 INFO json.JSONRelation: Listing hdfs://ns1/data/sparktest.json on driver
查看其模式:
scala> df.printSchema()
root
|-- author: string (nullable = true)
|-- author_email: string (nullable = true)
|-- commit: string (nullable = true)
|-- date: string (nullable = true)
|-- message: string (nullable = true)
3、DataFrame方法实战
(1)显式前两行数据
scala> df.show(2)
+----------------+--------------------+--------------------+--------------------+--------------------+
| author| author_email| commit| date| message|
+----------------+--------------------+--------------------+--------------------+--------------------+
| Josh Rosen|joshrosen@databri...|30b706b7b36482921...|Fri Nov 6 18:17:3...|SPARK-11389-CORE-...|
|Michael Armbrust|michael@databrick...|105732dcc6b651b97...|Fri Nov 6 17:22:3...|HOTFIX-Fix-python...|
+----------------+--------------------+--------------------+--------------------+--------------------+
(2)计算总提交次数
scala> df.count
res4: Long = 13507
(3)按提交次数进行降序排序
scala>df.groupBy("author").count.sort($"count".desc).show
+--------------------+-----+
| author|count|
+--------------------+-----+
| Matei Zaharia| 1590|
| Reynold Xin| 1071|
| Patrick Wendell| 857|
| Tathagata Das| 416|
| Josh Rosen| 348|
| Mosharaf Chowdhury| 290|
| Andrew Or| 287|
| Xiangrui Meng| 285|
| Davies Liu| 281|
| Ankur Dave| 265|
| Cheng Lian| 251|
| Michael Armbrust| 243|
| zsxwing| 200|
| Sean Owen| 197|
| Prashant Sharma| 186|
| Joseph E. Gonzalez| 185|
| Yin Huai| 177|
|Shivaram Venkatar...| 173|
| Aaron Davidson| 164|
| Marcelo Vanzin| 142|
+--------------------+-----+
only showing top 20 rows
4、DataFrame注册成临时表使用实战
使用下列语句将DataFrame注册成表
scala> val commitLog=df.registerTempTable("commitlog")
(1)显示前2行数据
scala> sqlContext.sql("SELECT * FROM commitlog").show(2)
+----------------+--------------------+--------------------+--------------------+--------------------+
| author| author_email| commit| date| message|
+----------------+--------------------+--------------------+--------------------+--------------------+
| Josh Rosen|joshrosen@databri...|30b706b7b36482921...|Fri Nov 6 18:17:3...|SPARK-11389-CORE-...|
|Michael Armbrust|michael@databrick...|105732dcc6b651b97...|Fri Nov 6 17:22:3...|HOTFIX-Fix-python...|
+----------------+--------------------+--------------------+--------------------+--------------------+
(2)计算总提交次数
scala> sqlContext.sql("SELECT count(*) as TotalCommitNumber FROM commitlog").show
+-----------------+
|TotalCommitNumber|
+-----------------+
| 13507|
+-----------------+
(3)按提交次数进行降序排序
scala> sqlContext.sql("SELECT author,count(*) as CountNumber FROM commitlog GROUP BY author ORDER BY CountNumber DESC").show
+--------------------+-----------+
| author|CountNumber|
+--------------------+-----------+
| Matei Zaharia| 1590|
| Reynold Xin| 1071|
| Patrick Wendell| 857|
| Tathagata Das| 416|
| Josh Rosen| 348|
| Mosharaf Chowdhury| 290|
| Andrew Or| 287|
| Xiangrui Meng| 285|
| Davies Liu| 281|
| Ankur Dave| 265|
| Cheng Lian| 251|
| Michael Armbrust| 243|
| zsxwing| 200|
| Sean Owen| 197|
| Prashant Sharma| 186|
| Joseph E. Gonzalez| 185|
| Yin Huai| 177|
|Shivaram Venkatar...| 173|
| Aaron Davidson| 164|
| Marcelo Vanzin| 142|
+--------------------+-----------+
更多复杂的玩法,大家可以自己去尝试,这里给出的只是DataFrame方法与临时表SQL语句的用法差异,以便于有整体的认知。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









