







由于采用动态链接库(DLL)之后,程序调试无法进入DLL中的每一句,能也只能看到反汇编的代码(难懂),但是有时候还是想知道DLL中究竟哪些函数、哪些分支被执行了。解决方法是可以通过修改函数返回值的方式。一般DLL都会至少有一个函数返回值,有的时候会是void类型(无返回值类型)。都可以通过修改函数返回值的类型来监测那部分代码被执行了。常用的比如修改函数返回值的类型为int类型,将不同的分支或者函数执行结束后赋予不同的整数值,这样就可以较为简单的了解动态链接库中分支的执行情况了。
遇到这个问题的起因是因为含有SSE优化代码的文件封装成DLL之后,实际的运行速度和原作者提供的版本相差太多了。所以想了解一下程序分支的执行情况。
其中部分分支代码为:
/**
* Adds histograms \a x and \a y and stores the result in \a y. Makes use of
* SSE2, MMX or Altivec, if available.
*/
#if defined(__SSE2__)
static inline void histogram_add( const uint16_t x[16], uint16_t y[16] )
{
*(__m128i*) &y[0] = _mm_add_epi16( *(__m128i*) &y[0], *(__m128i*) &x[0] );
*(__m128i*) &y[8] = _mm_add_epi16( *(__m128i*) &y[8], *(__m128i*) &x[8] );
back=110;
}
#elif defined(__MMX__)
static inline void histogram_add( const uint16_t x[16], uint16_t y[16] )
{
*(__m64*) &y[0] = _mm_add_pi16( *(__m64*) &y[0], *(__m64*) &x[0] );
*(__m64*) &y[4] = _mm_add_pi16( *(__m64*) &y[4], *(__m64*) &x[4] );
*(__m64*) &y[8] = _mm_add_pi16( *(__m64*) &y[8], *(__m64*) &x[8] );
*(__m64*) &y[12] = _mm_add_pi16( *(__m64*) &y[12], *(__m64*) &x[12] );
back=111;
}
#elif defined(__ALTIVEC__)
static inline void histogram_add( const uint16_t x[16], uint16_t y[16] )
{
*(vector unsigned short*) &y[0] = vec_add( *(vector unsigned short*) &y[0], *(vector unsigned short*) &x[0] );
*(vector unsigned short*) &y[8] = vec_add( *(vector unsigned short*) &y[8], *(vector unsigned short*) &x[8] );
back=112;
}
#else
static inline void histogram_add( const uint16_t x[16], uint16_t y[16] )
{
int i;
for ( i = 0; i < 16; ++i ) {
y[i] += x[i];
}
back=113;
}
#endif
函数执行完毕后,函数的返回值分别赋值为110,111,112,113,最后的程序的执行结果为113,说明并没有采用SSE进行速度优化。证实了自己的判断。将DLL中没有必要的分支判断去掉,仅留下SSE对应的代码。将运行结果和之前的DLL处理结果进行比较,速度如下,处理图片大小1024*683,电脑配置如下:
鲁大师检测硬件结果
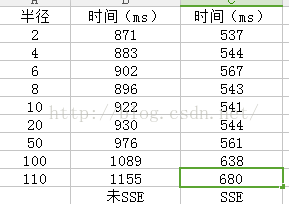
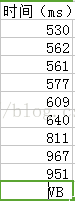
算法处理速度显示,之前自己封装的DLL,在调用的过程中确实没有执行SSE代码优化部分,SSE优化之后处理速度虽然有了一定的提升,但是和作者的处理速度还有很大的差距,而且处理速度和半径也有相关性。最后列为作者用VB实现的处理时间(VB没有指针,采用数组代表图像,效率降低)。















 5688
5688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











