







在爬虫实践当中,如果我们爬取的页面的编写没有做好板块的区分,或者我们选取的标签不合适,最终我们获得的结果会多提取到出一些奇怪的东西。
当使用用request获取的网页源代码里没有我们想要的数据时,需要重新思考。
一、认识Network
在网页空白处,点击右键-检查,第一个是Elements,往右看就能找到Network。
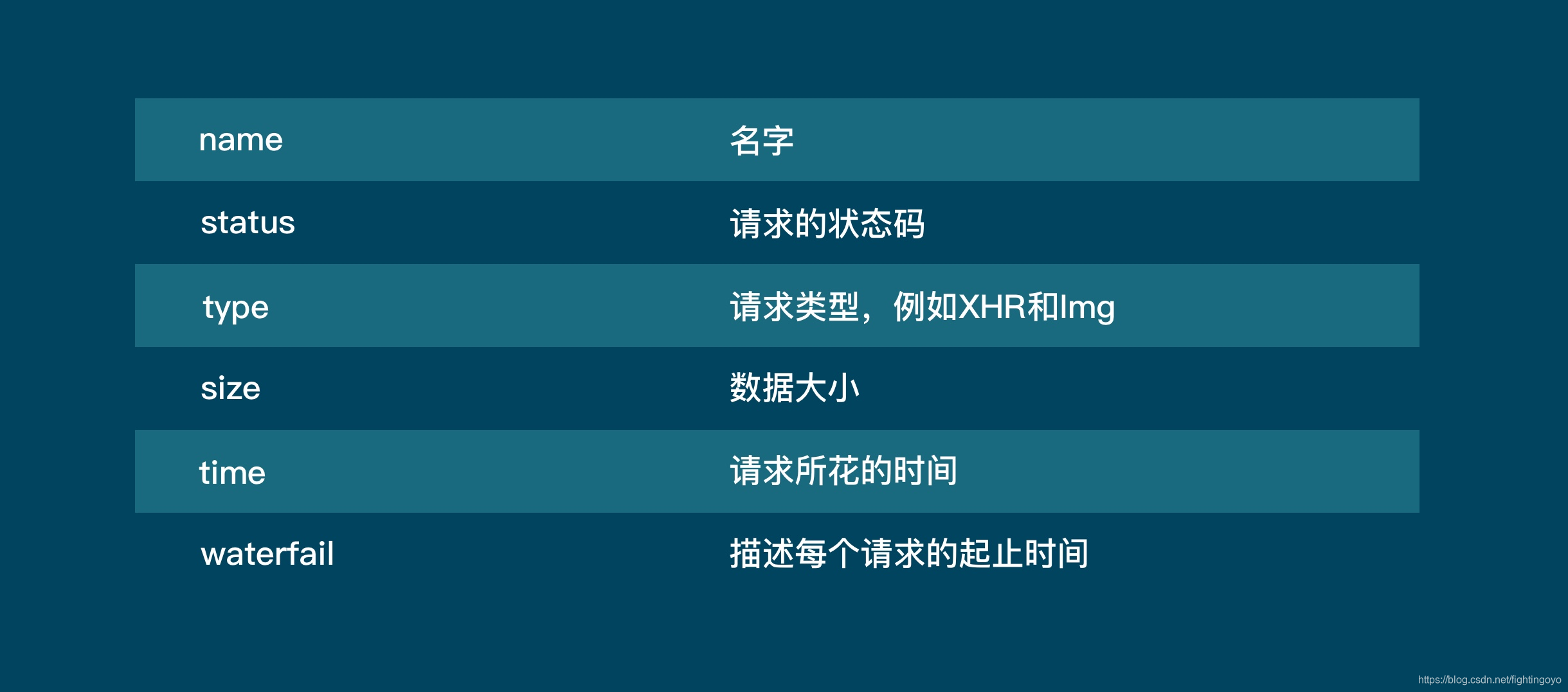
- Network的功能是:记录在当前页面上发生的所有请求。
现在看上去好像空空如也的样子,这是因为Network记录的是实时网络请求。现在网页都已经加载完成,所以不会有东西。
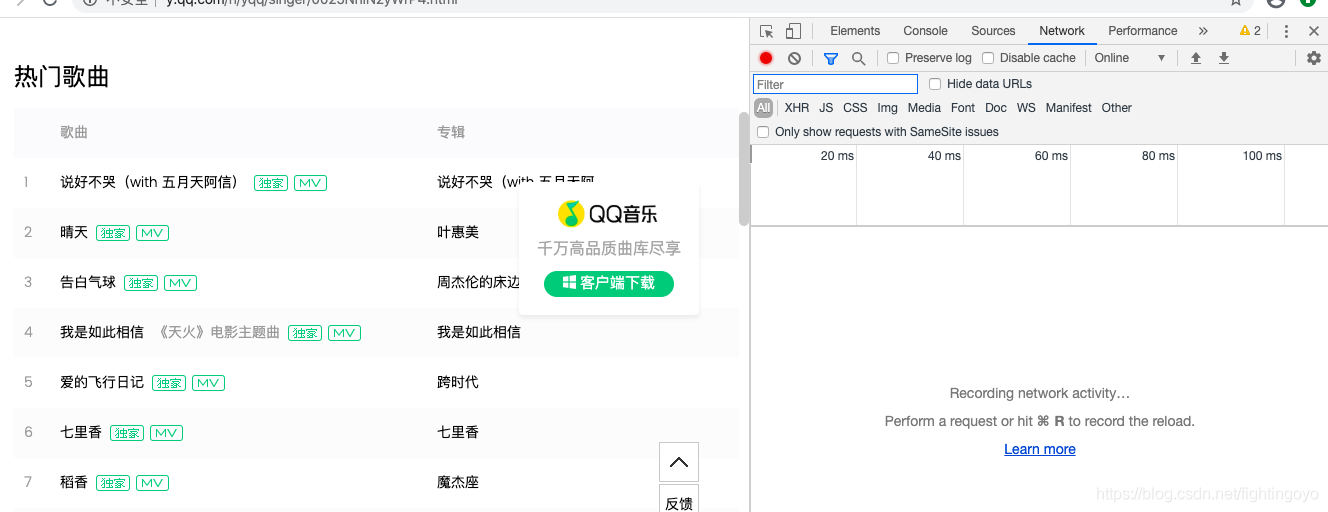
刷新一下页面,浏览器会重新访问网络,这样就会有记录。
这正是浏览器工作的原理:它总是在向服务器发起请求。当这些请求完成,服务器就会返回我们在Elements中看到的网页源代码。 - 当我们使用requests.get(url)时,只是获取了请求中的第一个,当这个请求中不包含我们需要的代码时,那么,就需要在其他请求中查找。
- 为什么我们之前体验过的豆瓣都能够直接爬取我们需要的信息呢?
- 这些网页直接把所有的关键信息都放在第1个请求里,我们用requests和BeautifulSoup就能解决它们。
二、如何使用Network
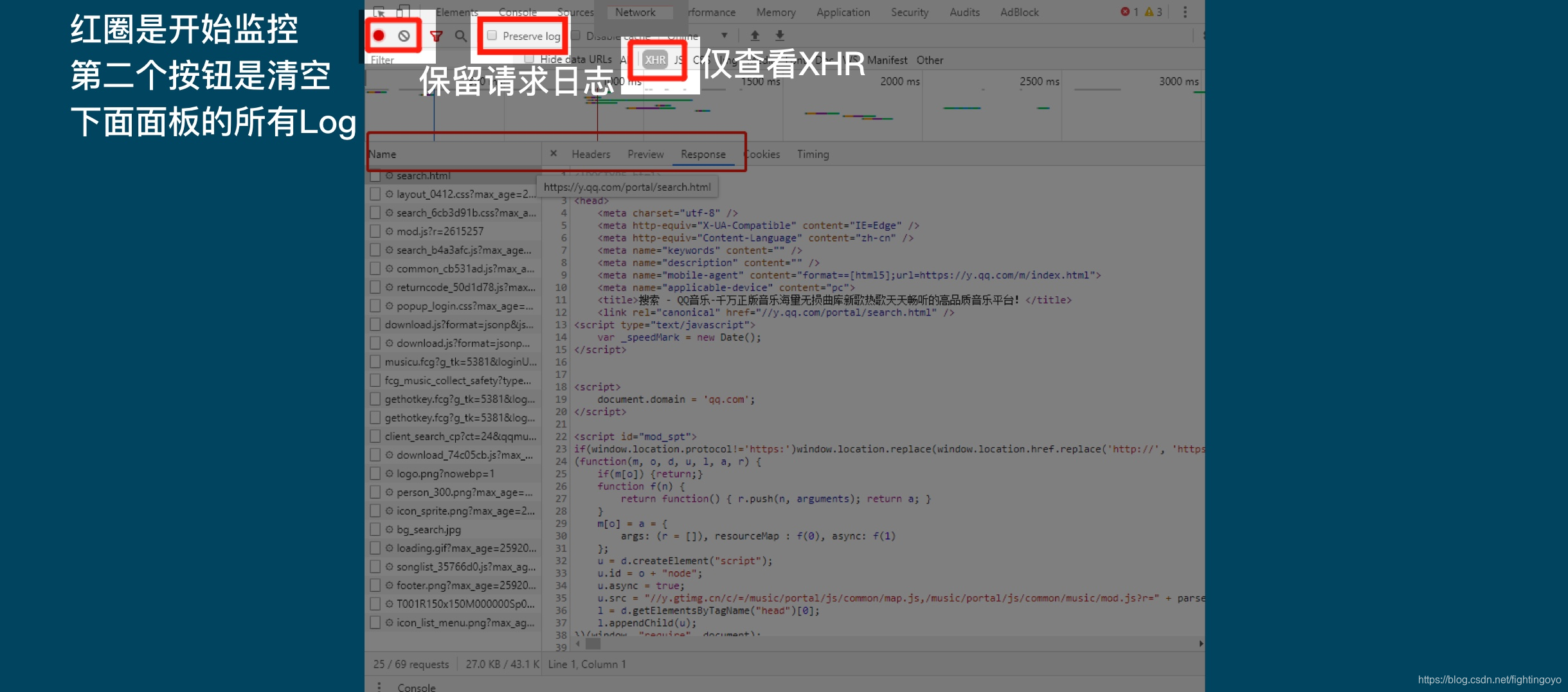
- 第1行的左侧,红色的圆钮是启用Network监控(一般浏览器默认是打开的,用高亮显示),灰色圆圈是清空面板上的信息。
- 右侧勾选框Preserve log,它的作用是“保留请求日志”。如果不点击这个,当发生页面跳转的时候,记录就会被清空。所以,我们在爬取一些会发生跳转的网页时,会点亮它。
- 第3行,是对请求进行分类查看。我们最常用的是:ALL(查看全部)/XHR(仅查看XHR)/Doc(Document,第1个请求一般在这里,有时候也会看:Img(仅查看图片)/Media(仅查看媒体文件)/Other(其他)。
- JS和CSS,则是前端代码,负责发起请求和页面实现;Font是文字的字体;而理解WS和Manifest,需要网络编程的知识。

- 图中我们还可以看到时间轴:记录什么时间,有哪些请求。而下一行,就是各个请求。
三、什么是XHR
我们平时使用浏览器上网的时候,经常有这样的情况:我们观察到浏览器的地址栏里面的网址并没有发生变化,但是网页却不断有新增的内容出现。
- 这个是Ajax技术。应用这种技术,好处是显而易见的——更新网页内容,而不用重新加载整个网页,又省流量又省时间。
- 这种技术在工作的时候,会创建一个XHR(或是Fetch)对象,然后利用XHR对象来实现服务器和浏览器之间传输数据。
XHR和Fetch并没有本质区别,只是Fetch出现得比XHR更晚一些,所以对一些开发人员来说会更好用,但作用都是一样的。
XHR怎么请求
我们在QQ音乐搜索”周杰伦“,我们想要找到周杰伦的歌曲列表,但在第一个请求中并没有找到我们要找的数据。
我们查看其他的请求,可以在xhr中搜索其中一首歌的歌曲名称,找到对应的请求:找到了client_search的请求。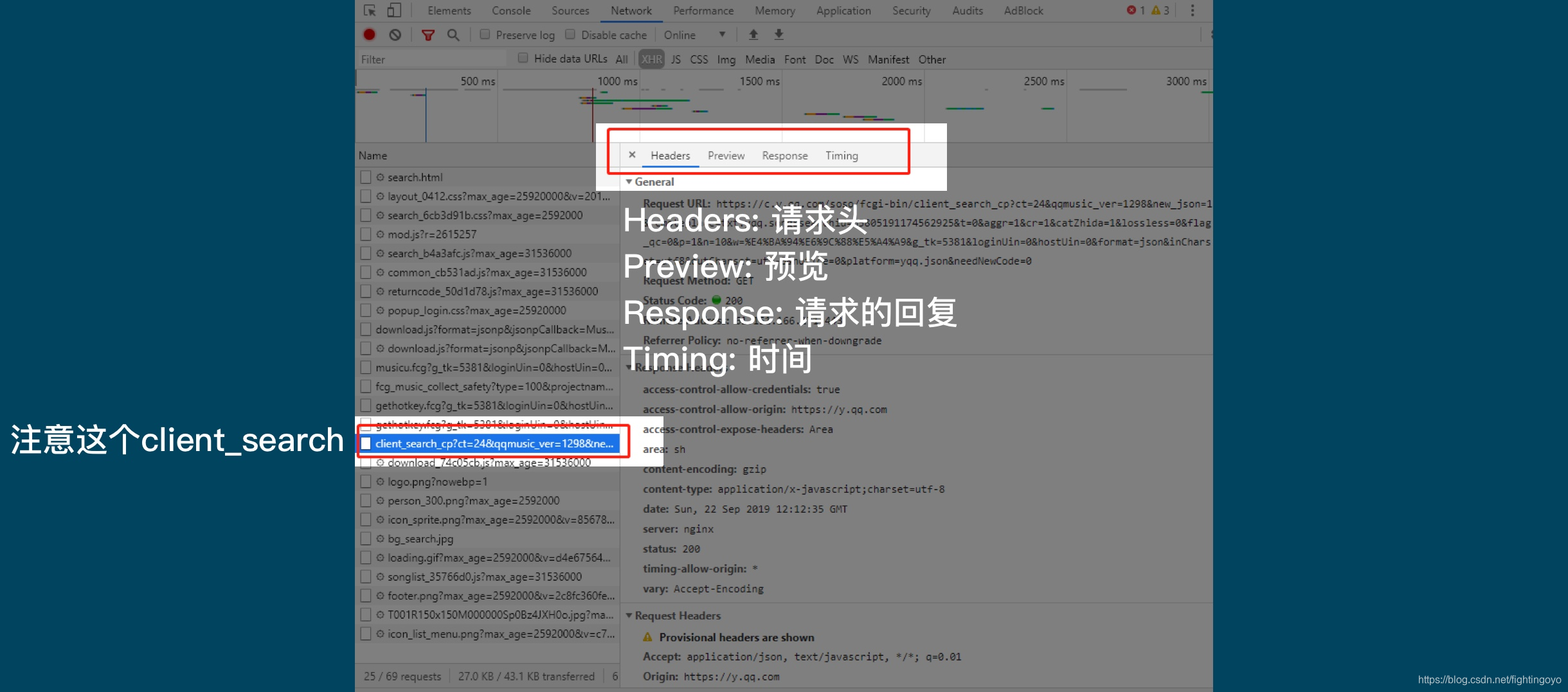
- 红框里面的内容,从左往右分别是:Headers:标头(请求信息)、Preview:预览、Response:原始信息、Timing:时间。
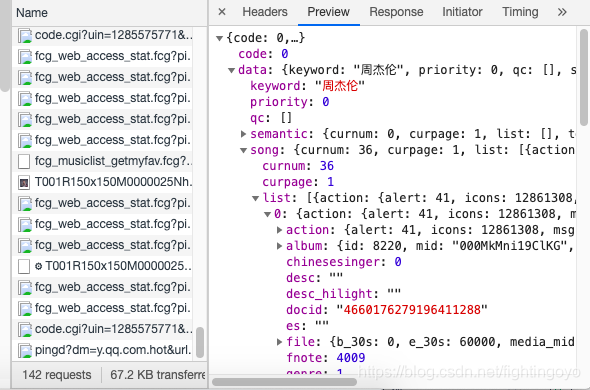
- 点击Preview,里面发现我们想要的信息:歌名就藏在里面!(只是有点难找,需要你一层一层展开:data-song-list-0-name,然后就能看到“知足”)。
那如何把这些歌曲名拿到呢?这就需要我们去看看最左侧的Headers,点击它。如下所示,它被分为四个板块。
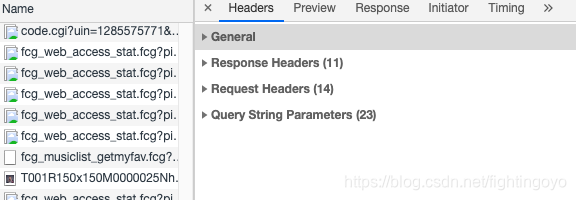
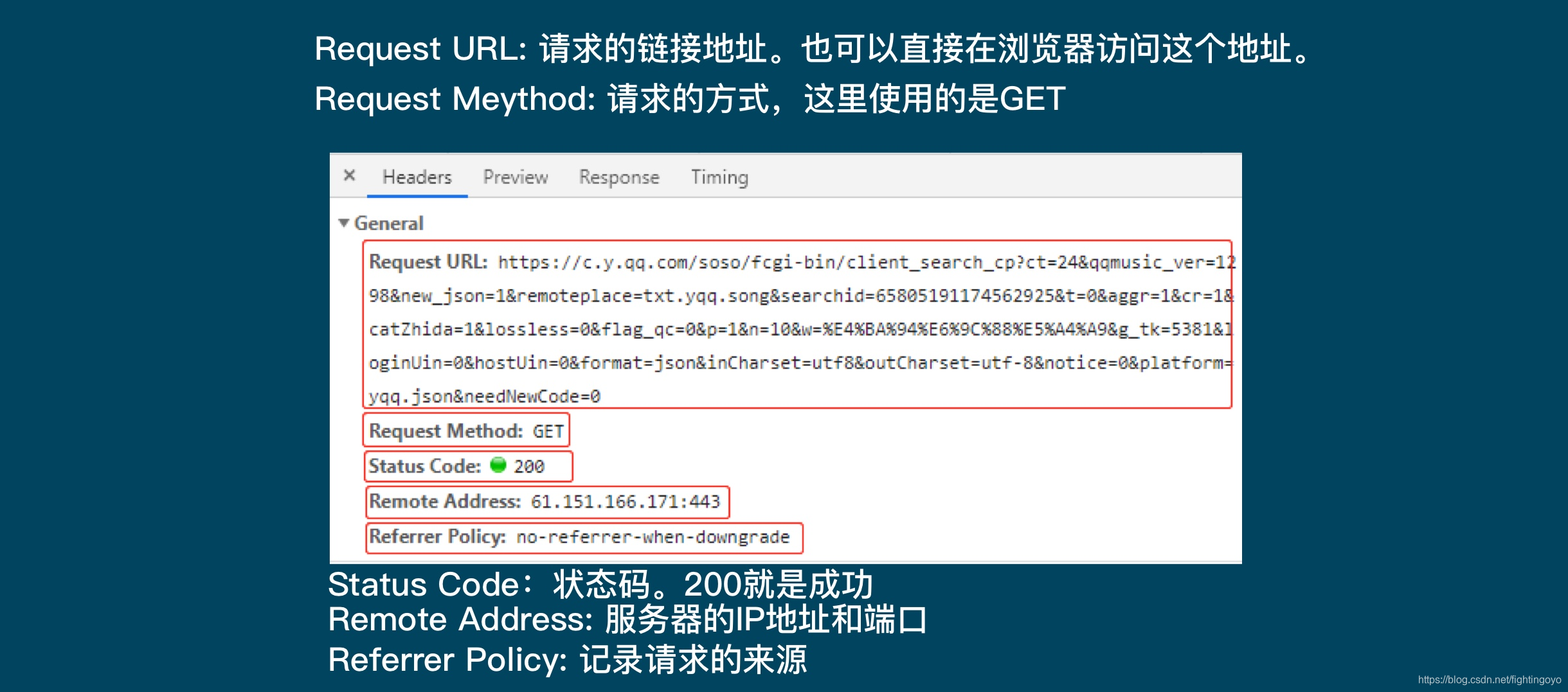
- General里的Requests URL就是我们应该去访问的链接。如果在浏览器中打开这个链接,你会看到一个让人绝望的结构:最外层是一个字典,然后里面又是字典,往里面又有列表和字典……

- 和我们在在Response里看到东西是一致的,回到原网址,直接用Preview来看就好。列表和字典在此都会有非常清晰的结构,层层展开。
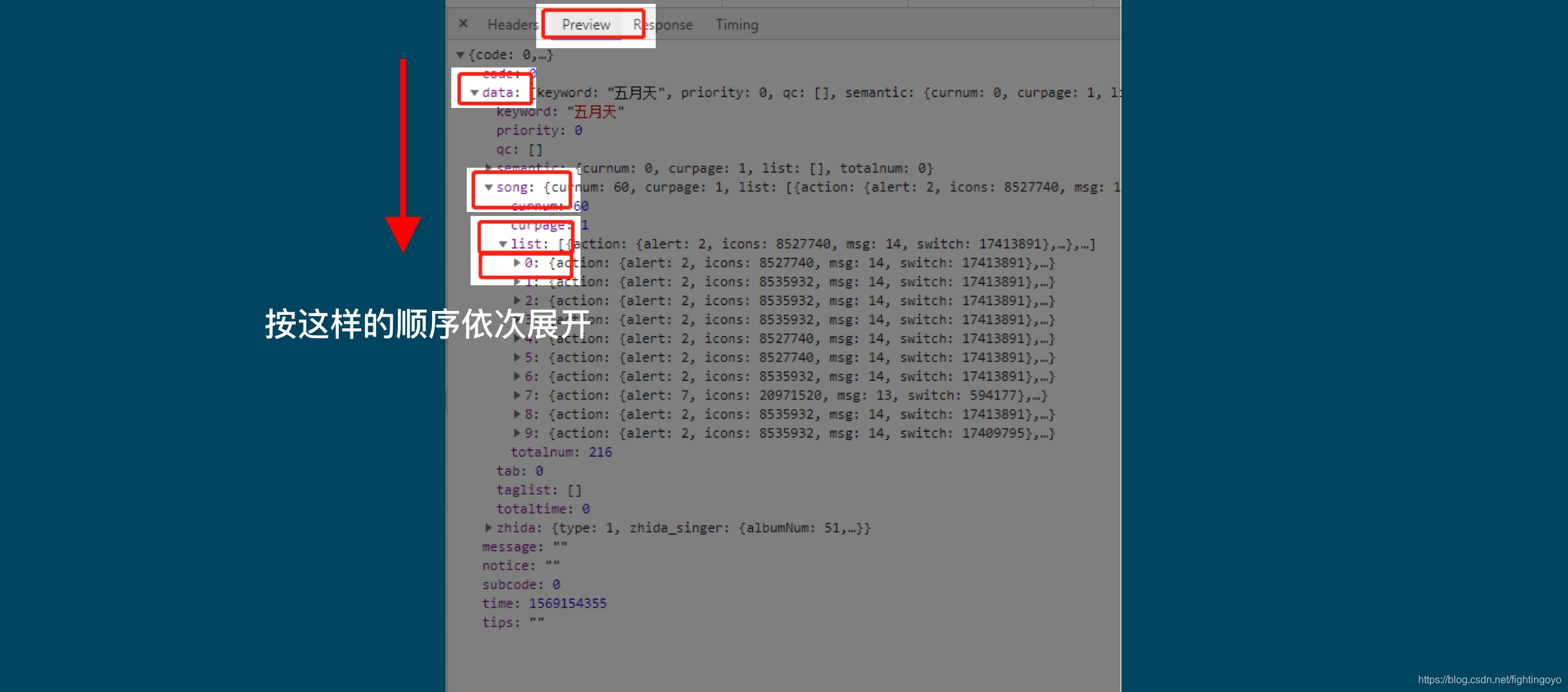
- 歌曲名就在这里,它的键是name。
这个XHR是一个字典,键data对应的值也是一个字典;在该字典里,键song对应的值也是一个字典;在该字典里,键list对应的值是一个列表;在该列表里,一共有20个元素;每一个元素都是一个字典;在每个字典里,键name的值,对应的是歌曲名。
此时,我们可以利用requests.get()访问这个链接,把这个字典下载到本地。然后去一层一层地解析,拿到歌曲名。
import requests
response = requests.get('https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
print(response.text)
输出结果源代码为字符串。
输出的内容为字符串,不是我们想要的字典或者列表,应该怎么办?
四、什么是json
在Python语言当中,json是一种特殊的字符串,这种字符串特殊在它的写法——它是用列表/字典的语法写成的。
# 这是字符串
a = '1,2,3,4,5'
# 这是列表
b = [1, 2, 3, 4, 5]
# 这是字符串,但这是用json格式写的字符串
c = '[1,2,3,4,5]'
这种特殊的写法决定了,json能够有组织地存储信息。
- json是一种组织数据的格式,长得和Python中的列表/字典非常相像。
- 它和html一样,常用来做网络数据传输。刚刚我们在XHR里查看到的列表/字典,严格来说其实它不是列表/字典,它是json。
json和XHR之间的关系:XHR用于传输数据,它能传输很多种数据,json是被传输的一种数据格式.
如何解析json数据
import requests
response = requests.get(
'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
js_music = response.json()
print(type(js_music))
# 输出结果:
<class 'dict'>
通过json()方法实现数据格式的转换。
import requests
response = requests.get(
'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
js_music = response.json()
# 逐层展开字典,获得歌曲列表
list_music = js_music['data']['song']['list']
# 遍历列表,得到每首歌曲的名称
for music in list_music:
print(music['name'])
# 输出结果如下:
晴天
一路向北
七里香
搁浅
稻香
爱的飞行日记
告白气球
不能说的秘密
等你下课
夜曲
再扩展一下,能得到歌曲的其他信息
import requests
response = requests.get(
'https://c.y.qq.com/soso/fcgi-bin/client_search_cp?ct=24&qqmusic_ver=1298&new_json=1&remoteplace=txt.yqq.center&searchid=52560057505703631&t=0&aggr=1&cr=1&catZhida=1&lossless=0&flag_qc=0&p=1&n=10&w=%E5%91%A8%E6%9D%B0%E4%BC%A6&g_tk=1847098181&loginUin=1285575771&hostUin=0&format=json&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq.json&needNewCode=0')
# 使用json()方法,将response对象,转为列表/字典
js_music = response.json()
# 逐层展开字典,获得歌曲列表
list_music = js_music['data']['song']['list']
# 遍历列表,得到每首歌曲的信息
for music in list_music:
# 歌曲名称
name = music['name']
# 歌曲所属专辑
album = music['album']['name']
# 播放时长
time = str(music['interval'])+'秒'
# 播放链接
url = 'https://y.qq.com/n/yqq/song/'+music['mid']+'.html'
print(name+'\n'+album+'\n'+time+'\n'+url+'\n')
# 输出结果如下:
晴天
叶惠美
269秒
https://y.qq.com/n/yqq/song/0039MnYb0qxYhV.html
一路向北
J III MP3 Player
295秒
https://y.qq.com/n/yqq/song/001xd0HI0X9GNq.html
七里香
七里香
299秒
https://y.qq. 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5366
5366











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









