







参考链接:https://www.zhihu.com/question/19850365
1:MapReduce(MR),最为general和流行的一个分布式计算框架,其开源实现Hadoop已经得到了极为广泛的运用(Facebook, Yahoo!等等),同时在Hadoop基础上发展起来的项目也有很多(Hive是发展最好的),另外像Cloudera,Hortonworks,MapR这样的在Hadoop基础上发展起来的公司也有很多。
2:Pregel,和MR一样也是Google发明的,其优势是在完成一些适合于抽象为图算法的应用的计算时可以更为高效,Giraph可以算是一个比较好的发展中的开源实现。
3:Storm,Twitter的项目,号称Hadoop的实时计算平台,对于一些需要real time performance的job可以拥有比MR更高的效率。
4:Spark,UC Berkeley AMPLab的项目,其很好地利用了JVM中的heap,对于中间计算结果可以有更好的缓存支持,因此其在performance上要比MR高出很多。Shark是其基础上类似于Hive的一个项目。
下面稍微深入理解下MapReduce和Storm.
MapReduce:
MapReduce和HDFS是hadoop集群的代言词。hadoop集群的首要任务是执行计算,计算的框架便是MapReduce,HDFS是MapReduce的文件存储系统,MapReduce的输入和输出都是来自或者存储在HDFS。关于HDFS,请阅读这篇文章:http://blog.csdn.net/firehotest/article/details/69220280
Hadoop集群当中,不同的应用(如MapReduce、HDFS以及底层运作的ZooKeeper)的Master Node可以分布在不同的机器上。这样可以减轻负担。其中MapReduce的Master叫ResourceManagement Node(也叫Job Tracker),HDFS的Master叫NameNode,而ZooKeeper就是叫ZooKeeper Node。
下面内容与图片摘自:http://zheming.wang/blog/2015/05/19/3AFF5BE8-593C-4F76-A72A-6A40FB140D4D/
整个MapReduce的流程:
1)把输入的数据(input file)切分为若干独立的数据块(splits)
2)由 map任务(task)以完全并行的方式处理它们
3)对map的输出做一个 Shuffle and Sort 操作
4)对上述步骤的结果会输入给reduce任务
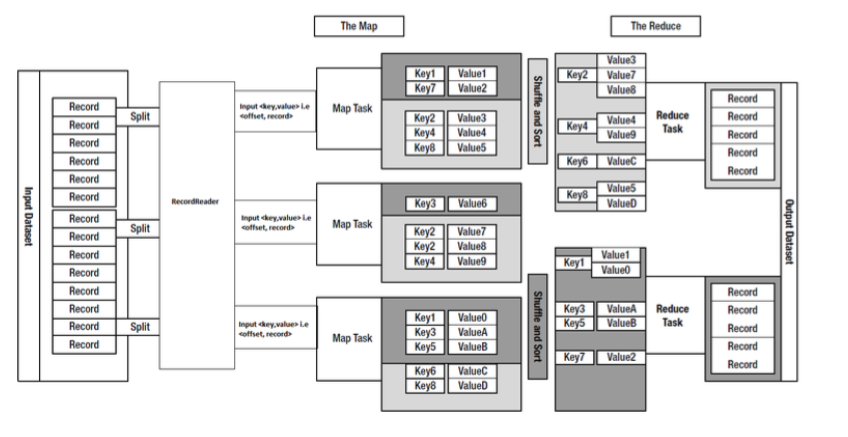
下面详述以上的4个步骤:
1)Input Files (对应上图的Records):Input file是map/reduce任务的原始数据,一般存储在HDFS上。应用程序至少应该指明输入/输出的位置(路径),并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置(job configuration)。
InputSplit是一个Mapper需要处理的数据块。通常一个split就是一个block,这样做的好处是使得Map任务可以在存储有当前数据的节点上运行本地的任务(在同一台机子执行Map任务),而不需要通过网络进行跨节点的任务调度。
通过参数调节,可以调整split的块的数目,进而调整Mapper的数目:
可以通过设置mapred.min.split.size, mapred.max.split.size, block.size来控制拆分的大小。如果mapred.min.split.size大于block size,则会将两个block合成到一个split,这样有部分block数据需要通过网络读取;如果mapred.max.split.size小于block size,则会将一个block拆成多个split,增加了Map任务数。
由于HDFS默认的Block Size是64MB,所以splitSize默认是64M。
一般的InputSplit是字节样式输出,然后由RecordReader处理并转化成记录样式。
2)Mapper
Mapper是一类将输入记录集转换为中间格式记录集的独立任务,主要是读取InputSplit的每一个Key,Value对并进行处理。如下图便是一个转换的例子:
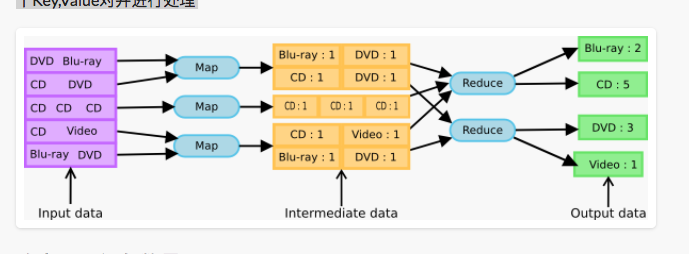
InputSplit再进过Record Reader的处理后,输出一行行的Record。例如:文本的例子便如上图所示。
经过Mapper之后,针对计算的目标转换为对应的Key - Value Pair。Mapper执行之前,需要进行相关的初始化(因为初始化的Tradeoff,所以,我们需要让每个Mapper的运行程序不少于1分钟,这样提高资源利用效率),流程化如下:
1) Mapper的实现者需要重写 JobConfigurable.configure(JobConf)方法,这个方法需要传递一个JobConf参数,目的是完成Mapper的初始化工作。
2) 对InputSplit中每个键值对调用一次 map(WritableComparable, Writable, OutputCollector, Reporter)操作。对应map方法的,在reducer端可以通过调用OutputCollector.collect(WritableComparable,Writable)可以收集map(WritableComparable, Writable, OutputCollector, Reporter)输出的键值对。MapReduce执行的程序可以通过Reporter报告进度,设定应用级别的状态消息,更新Counters(计数器),或者仅是表明自己运行正常。
注意,如上图所示,输入和输出的键值对不需要对应。map方法的意义便是根据计算目标,完成对应的KV对转换。
以 word count为例,输入不需要是“一行个单词”的形式,可以是一行许多个单词,输入一行可以对应多行输出。如下图所示:
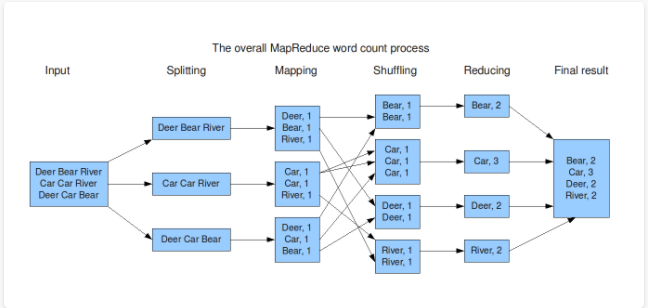
3)Shuffle & Sort:
Map/Reduce框架随后会把与一个特定key关联的所有中间过程的值(value) 分组 并 排序 这个分组和排序过程被称为Shuffle and Sort,然后把它们传给Reducer以产出最终的结果。分组的总数目和一个作业的reduce任务的数目是一样的。对于哪一组分给哪个reducer, 用户可以通过实现自定义的 Partitioner来控制哪个key被分配给哪个 Reducer。对于map的输出,用户可选择通过JobConf.setCombinerClass(Class)指定一个combiner,它负责对中间过程的输出进行本地的聚集,这会有助于降低从Mapper到 Reducer数据传输量。
对于Shuffle & Sort的输出,这些被排好序的中间过程的输出结果保存的格式是(key-len, key, value-len, value),应用程序可以通过JobConf控制对这些中间结果是否进行压缩以及怎么压缩,使用哪种CompressionCodec。
这部分的流程如下:
在把map()输出数据写入内存缓冲区之前会先进行Partitioner操作。(也就是说在Shuffle and Sort之前)Partitioner用于划分键值空间(key space)。MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。
Partitioner操作得到的分区元数据也会被存储到内存缓冲区中。当数据达到溢出的条件时(如:缓冲区满了),读取缓存中的数据和分区元数据,然后把属与同一分区的数据合并到一起。对于每一个分区,都会在内存中根据map输出的key进行排序(排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序),如果配置了Combiner,则排序后执行Combiner(Combine之后可以减少写入文件和传输的数据)。如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据。最后实现溢出的文件内是分区的,且分区内是有序的。
Partition --> Sort --> Combine --> Compress.
4)Reduce
简单地说,reduce任务在执行之前的工作就是不断地拉取每个map任务的最终结果,然后对从不同地方拉取过来的数据不断地做merge,也最终形成一个文件作为reduce任务的输入文件。如下图所示:
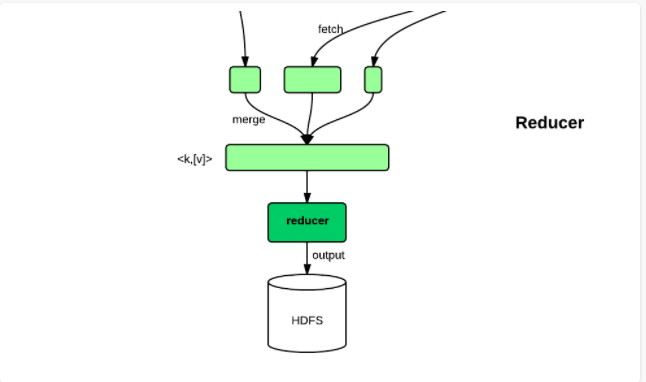
reduce的运行可以分成copy、merge、reduce三个阶段,下面将具体说明这3个阶段的详细执行流程。
Copy(最耗时的部分):
每个mapper的输出会根据用户自定义的partitioner或者系统默认的Partitioner进行分组。然而,无论是哪种Partitioner,分组的数目和Reducer的数量是一致的。
而每个mapper的中间结果中是有可能包含不同的reducer需要处理的部分数据的。所以,为了优化reduce的执行时间,hadoop中是等job的第一个mapper结束后,所有的reducer就开始尝试从完成的map中下载该reducer对应的partition部分数据,因此map和reduce是交叉进行的,如下图所示:
Merge:
Copy过来的数据会先放入内存缓冲区中,然后当使用内存达到一定量的时候才刷入磁盘。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。内存到内存的merge一般不适用,主要是内存到磁盘和磁盘到磁盘的merge。
Reduce:
当reduce将所有的map上对应自己partition的数据下载完成后,就会开始真正的reduce计算阶段。当reduce task真正进入reduce函数的计算阶段的时候。Reduce在这个阶段,框架为已分组的输入数据中的每个 <key, (list of values)>对调用一次 reduce(WritableComparable, Iterator, OutputCollector, Reporter)方法。 Reduce任务的输出通常是通过调用 OutputCollector.collect(WritableComparable, Writable)写入文件系统的。Reducer的输出是没有排序的。














 1736
1736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









