









1、网络爬虫库Scrapy
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据。Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便。Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
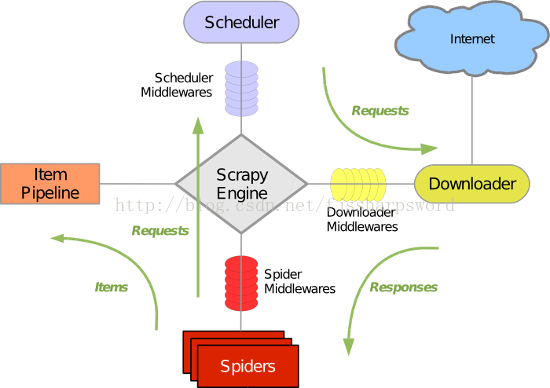
Scrapy主要包括了以下组件:
1)引擎,用来处理整个系统的数据流处理,触发事务。
2)调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
3)下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
4)蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
5)项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6)下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7)蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
8)调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
官方网站:http://scrapy.org/
开源地址:https://github.com/scrapy/scrapy
2、Scrapy安装
入门教程:http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据。Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便。Scrapy使用了Twisted异步网络库来处理网络通讯。整体架构大致如下:
Scrapy主要包括了以下组件:
1)引擎,用来处理整个系统的数据流处理,触发事务。
2)调度器,用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。
3)下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
4)蜘蛛,蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。
5)项目管道,负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
6)下载器中间件,位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。
7)蜘蛛中间件,介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。
8)调度中间件,介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
官方网站:http://scrapy.org/
开源地址:https://github.com/scrapy/scrapy
2、Scrapy安装
1)环境是 Anaconda ,conda package包可查看https://conda-forge.github.io/
scrapy可通过https://anaconda.org/conda-forge/scrapy下载安装包。
也可直接>conda install -c conda-forge scrapy安装
参考:https://doc.scrapy.org/en/latest/intro/install.html
有依赖库Twisted-17.1.0-cp27-cp27m-win_amd64.whl;
也可直接>pip install Scrapy安装(注意Scrapy大小写敏感)
安装指南:http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html#scrapy3、爬虫代码示例:
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://blog.scrapinghub.com']
def parse(self, response):
for title in response.css('h2.entry-title'):
yield {'title': title.css('a ::text').extract_first()}
for next_page in response.css('div.prev-post > a'):
yield response.follow(next_page, self.parse
入门教程:http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









